# Modellformulierung
library(MASS) # Multivariate Normalverteilung
set.seed(0) # Zufallzahlengeneratorseed
n = 12 # Anzahl von Datenpunkten
p = 1 # Anzahl von Betaparametern
X = matrix(rep(1,n), nrow = n) # Designmatrix
I_n = diag(n) # n x n Einheitsmatrix
beta = 2 # wahrer, aber unbekannter, Betaparameter
sigsqr = 1 # wahrer, aber unbekannter, Varianzparameter
# Datenrealisierung
y = mvrnorm(1, X %*% beta, sigsqr*I_n) # eine Realisierung eines n-dimensionalen ZVs36 Modellformulierung
36.1 Allgemeine Theorie
Wir definieren das Allgemeine Lineare Modell (ALM) wie folgt.
Definition 36.1 (Allgemeines Lineares Modell) Es sei \[ y = X\beta + \varepsilon \tag{36.1}\] wobei
- \(y\) ein \(n\)-dimensionaler beobachtbarer Zufallsvektor ist, der Daten genannt wird,
- \(X \in \mathbb{R}^{n \times p}\) für \(n>p\) und \(\mbox{rg}(X)=p\) eine Matrix ist, die Designmatrix genannt wird,
- \(\beta \in \mathbb{R}^{p}\) ein unbekannter Parametervektor ist, der Betaparametervektor genannt wird,
- \(\varepsilon\) ein \(n\)-dimensionaler nicht-beobachtbarer Zufallsvektor ist, der Zufallsfehler genannt wird und für den angenommen wird, dass mit einem unbekannten Varianzparameter \(\sigma^{2}>0\) gilt, dass \[\begin{equation} \varepsilon \sim N\left(0_{n}, \sigma^{2} I_{n}\right) \end{equation}\]
Dann heißt Gleichung 36.1 Allgemeines Lineares Modell (ALM).
In Gleichung 36.1 bezeichnen wir \(X\beta \in \mathbb{R}^{n}\) als den deterministischen Aspekt des ALMs und \(\varepsilon\) als den probabilistischen Aspekt des ALMs. Das ALM postuliert also, dass Daten aus der Addition eines deterministischen Aspektes \(X\beta \in \mathbb{R}^{n}\) unter der Addition eines multivariat normalverteilten probabilistischen Aspektes \(\varepsilon\) zustande kommen. Man beachte, dass \(X\beta \in \mathbb{R}^{n}\) ein \(n\)-dimensionaler Vektor und \(\varepsilon\) ein \(n\)-dimensionaler Zufallsvektor ist. Der resultierende Vektor \(y\) ist ein Zufallsvektor, weil er aus der Addition des Zufallsvektors \(\varepsilon\) zu dem Vektor \(X\beta \in \mathbb{R}^{n}\) resultiert. Das ALM ist also ein probabilitisches Modell bei dem durch \(y\) vorliegende Datensätze modelliert werden. Generativ betrachtet entsteht im ALM ein Datensatz \(y \in \mathbb{R}^{n}\) als Realisierung von \(y\) dann durch Addition des deterministischen Modellaspekts und einer nicht direkt beobachtbaren Realisierung \(e \in \mathbb{R}^{n}\) von \(\varepsilon\), \[\begin{equation} y=X\beta+e \end{equation}\] mit \(y \in \mathbb{R}^{n}, X\beta \in \mathbb{R}^{n}\) und \(e \in \mathbb{R}^{n}\).
