In diesem Kapitel gehen wir im Sinne der in Kapitel 30 eingeführten Begrifflichkeiten immer von einem parametrischem Produktmodell \[\begin{equation}
\mathcal{M} := \{\mathcal{Y},\mathcal{A}, \{\mathbb{P}_\theta| \theta \in \Theta\}\}
\end{equation}\] mit \(n\)-dimensionalen Stichprobenraum (z.B. \(\mathcal{Y} := \mathbb{R}^n\)), \(d\)-dimensionalen Parameteraum \(\Theta \subset \mathbb{R}^d\) und gegebener WMF oder WDF \(p_\theta\) für alle \(\theta \in \Theta\) aus. \(y := (y_1,...,y_n)\) bezeichnet die zu \(\mathcal{M}\) gehörende Stichprobe unabhängig und identisch verteilter Zufallsvariablen, es gilt also durchgängig \[\begin{equation}
y_1,...,y_n \sim \mathbb{P}_\theta.
\end{equation}\] Wesen und Ziel der hier behandelten Punktschätzung ist es, basierend auf der Stichprobe einen möglichst guten Tipp für eine interessierende Kennzahl der Verteilung \(\mathbb{P}_\theta\) einer Stichprobenvariable anzugeben. Dabei ist der Tipp von der gleichen mathematischen Wesensart wie die entsprechende Kennzahl, also zum Beispiel ein skalarer Wert für einen skalaren Parameter. Dies ist nicht die einzige Möglichkeit der Schätzung, mit den Konfidenzintervallen werden wir in Kapitel 32 eine Möglichkeit der Schätzung von skalaren Werten durch Intervalle kennenlernen. Die zu schätzenden Kennzahlen von \(\mathbb{P}_\theta\) sind oft schlicht die wahren, aber unbekannten, Parameter selbst. Wir widmen uns diesem Fall ausführlich in Kapitel 31.1. Allerdings sind viele grundlegende Resultate der Frequentistischen Punktschätzung auch dann valide, wenn es sich bei zu schätzenden Kennzahlen nicht um die Parameter selbst, sondern Funktionen von ihnen handelt. Beispiel hierfür sind die Schätzung des Erwartungswerts, der Varianz oder der Standardabweichung von \(\mathbb{P}_\theta\). Beginnen wollen wir allerdings mit der Parameterschätzung. Um den wahren, aber unbekannten, Parameter eines Inferenzmodells zu schätzen, nutzt man in der Frequentistischen Inferenz sogenannte Parameterpunktschätzer.
Definition 31.1\(\mathcal{M} := (\mathcal{Y}, \mathcal{A}, \{\mathbb{P}_\theta|\theta \in \Theta\})\) sei ein Frequentistisches Inferenzmodell, \((\Theta,\mathcal{S})\) sei ein Messraum und \(\hat{\theta} : \mathcal{Y} \to \Theta\) sei eine Abbildung. Dann nennt man \(\hat{\theta}\) einen Parameterpunktschätzer für \(\theta\).
Parameterpunktschätzer werden meist auch einfach als Parameterschätzer bezeichnet. Im Sinne von Definition 30.3 sind Parameterpunktschätzer Schätzer mit \(\tau := \mbox{id}_\Theta\). Parameterpunktschätzer sind also Funktionen von Daten und nehmen Zahlwerte im Parameterraum an. Als Funktionen von Zufallsvariablen sind Parameterschätzer natürlich auch Zufallsvariablen. Oft wird dabei notationell nicht zwischen \(\hat{\theta}\) als Zufallsvariable und \(\hat{\theta}(y)\) als Wert dieser Zufallsvariable unterschieden.