Die Gesamtzahl an Parametern des ALMs beträt \(p+1\), bestehend aus \(p\) skalaren Betaparametern und einem Varianzparameter \(\sigma^{2}\). Der Betaparametervektor \(\beta \in \mathbb{R}^{p}\) wird dabei auch Gewichtsvektor oder Effektvektor genannt. Seine Einträge wichten die Einträge der Spalten der Designmatrix \(X \in \mathbb{R}^{n \times p}\) in der Erzeugung des deterministischen Modellaspekts \(X\beta \in \mathbb{R}^{n}\). Die Spalten der Designmatrix werden in unterschiedlichen Kontexten unterschiedlich bezeichnet, gebräuchliche Bezeichungen sind zum Beispiel Prädiktoren, Regressoren oder Kovariaten. Allgemein betrachtet modellieren die Spalten der Designmatrix unabhängige Variablen und der Datenvektor abhängige Variablen.
Man beachte, dass der Kovarianzmatrixparameter von \(\varepsilon\) als sphärisch angenommen wird. Damit folgt direkt, dass die \(\varepsilon_{1}, \ldots, \varepsilon_{n}\) unabhängige normalverteilte Zufallsvariablen mit identischem Varianzparameter sind. Weil für \(\varepsilon\) zusätzlich der Erwartungswertparameter als \(0_{n} \in \mathbb{R}^{n}\) angenommen wird, sind die \(\varepsilon_{1}, \ldots, \varepsilon_{n}\) auch identisch normalverteilte Zufallsvariablen. Wenn \(x_{ij} \in \mathbb{R}\) das \(ij\)te Element der Designmatrix \(X \in \mathbb{R}^{n \times p}\) bezeichnet, dann gilt damit für jede Komponente \(y_{i}, i=1, \ldots, n\) von \(y\) nach Gleichung 36.1, dass \[\begin{equation} y_{i} = x_{i 1}\beta_{1} + x_{i2}\beta_{2} + \cdots + x_{ip}\beta_{p} + \varepsilon_{i} \mbox{ mit } \varepsilon_{1},\ldots,\varepsilon_{n} \sim N\left(0, \sigma^{2}\right). \end{equation}\] Die in Gleichung 36.1 implizite Verteilung des Datenvektors \(y\) halten wir in folgendem Theorem fest.
Theorem 36.1 (Datenverteilung des Allgemeinen Linearen Modells) Es sei \[\begin{equation} y=X\beta+\varepsilon \mbox{ mit } \varepsilon \sim N\left(0_{n},\sigma^{2} I_{n}\right) \end{equation}\] das ALM. Dann gilt \[\begin{equation} y \sim N\left(\mu, \sigma^{2} I_{n}\right) \mbox{ mit } \mu:=X\beta \in \mathbb{R}^{n} \end{equation}\]
Beweis. Mit dem Theorem zur linear-affinen Transformation von multivariaten Normalverteilungen gilt für \[\begin{equation} \varepsilon \sim N\left(0_{n}, \sigma^{2} I_{n}\right) \mbox{ und } y := I_{n} \varepsilon + X\beta, \end{equation}\] dass \[\begin{equation} y \sim N\left(I_{n} 0_{n}+X\beta, I_{n}\left(\sigma^{2} I_{n}\right) I_{n}^{T}\right) = N\left(X\beta, \sigma^{2} I_{n}\right). \end{equation}\] Mit der Definition \(\mu:=X\beta \in \mathbb{R}^{n}\) folgt die Aussage des Theorems dann direkt.
Im ALM sind die Daten \(y\) also ein \(n\)-dimensionaler normalverteilter Zufallsvektor mit Erwartungswertparameter \(\mu=X\beta \in \mathbb{R}^{n}\) und Kovarianzmatrixparameter \(\sigma^{2} I_{n} \in \mathbb{R}^{n \times n}\). Das ALM ist also eine multivariate Normalverteilung deren Erwartungswertparameter mithilfe einer Designmatrix und eines Betaparametervektors parameterisiert ist. Weiterhin sind die Komponenten \(y_{1}, \ldots, y_{n}\) von \(y\), also die Zufallsvariablen, die skalare Datenpunkte modellieren, damit unabhängige normalverteilte Zufallsvariablen der Form \[\begin{equation} y_{i} \sim N\left((X\beta)_{i}, \sigma^{2}\right) \mbox{ für } i=1, \ldots, n. \end{equation}\] Da im Allgemeinen aber \((X\beta)_{i} \neq(X\beta)_{j}\) für \(i \neq j\) gilt, sind die \(y_{i}, i=1, \ldots, n\) im Allgemeinen aber nicht identisch verteilt. Das Szenario unabhängig und identisch normalverteilter Zufallsvariablen kann aber natürlich als Spezialfall des ALMs formuliert werden.
Beispiel (1) Unabhängige und identisch normalverteilte Zufallsvariablen
Wir betrachten das Szenario von \(n\) unabhängigen und identisch normalverteilten Zufallsvariablen mit Erwartungswertparameter \(\mu \in \mathbb{R}\) und Varianzparameter \(\sigma^{2}\), \[ y_{1}, \ldots, y_{n} \sim N\left(\mu, \sigma^{2}\right). \tag{36.2}\] Dann gilt, dass Gleichung 36.2 äquivalent ist zu \[\begin{equation} y_{i} = \mu+\varepsilon_{i}, \varepsilon_{i} \sim N\left(0, \sigma^{2}\right) \mbox{ für } i=1, \ldots, n \mbox{ mit unabhängigen } \varepsilon_{i}. \end{equation}\] In Matrixschreibweise ist dies wiederum äquivalent zu dem ALM Spezialfall \[\begin{equation} y \sim N\left(X\beta, \sigma^{2} I_{n}\right) \mbox{ mit } X:=1_{n} \in \mathbb{R}^{n \times 1}, \beta:=\mu \in \mathbb{R}^{1}, \sigma^{2}>0. \end{equation}\] In R können Realisierungen des ALMs leicht mithilfe eines Zufallszahlengenerators für multivariate Normalverteilungen durch Spezifikation der entsprechenden Erwartungs- und Kovarianzparameter gewonnen werden. Folgender R Code zeigt, wie \(n\) unabhängig und identisch normalverteilte skalare Datenpunkte im Sinne des ALMs realisiert werden können. Man beachte, dass \(n\) skalare Datenpunkte dabei einer Realisierung des ALMs entsprechen.
Realisierungen: 1.2 2.76 4.4 1.99 1.71 1.07 0.46 2.41 3.27 3.33 1.67 3.26Beispiel (2) Einfache lineare Regression
Wir betrachten das generative Modell der einfachen linearen Regression \[\begin{equation} y_{i}=\beta_{0}+\beta_{1} x_{i}+\varepsilon_{i}, \varepsilon_{i} \sim N\left(0, \sigma^{2}\right) \mbox{ für } i=1, \ldots, n \text {, } \end{equation}\] Wir haben bereits gesehen, dass dieses Modell äquivalent ist zu dem Normalverteilungsmodell der Regression \[\begin{equation} y_{i} \sim N\left(\mu_{i}, \sigma^{2}\right) \mbox{ mit } \mu_{i}:=\beta_{0}+\beta_{1} x_{i} \mbox{ für } i=1, \ldots, n. \end{equation}\] In Matrixschreibweise ist dies wiederum äquivalent zu dem ALM Spezialfall \[ y \sim N\left(X\beta, \sigma^{2} I_{n}\right) \mbox{ mit } X:=\left(\begin{array}{cc} 1 & x_{1} \\ 1 & x_{2} \\ \vdots & \vdots \\ 1 & x_{n} \end{array}\right) \in \mathbb{R}^{n \times 2}, \beta:=\left(\begin{array}{c} \beta_{0} \\ \beta_{1} \end{array}\right) \in \mathbb{R}^{2}, \sigma^{2}>0. \tag{36.3}\] R Code zur Simulation von Realisierungen einer einfachen linearen Regression hat dementsprechend eine sehr ähnliche Struktur wie obiger R Code zur Simulation von Realisierungen von \(n\) unabhängig und identisch normalverteilten Zufallsvariablen.