Definition 31.1 macht offenbar keine Angabe darüber, wie ein Parameterpunktschätzer zu konstruieren ist oder inwieweit er dann ein sinnvoller Schätzer sein mag. Im Folgenden werden wir mit der Maximum-Likelihood-Schätzung zunächst ein allgemeines Prinzip diskutieren, das es erlaubt, für ein gegebenes Frequentistisches Inferenzmodell Parameterschätzer zu bestimmen, die, wie wir an späterer Stelle sehen werden, garantiert bestimmte wünschenswerte Eigenschaften haben (Kapitel 31.4). Dabei beziehen sich diese Eigenschaften allgemein auf sein qualitatives Verteilungsverhalten bei festem Stichprobenumfang bzw. im Grenzübergang zu einem unendlich großen Stichprobenumfang. Wir führen diese Eigenschaften in Kapitel 31.2 und Kapitel 31.3 ein.
31.1 Maximum-Likelihood-Schätzung
Die Grundidee der Maximum-Likelihood-Schätzung ist es, als Tipp für einen wahren, aber unbekannten, Parameterwert denjenigen Parameterwert zu wählen, für den die Wahrscheinlichkeit der beobachteten Daten maximal ist. Dafür ist es zunächst nötig, die Wahrscheinlichkeit beobachteter Daten eines Frequentistischen Inferenzmodells als Funktion des betreffenden Parameters zu betrachten. Dies ermöglichen und formalisieren die Likelihood-Funktion und ihr Logarithmus, die Log-Likelihood-Funktion. Wir definieren diese Begriffe hier für parametrische Produktmodelle.
Definition 31.2 (Likelihood-Funktion und Log-Likelihood-Funktion)\(\mathcal{M}\) sei ein parametrisches Produktmodell mit WMF oder WDF \(p_\theta\). Dann ist die Likelihood-Funktion definiert als \[\begin{equation}
L : \Theta \to [0,\infty[, \theta \mapsto L(\theta) := \prod_{i=1}^n p_\theta(y_i)
\end{equation}\] und die Log-Likelihood-Funktion ist definiert als \[\begin{equation}
\ell_n : \Theta \to \mathbb{R}, \theta \mapsto \ell(\theta) := \ln L(\theta).
\end{equation}\]
Die Likelihood-Funktion ist also eine Funktion des Parameters und ihre Funktionswerte sind die Werte der gemeinsamen WMF bzw. WDF beobachteter Datenwerte \(y_1,...,y_n\). Generell gibt es keinen Grund anzunehmen, dass eine Likelihood-Funktion über dem Parameterraum zu 1 integriert, die Likelihood-Funktion ist also im Allgemeinen keine WMF oder WDF. Die Log-Likelihood-Funktion ist schlicht die logarithmierte Likelihood-Funktion. Ein nach dem Prinzip der Maximum-Likelihood-Schätzung gewonnener Parameterschätzer soll nun die Likelihood-Funktion bzw. die Log-Likelihood-Funktion maximieren. Dies führt auf folgende Definition des Begriffs des Maximum-Likelihood Schätzers.
Definition 31.3 (Maximum-Likelihood-Schätzer)\(\mathcal{M}\) sei ein parametrisches Produktmodell mit Parameter \(\theta \in \Theta\). Ein Maximum-Likelihood-Schätzer von \(\theta\) ist definiert als \[\begin{equation}
\hat{\theta}^{\mbox{\tiny ML}} : \mathcal{Y} \to \Theta,
y \mapsto \hat{\theta}^{\mbox{\tiny ML}}(y)
:= \mbox{argmax}_{\theta \in \Theta} L(\theta)
= \mbox{argmax}_{\theta \in \Theta} \ell(\theta)
\end{equation}\]
Man beachte bei Definition 31.3, dass eine Maximumstelle der Log-Likelihood-Funktion der Maximumstelle der Likelihood-Funktion entspricht, weil die Logarithmusfunktion eine monoton steigende Funktion ist. Das Arbeiten mit der Log-Likelihood-Funktion ist allerdings oft einfacher als das direkte Arbeiten mit der Likelihood-Funktion, zum Beispiel, wenn in der WMF oder WDF des Modells Exponentialfunktionen auftauchen. Weiterhin beachte man bei Definition 31.3, dass Definition 31.2 impliziert, dass \[\begin{equation}
\hat{\theta}^{\mbox{\tiny ML}}(y)
= \mbox{argmax}_{\theta \in \Theta} \prod_{i=1}^n p_\theta(y_i)
= \mbox{argmax}_{\theta \in \Theta} \sum_{i=1}^n \ln p_\theta(y_i)
\end{equation}\] was die Abhängigkeit eines Maximum-Likelihood-Schätzers von den Daten verdeutlicht.