# Modellformulierung
library(MASS) # Multivariate Normalverteilung
set.seed(0) # Zufallzahlengeneratorseed
n = 10 # Anzahl von Datenpunkten
p = 2 # Anzahl von Betaparametern
x = 1:n # Prädiktorwerte
X = matrix(c(rep(1,n),x), nrow = n) # Designmatrix
I_n = diag(n) # n x n Einheitsmatrix
beta = matrix(c(0,1), nrow = p) # wahrer, aber unbekannter, Betaparameter
sigsqr = 1 # wahrer, aber unbekannter, Varianzparameter
# Datenrealisierung
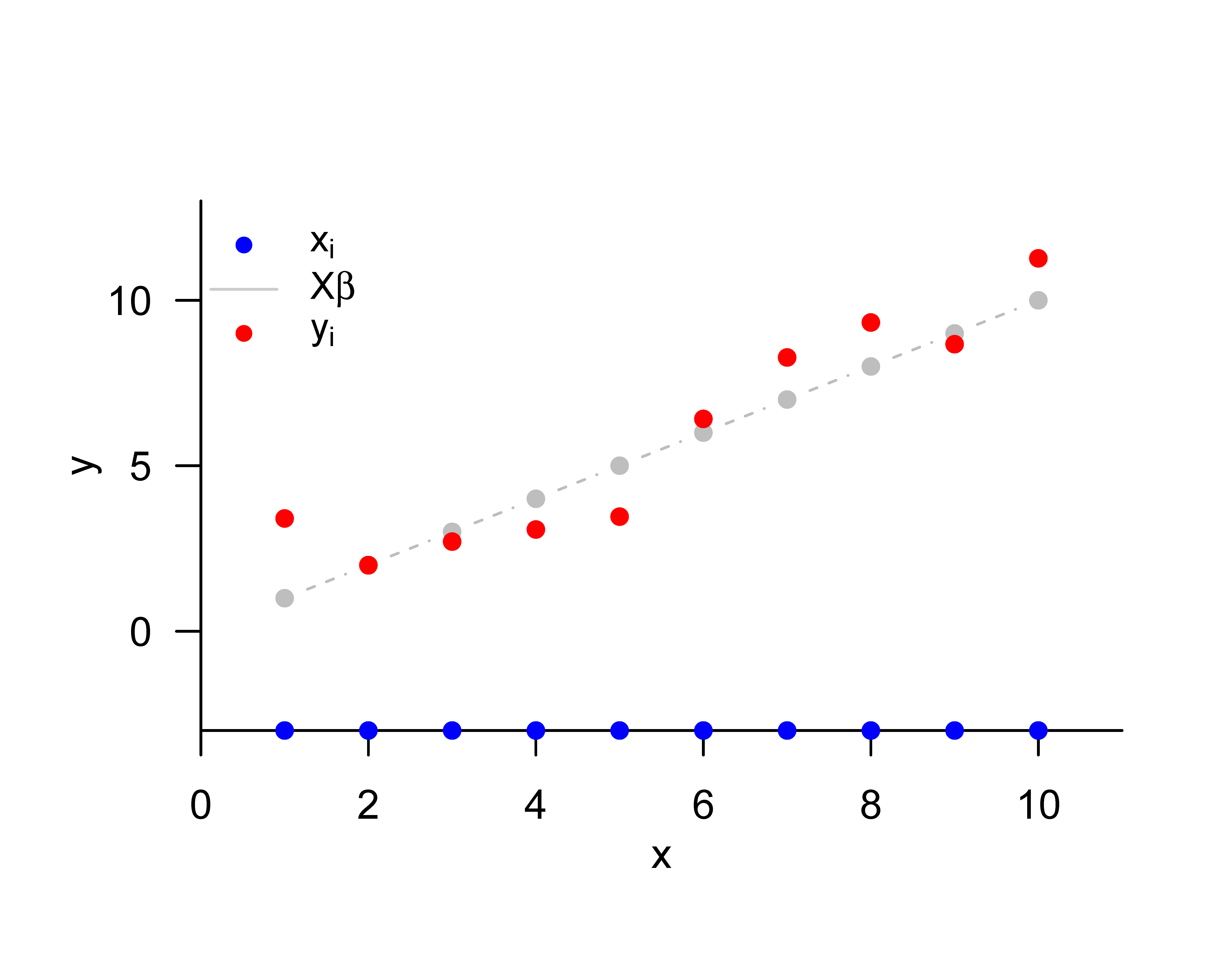
y = mvrnorm(1, X %*% beta, sigsqr*I_n) # eine Realisierung eines n-dimensionalen ZVsRealisierungen: 3.4 1.99 2.71 3.07 3.46 6.41 8.27 9.33 8.67 11.26Wir visualisieren obige Realisierung in Abbildung 36.1.