Mit Definition 31.3 handelt es sich bei der Maximum-Likelihood Schätzung also um das Problem, Extremalstellen einer Funktion zu bestimmen. Für diese Extremalstellen stellt die Differenzialrechnung bekanntlich notwendige und hinreichende Bedingungen bereit (vgl. Kapitel 6.2). In ihrer Anwendung auf die Gewinnung von Maximum-Likelihood-Schätzern begnügt man sich zumeist aufgrund der funktionellen Form der betrachteten Funktionen mit dem Erfülltsein der notwendigen Bedingung. Je nach Beschaffenheit der Log-Likelihood Funktion bieten sich dann Methoden der analytischen oder der numerischen Optimierung an. In den folgenden klassischen Beispielen nutzen wir einen analytischen Ansatz. Wir gehen dabei in folgenden Schritten vor:
Formulierung der Log-Likelihood-Funktion.
Bestimmung der ersten Ableitung der Log-Likelihood-Funktion und Nullsetzen.
Auflösen nach potenziellen Maximumstellen.
In Theorem 31.1 zeigen wir, dass der Maximum-Likelihood-Schätzer für den Parameter des Bernoullimodells aus Beispiel 30.2 durch das entsprechende Stichprobenmittel gegeben ist und in Theorem 31.2 zeigen wir, dass die Maximum-Likelihood-Schätzer für den Erwartungswert- und Varianzparameter des Normalverteilungsmodells aus Beispiel 30.1 durch das Stichprobenmittel und eine modifizierte Stichprobenvarianz, respektive, gegeben sind.
Beispiele
Theorem 31.1 (Maximum-Likelihood-Schätzer des Bernoullimodells)\(\mathcal{M}\) sei das Bernoullimodell, es gelte also \(y_1,...,y_n \sim \mbox{Bern}(\mu)\). Dann ist \[\begin{equation}
\hat{\mu}^{\mbox{\tiny ML}} : \{0,1\}^n \to [0,1],
y \mapsto \hat{\mu}^{\mbox{\tiny ML}}(y):= \frac{1}{n}\sum_{i=1}^n y_i
\end{equation}\] ein Maximum-Likelihood-Schätzer von \(\mu\)
Beweis. Wir formulieren zunächst die Log-Likelihood-Funktion. Für die Likelihood-Funktion gilt \[\begin{equation}
L: ]0,1[ \to ]0,1[,
\mu \mapsto L(\mu)
:= \prod_{i=1}^n \mu^{y_i}(1 - \mu)^{1-y_i}
= \mu^{\sum_{i=1}^n y_i}(1 - \mu)^{n - \sum_{i=1}^n y_i}.
\end{equation}\] Logarithmieren ergibt \[\begin{equation}
\ell: ]0,1[ \to \mathbb{R}, \mu \mapsto \ell(\mu)
= \ln \mu \sum_{i=1}^n y_i + \ln (1- \mu) \left(n - \sum_{i=1}^n y_i \right).
\end{equation}\] Wir werten dann die Ableitung der Log-Likelihood-Funktion aus. Es gilt \[\begin{align}
\begin{split}
\frac{d}{d\mu} \ell(\mu)
& = \frac{d}{d\mu}\left(\ln \mu \sum_{i=1}^n y_i + \ln (1- \mu) \left(n - \sum_{i=1}^n y_i \right)\right) \\
& = \frac{d}{d\mu} \ln \mu \sum_{i=1}^n y_i + \frac{d}{d\mu} \ln (1 - \mu) \left(n - \sum_{i=1}^n y_i \right) \\
& = \frac{1}{\mu}\sum_{i=1}^n y_i - \frac{1}{1-\mu} \left(n - \sum_{i=1}^n y_i \right).
\end{split}
\end{align}\] Nullsetzen ergibt dann folgende als notwendige Bedingung für einen Maximum-Likelihood-Schätzer im Bernoullimodell: \[\begin{equation}
\frac{1}{\hat{\mu}^{\mbox{\tiny ML}}}\sum_{i=1}^n y_i - \frac{1}{1-\hat{\mu}^{\mbox{\tiny ML}}} \left(n - \sum_{i=1}^n y_i \right) = 0.
\end{equation}\] Auflösen der Maximum-Likelihood-Gleichung nach \(\hat{\mu}^{\mbox{\tiny ML}}\) ergibt dann \[\begin{align}
\begin{split}
\frac{1}{\hat{\mu}^{\mbox{\tiny ML}}}\sum_{i=1}^n y_i - \frac{1}{1-\hat{\mu}^{\mbox{\tiny ML}}} \left(n - \sum_{i=1}^n y_i \right) & = 0 \\
\Leftrightarrow
\hat{\mu}^{\mbox{\tiny ML}}(1 - \hat{\mu}^{\mbox{\tiny ML}})\left(\frac{1}{\hat{\mu}^{\mbox{\tiny ML}}}\sum_{i=1}^n y_i - \frac{1}{1-\hat{\mu}^{\mbox{\tiny ML}}} \left(n - \sum_{i=1}^n y_i \right) \right) & = 0 \\
\Leftrightarrow
\sum_{i=1}^n y_i - \hat{\mu}^{\mbox{\tiny ML}} \sum_{i=1}^n y_i - n \hat{\mu}^{\mbox{\tiny ML}} + \hat{\mu}^{\mbox{\tiny ML}}\sum_{i=1}^n y_i & = 0 \\
\Leftrightarrow
n \hat{\mu}^{\mbox{\tiny ML}} & = \sum_{i=1}^n y_i \\
\Leftrightarrow
\hat{\mu}^{\mbox{\tiny ML}} & = \frac{1}{n} \sum_{i=1}^n y_i. \\
\end{split}
\end{align}\]\(\hat{\mu}^{\mbox{\tiny ML}} = \frac{1}{n}\sum_{i=1}^n y_i\) ist also ein Kandidat für einen Maximum-Likelihood-Schätzer von \(\mu\). Dies könnte durch Betrachten der zweiten Ableitung von \(\ell\) verifiziert werden, worauf wir hier aber verzichten wollen.
Theorem 31.2 (Maximum-Likelihood-Schätzer des Normalverteilungsmodells)\(\mathcal{M}\) sei das Normalverteilungsmodell, es gelte also \(y_1,...,y_n \sim N\left(\mu,\sigma^2\right)\). Dann sind \[\begin{equation}
\hat{\mu}^{\mbox{\tiny ML}} :
\mathbb{R}^n \to \mathbb{R}, y \mapsto \hat{\mu}^{\mbox{\tiny ML}}(y)
:= \frac{1}{n}\sum_{i=1}^n y_i
\end{equation}\] und \[\begin{equation}
\hat{\sigma}^{2^{\mbox{\tiny ML}}} :
\mathbb{R}^n \to \mathbb{R}_{\ge 0},
y \mapsto \hat{\sigma}^{2^{\mbox{\tiny ML}}}(y)
:= \frac{1}{n}\sum_{i=1}^n \left(y_i - \hat{\mu}^{\mbox{\tiny ML}}\right)^2.
\end{equation}\] Maximum-Likelihood-Schätzer für \(\mu\) und \(\sigma^2\), respektive.