36.2 Identifizierbarkeit und Schätzbarkeit
Wir haben oben gesehen, dass die Datenverteilung des ALM durch \[\begin{equation} y \sim N\left(\mu, \sigma^{2} I_{n}\right) \mbox{ mit } \mu:=X\beta \in \mathbb{R}^{n} \mbox{ für } X \in \mathbb{R}^{n \times p}, \beta \in \mathbb{R}^{p} \end{equation}\] gegeben ist. Das ALM ist also eine multivariate Normalverteilung mit einer speziellen Erwartungswertparameterisierung. Um die Begriffe der Identifizierbarkeit und Schätzbarkeit im Kontext von ALMs einzuführen ist es hilfreich den Begriff der Parametrisierung einer multivariaten Normalverteilung zunächst etwas zu verallgemeinern.
Definition 36.2 (Betaparameterisieruhg) \(N\left(\mu, \sigma^{2} I_{n}\right)\) sei eine multivariate Normalverteilung mit sphärischem Kovarianzmatrixparameter. Dann bezeichnen wir eine multivariate, vektorwertige Funktion der Form \[\begin{equation} f: \mathbb{R}^{p} \rightarrow \mathbb{R}^{n}, \beta \mapsto f(\beta)=: \mu \end{equation}\] als eine Betaparametrisierung von \(\mu\).
Das ALM beruht offenbar auf der Designmatrix-abhängigen Betaparametrisierung \[\begin{equation} f: \mathbb{R}^{p} \rightarrow \mathbb{R}^{n}, \beta \mapsto f(\beta):=X\beta. \end{equation}\] Mit Hilfe des Begriffs der Betaparametrisierung können wir nun den Begriff der Betaparameteridentifizierbarkeit formulieren:
Definition 36.3 (Betaparameteridentifizierbarkeit) \(N\left(\mu, \sigma^{2} I_{n}\right)\) sei eine multivariate Normalverteilung mit sphärischem Kovarianzmatrixparameter und \(f\) sei eine Betaparametrisierung von \(\mu\). \(\beta\) heißt dann und nur dann identifizierbar, wenn für beliebige \(\beta_{1}, \beta_{2} \in \mathbb{R}^{p}\) gilt, dass aus \(f\left(\beta_{1}\right)=f\left(\beta_{2}\right)\) folgt, dass \(\beta_{1}=\beta_{2}\) gilt.
Die Betaparameter allgemeiner linearer Modelle, deren Designmatrix vollen Rang hat, sind identifizierbar. Dies ist die Aussage folgenden Theorems:
Theorem 36.2 (Betaparameteridentifizierbarkeit bei vollem Designmatrixrang) \(y \sim N\left(X\beta, \sigma^{2} I_{n}\right)\) sei die Datenverteilung eines ALMs mit \(\mbox{rg}(X)=p\). Dann ist \(\beta\) identifizierbar.
Beweis. Für \(X \in \mathbb{R}^{n \times p}\) impliziert \(\mbox{rg}(X)=p\), dass \(\left(X^{T} X\right) \in \mathbb{R}^{p \times p}\) eine invertierbare Matrix ist. Dann aber gilt für beliebige \(\beta_{1}, \beta_{2} \in \mathbb{R}^{p}\) \[\begin{equation} \begin{aligned} f\left(\beta_{1}\right) = f\left(\beta_{2}\right) & \Leftrightarrow X\beta_{1}=X\beta_{2} \\ & \Leftrightarrow X^{T} X\beta_{1}=X^{T} X\beta_{2} \\ & \Leftrightarrow\left(X^{T} X\right)^{-1} X^{T} X\beta_{1}=\left(X^{T} X\right)^{-1} X^{T} X\beta_{2} \\ & \Leftrightarrow \beta_{1}=\beta_{2}. \end{aligned} \end{equation}\]
Im Rahmen der Analyse schätzbarer Funktionen benötigen wir weiterhin den Begriff der Identifizierbarkeit von vektorwertigen Funktionen der Betaparameter. Wir definieren:
Definition 36.4 (Identifizierbarkeit von Funktionenen der Betaparameter) \(N\left(\mu, \sigma^{2} I_{n}\right)\) sei eine multivariate Normalverteilung mit sphärischem Kovarianzmatrixparameter und \(f\) sei eine Betaparametrisierung von \(\mu\). Weiterhin sei \[\begin{equation} g: \mathbb{R}^{p} \rightarrow \mathbb{R}^{k}, \beta \mapsto g(\beta) \end{equation}\] eine Funktion des Betaparametervektors. \(g\) heißt dann und nur dann identifizierbar, wenn für beliebige \(f\left(\beta_{1}\right), f\left(\beta_{2}\right) \in \mathbb{R}^{n}\) gilt, dass aus \(f\left(\beta_{1}\right)=f\left(\beta_{2}\right)\) folgt, dass \(g\left(\beta_{1}\right)=g\left(\beta_{2}\right)\).
Schätzbare Funktionen sind lineare Funktionen von \(\beta\), die identifizierbar sind. Allgemein gilt folgendes Theorem:
Theorem 36.3 (Identifizierbare Betaparameterfunktionen) \(N\left(\mu, \sigma^{2} I_{n}\right)\) sei eine multivariate Normalverteilung mit sphärischem Kovarianzmatrixparameter und \(f\) sei eine Betaparametrisierung von \(\mu\). Weiterhin sei \[\begin{equation} g: \mathbb{R}^{p} \rightarrow \mathbb{R}^{k}, \beta \mapsto g(\beta) \end{equation}\] eine Funktion des Betaparametervektors. Die Funktion \(g\) ist dann und nur dann identifizierbar, wenn \(g\) eine Funktion von \(f\) ist, wenn also eine Funktion \(\phi\) existiert, so dass \[\begin{equation} g = \phi \circ f \end{equation}\]
Beweis. Wir zeigen die Aussage lediglich in eine Richtung. \(\Rightarrow\) Wir nehmen an, es existiert eine Funktion \(\phi\), so dass \[\begin{equation} g=\phi \circ f . \end{equation}\] Dann impliziert die Tatsache, dass eine Funktion einem Argument genau einen Funktionswert zuordnet, dass gilt \[\begin{equation} f\left(\beta_{1}\right)=f\left(\beta_{2}\right) \Leftrightarrow \phi\left(f\left(\beta_{1}\right)\right)=\phi\left(f\left(\beta_{2}\right)\right) \Leftrightarrow g\left(\beta_{1}\right)=g\left(\beta_{2}\right) \end{equation}\] Also ist \(g\) identifizierbar, denn aus \(f\left(\beta_{1}\right)=f\left(\beta_{2}\right)\) folgt, dass \(g\left(\beta_{1}\right)=g\left(\beta_{2}\right)\).