Beweis. Wir formulieren zunächst die Log-Likelihood-Funktion. Für die Likelihood-Funktion ergibt sich \[\begin{align}
\begin{split}
L: \mathbb{R} \times \mathbb{R}_{>0} \to \mathbb{R}_{>0},
(\mu,\sigma^2) \mapsto L(\mu,\sigma^2)
:= & \prod_{i=1}^n \frac{1}{\sqrt{2\pi \sigma^2}}\exp\left(-\frac{1}{2\sigma^2}(y_i-\mu)^2\right) \\
= & \left(2 \pi \sigma^2\right)^{-\frac{n}{2}}\exp\left(-\frac{1}{2\sigma^2}\sum_{i=1}^n(y_i-\mu)^2\right). \\
\end{split}
\end{align}\] Logarithmieren ergibt dann \[\begin{equation}
\ell: \mathbb{R} \times \mathbb{R}_{>0} \to \mathbb{R},
(\mu,\sigma^2) \mapsto \mathcal{\ell}_n(\mu,\sigma^2)
= -\frac{n}{2} \ln 2\pi - \frac{n}{2} \ln \sigma^2-\frac{1}{2\sigma^2}\sum_{i=1}^n(y_i-\mu)^2.
\end{equation}\] Die Auswertung der partiellen Ableitungen der Log-Likelihood-Funktion ergeben dann \[\begin{equation}
\frac{\partial}{\partial{\mu}} \ell(\mu,\sigma^2)
= - \frac{\partial}{\partial{\mu}} \frac{1}{2\sigma^2}\sum_{i=1}^n(y_i-\mu)^2
= - \frac{1}{2\sigma^2}\sum_{i=1}^n \frac{\partial}{\partial{\mu}} (y_i-\mu)^2
= \frac{1}{\sigma^2}\sum_{i=1}^n (y_i-\mu)
\end{equation}\] und \[\begin{align}
\begin{split}
\frac{\partial}{\partial\sigma^2} \ell(\mu,\sigma^2)
= - \frac{n}{2} \frac{\partial}{\partial\sigma^2} \ln \sigma^2 - \frac{\partial}{\partial\sigma^2} \frac{1}{2\sigma^2}\sum_{i=1}^n(y_i-\mu)^2
= - \frac{n}{2 \sigma^2} + \frac{1}{2\sigma^4}\sum_{i=1}^n(y_i-\mu)^2.
\end{split}
\end{align}\] Das System der Maximum-Likelihood-Gleichungen als Ausdruck der notwendigen Bedingungen für Extremstellen der Log-Likelihood-Funktion hat in diesem Fall also die Form \[\begin{equation}
\sum_{i=1}^n (y_i-\hat{\mu}^{\mbox{\tiny ML}}) = 0
\mbox{ und }
- \frac{n}{2 \hat{\sigma}^{2^{\mbox{\tiny ML}}}} + \frac{1}{2\hat{\sigma}^{4^{\mbox{\tiny ML}}}}\sum_{i=1}^n(y_i-\mu)^2 = 0.
\end{equation}\] Lösen des Systems der Maximum-Likelihood-Gleichungen ergibt dann zunächst \[\begin{equation}
\sum_{i=1}^n (y_i-\hat{\mu}^{\mbox{\tiny ML}}) = 0
\Leftrightarrow \sum_{i=1}^n y_i = n\hat{\mu}^{\mbox{\tiny ML}}
\Leftrightarrow \hat{\mu}^{\mbox{\tiny ML}} = \frac{1}{n}\sum_{i=1}^n y_i.