Wie oben bereits erwähnt sind schätzbare Funktionen lineare Funktionen von \(\beta\), die identifizierbar sind. Die klassische Definition einer schätzbaren Funktion ist folgende.
Definition 36.5 (Schätzbare Funktion) \(N\left(X\beta, \sigma^{2} I_{n}\right)\) sei ein ALM. Dann heißt eine lineare Funktion \[\begin{equation} g: \mathbb{R}^{p} \rightarrow \mathbb{R}^{k}, \beta \mapsto g(\beta):=C^{T} \beta \end{equation}\] mit \(C \in \mathbb{R}^{p \times k}\) schätzbar, wenn eine Matrix \(P \in \mathbb{R}^{n \times k}\) existiert, so dass \[\begin{equation} C^{T} \beta=P^{T} X\beta. \end{equation}\]
Diese Definition erschließt sich wie folgt: Nach dem Theorem zu identifizierbaren Funktionen muss eine identifizierbare lineare Funktion von \(\beta\) eine Funktion der Form \[\begin{equation} g(\beta)=(\phi \circ f)(\beta) \end{equation}\] sein. Da weiterhin gilt, dass für ein ALM \(f(\beta)=X\beta\) und dass \(g\) eine lineare Funktion ist, also mithilfe einer Matrix \(C^{T}\) geschrieben werden kann, muss auch \(\phi\) eine lineare Funktion sein. Damit kann aber auch \(\phi\) geschrieben werden als \[\begin{equation} \phi(f(\beta))=\phi(X\beta)=P^{T} X\beta \end{equation}\] mit einer geeigneten Matrix \(P \in \mathbb{R}^{n \times k}\).
36.3 Designspektrum
Die Wahl von Designmatrix und Betaparameter öffnet eine große Freiheit zur Implementation verschiedenster Erwartungswertparameterszenarien der ALM Datenverteilung. Prinzipiell liegen dabei alle speziellen Designs in einem Kontinuum zwischen folgenden beiden Extrema:
- Die Erwartungswerte aller Datenvariablen sind identisch, d.h. \[\begin{equation} y_{i} \sim N\left(\mu, \sigma^{2}\right) \text { u.i.v. für } i=1, \ldots, n \end{equation}\] also \[\begin{equation} y=X\beta+\varepsilon \operatorname{mit} X:=1_{n} \in \mathbb{R}^{n \times 1}, \beta:=\mu \in \mathbb{R}, \varepsilon \sim N\left(0_{n}, \sigma^{2} I_{n}\right) . \end{equation}\]
- Die Erwartungswerte aller Datenvariablen sind paarweise verschieden, d.h. \[\begin{equation} y_{i} \sim N\left(\mu_{i}, \sigma^{2}\right) \text { u.v. für } i=1, \ldots, n \text {, } \end{equation}\] also \[\begin{equation} y=X\beta+\varepsilon \operatorname{mit} X:=I_{n} \in \mathbb{R}^{n \times n}, \beta:=\left(\mu_{1}, \ldots, \mu_{n}\right)^{T} \in \mathbb{R}^{n}, \varepsilon \sim N\left(0_{n}, \sigma^{2} I_{n}\right). \end{equation}\]
In Szenario (1) wird jegliche Datenvariabilität dem Zufallsfehlerterm zugeschrieben, in Szenario (2) wird dagegen jegliche Datenvariabilität dem Erwartungswertparameter zugeschrieben. Beide Extremszenarien sind wissenschaftlich nicht ergiebig, da sie keine theoriegeleitete systematische Abhängigkeit zwischen unabhängigen und abhängigen Variablen repräsentieren. Alle im weiteren Verlauf betrachteten ALM Designs liegen damit zwischen den beiden Extremszenarien und repräsentieren verschiedene Formen der systematischen Abhängigkeit zwischen unabhängigen und abhängigen Variablen. Insbesondere unterscheidet man
- Faktorielle Designs, bei denen die Designmatrix im Wesentlichen nur 1en und 0en und manchmal -1en enthält. In diesem Fall repräsentieren die Betaparameter Gruppenerwartungswerte und wir werden sehen, dass die Betaparameterschätzer in der Repräsentationen von Gruppenstichprobenmitteln resultieren. Man sagt manchmal, dass faktorielle Designs der Untersuchung von Unterschiedshypothesen dienen. Beispiele für faktorielle Designs sind verschiedene Designs zur Implementation von \(T\)-Tests und Varianzanalysen.
- Parameterische Designs, bei denen die Designmatrix aus Spalten mit kontinuierlichen reellen Werten besteht. Vor allem in diesem Kontext werden die Spalten der Designmatrix oft als Regressoren oder Prädiktoren bezeichnet. In diesem Fall repräsentieren die Betaparameter partielle Steigungsparameter und wir werden sehen, dass sich die entsprechenden Betaparameterschätzer als normalisierte Regressor-Daten Kovarianzen ergeben. Man sagt manchmal, dass parametrische Designs zur Untersuchung von Zusammenhangshypothesen dienen. Beispiele für parametrische Designs sind verschiedene Designs zur Implementation von einfacher linearer Regression und insbesondere multipler linearer Regression.
- Faktoriell-parametrische Designs, bei denen die Spalten der Designmatrix sowohl faktorielle als auch parametrische Prädiktoren repräsentieren. In diesem Kontext werden die parametrischen Regressoren oft als Kovariaten betrachtet. Gemischt faktoriell-parametrische Designs sind das zentrale Charakteristikum der Kovarianzanalyse die auf eine kontrollierte Untersuchung von Unterschiedshypothesen bei Vorliegen weiterer möglicher Abhängigkeiten zwischen unabhängigen und abhängigen Variablen bzw. auf die kontrollierte Untersuchung von Zusammenhangshypothesen bei Vorliegen weiterer möglicher Gruppenunterschiede abzielt.
36.4 Literaturhinweise
Das Allgemeine Lineare Modell hat eine lange Geschichte, deren moderne Inkarnation üblicherweise auf die Arbeiten von Legendre (1805) und Gauss (1809) zurückgeführt wird. Matrixbasierte Formulierungen der multiplen Regression finden sich spätestens bei Aitken (1936) und Scheffé (1959). Eingang in den psychologischen Methodenkanon findet das Allgemeine Lineare Modell spätestens mit Cohen (1968). Seal (1967) gibt einen ausführlichen Überblick zur Geschichte des Allgemeinen Linearen Modells im 19. und der ersten Hälfte des 20. Jahrhunderts. Die in diesem Abschnitt gegebene Diskussion von Identifizierbarkeit und Schätzbarkeit beruht auf der Darstellung in Christensen (2011).
Aitken, A. C. (1936). IV.—On Least Squares and Linear Combination of Observations. Proceedings of the Royal Society of Edinburgh, 55, 42–48. https://doi.org/10.1017/S0370164600014346
Christensen, R. (2011). Plane Answers to Complex Questions. Springer New York. https://doi.org/10.1007/978-1-4419-9816-3
Cohen, J. (1968). Multiple Regression as a General Data-Analytic System. Psychological Bulletin, 70(6, Pt.1), 426–443. https://doi.org/10.1037/h0026714
Gauss, C. F. (1809). Theoria Motus Corporum Coelestium in Sectionibus Conicis Solem Ambientium. Cambridge University Press.
Legendre, A. M. (1805). Nouvelles Methodes Pour La Determination Des Orbites Des Cometes. Didot Paris.
Scheffé, H. (1959). The Analysis of Variance (Wiley classics library ed). Wiley-Interscience Publication.
Seal, H. L. (1967). Studies in the History of Probability and Statistics. XV: The Historical Development of the Gauss Linear Model. Biometrika, 54(1/2), 1. https://doi.org/10.2307/2333849