\end{equation}\] Damit ist \[\begin{equation}
\hat{\mu}^{\mbox{\tiny ML}} = \frac{1}{n}\sum_{i=1}^n y_i
\end{equation}\] ein potenzieller Maximum-Likelihood-Schätzer von \(\mu\). Einsetzen dieses Schätzers in die zweite Maximum-Likelihood-Gleichung ergibt dann \[\begin{align}
\begin{split}
- \frac{n}{2 \hat{\sigma}^{2^{\mbox{\tiny ML}}}} + \frac{1}{2\hat{\sigma}^{4^{\mbox{\tiny ML}}}}\sum_{i=1}^n(y_i-\hat{\mu}^{\mbox{\tiny ML}})^2 & = 0 \\
\Leftrightarrow
- n\hat{\sigma}^{2^{\mbox{\tiny ML}}} + \sum_{i=1}^n(y_i-\hat{\mu}^{\mbox{\tiny ML}})^2 & = 0 \\
\Leftrightarrow
\hat{\sigma}^{2^{\mbox{\tiny ML}}} & = \frac{1}{n} \sum_{i=1}^n(y_i-\hat{\mu}^{\mbox{\tiny ML}})^2.
\end{split}
\end{align}\] Also ist \[\begin{equation}
\hat{\sigma}^{2^{\mbox{\tiny ML}}} = \frac{1}{n}\sum_{i=1}^n\left(y_i-\hat{\mu}^{\mbox{\tiny ML}}\right)^2
\end{equation}\] ein potenzieller Maximum-Likelihood-Schätzer von \(\sigma^2\). Beide potenziellen Maximum-Likelihood-Schätzer können durch Betrachten der zweiten Ableitung von \(\ell\) verifiziert werden, worauf wir hier verzichten wollen.
Man beachte bei Theorem 31.2, dass \(\hat{\mu}^{\mbox{\tiny ML}}\) mit dem Stichprobenmittel \(\bar{y}\) identisch ist, aber \(\hat{\sigma}^{2^{\mbox{\tiny ML}}}\) nicht mit der Stichprobenvarianz \(S^2\) übereinstimmt. Im Gegensatz zur Stichprobenvarianz findet sich im Maximum-Likelihood-Schätzer von \(\sigma^2\) der multiplikative Faktor \(\frac{1}{n}\), nicht, wie in der Stichprobenvarianz, der multiplikative Faktor \(\frac{1}{n-1}\). Wir werden auf diesen Unterschied im Kontext der Schätzereigenschaften zurückkommen.
Beispiel 31.3 (Anwendungsbeispiel) Zum Abschluss dieses Abschnitts wollen wir Theorem 31.2 im Kontext des Anwendungsbeispiels aus Beispiel 30.5 betrachten. Wir hatten dort den beobachteten dBDI Werten das Normalverteilungsmodell \[\begin{equation}
y_1,...,y_n \sim N(\mu,\sigma^2)
\end{equation}\] zugrundegelegt. Die Maximum-Likelihood-Schätzer für die Parameter dieses Modells lassen sich dann anhand von Theorem 31.2 mithilfe der R Stichprobenmittel- und Stichprobenvarianzfunktionen mean() und var() und unter Beachtung der Identität \[\begin{equation}
\frac{n-1}{n}s^2
= \frac{n-1}{n}\cdot\frac{1}{n-1}\sum_{i=1}^n (y_i - \bar{y})^2
= \frac{1}{n}\sum_{i=1}^n \left(y_i - \hat{\mu}^{\mbox{\tiny ML}}\right)^2
= \hat{\sigma}^{2^{\mbox{\tiny ML}}}
\end{equation}\] wie in folgendem R Code auswerten.
D =read.csv("./_data/bdi-ii-datensatz.csv") # Datensatzeinleseny = D$dBDI # Datenauswahlmu_hat =mean(y) # Maximum-Likelihood-Schätzung des Erwartungswertparametersn =length(y) # Anzahl der Datenpunktesigsqr_hat = ((n-1)/n)*var(y) # Maximum-Likelihood-Schätzung des Varianzparameterscat("mu_hat :", mu_hat,"\nsigsqr_hat :", sigsqr_hat) # Ausgabe
mu_hat : 3.166667
sigsqr_hat : 12.63889
Basierend auf dem Prinzip der Maximum-Likelihood-Schätzung und den vorliegenden \(n = 12\) Datenpunkten sind also \[\begin{equation}
\hat{\mu}^{\mbox{\tiny ML}} = 3.17
\mbox{ und }
\hat{\sigma}^{2^{\mbox{\tiny ML}}} = 12.6
\end{equation}\] Tipps für die wahren, aber unbekannten, Parameter des Modells.
31.2 Schätzereigenschaften bei endlichen Stichproben
Allgemein betreffen Frequentistische Schätzereigenschaften die Verteilung von Schätzern in Abhängigkeit der Verteilung der ihnen zugrundeliegenden Daten. Weil Daten in der Frequentistischen Inferenz zufällig sind, sind auch Schätzer zufällig. Speziell werden beobachtete Datenwerte als Realisierungen von Zufallsvariablen interpretiert. Schätzer als Funktionen von Zufallsvariablen sind damit auch Zufallsvariablen, auch wenn sie natürlich bei Vorliegen eines konkreten Datensatzes nur einen konkreten Wert annehmen. Wir unterscheiden zwischen Schätzereigenschaften bei endlichen Stichproben und Asymptotischen Schätzereigenschaften. Erstere sind Inhalt dieses Abschnittes und betreffen die Eigenschaften eines Schätzers für einen festen Stichprobenumfang \(n\), letztere sind Inhalt von Kapitel 31.3 und betreffen die Eigenschaften eines Schätzers im Grenzfall \(n \to \infty\) von großen Stichprobenumfängen.
Es sei zunächst \((\Sigma,S)\) ein Messraum und \(\hat{\tau} : \mathcal{Y} \to \Sigma\) ein Schätzer von \(\tau : \Theta \to \Sigma\) (vgl. Definition 30.3). In der Folge betrachten wir neben Parameterschätzern der Form \[\begin{equation}
\tau: \Theta \to \Sigma, \tau(\theta) := \theta
\end{equation}\] auch wiederholt solche Schätzer, die bei parametrischen Produktmodellen nur Funktionen der Parameter wie den Erwartungswert, die Varianz oder die Standardabweichung der Stichprobenvariablen schätzen. Da nach Annahme die Verteilungen der Stichprobenvariablen \(y_1,...,y_n\) identisch sind, handelt es sich dabei um Schätzer der Form \[\begin{align}
\begin{split}
\tau: \Theta \to \Sigma,\,
\theta \mapsto \tau(\theta)
\mbox{ mit }
\tau(\theta) := \mathbb{E}_\theta(y_1),
\tau(\theta) := \mathbb{V}_\theta(y_1) \mbox{ und }
\tau(\theta) := \mathbb{S}_\theta(y_1).
\end{split}
\end{align}\]
Speziell wollen wir in diesem Abschnitt vier Aspekte von Schätzereigenschaften bei endlichen Stichproben beleuchten. In Kapitel 31.2.1 beschäftigen wir uns zunächst mit der Erwartungstreue eines Schätzers. Dabei heißt ein Schätzer erwartungstreu, wenn sein Erwartungswert mit dem wahren, aber unbekannten, Wert \(\tau(\theta)\) für alle \(\theta \in \Theta\) identisch ist. In Kapitel 31.2.2 führen wir mit den Begriffen der Varianz und des Standardfehlers eines Schätzers zwei Maße für die Frequentistische Variabilität von Schätzern ein. Mit dem mittleren quadratischen Fehler eines Schätzers \(\hat{\tau}\) als Erwartungswert der quadrierten Abweichung von \(\hat{\tau}(y)\) von \(\tau(\theta)\) führen wir dann in Kapitel 31.2.3 eine Schätzereigenschaft ein, die es erlaubt, die Genauigkeit und die Variabilität eines Schätzers im Sinne eines sogenannten Bias-Variance-Tradeoffs miteinander in Beziehung zu setzen. Die in Kapitel 31.2.4 diskutierte Cramér-Rao-Ungleichung schließlich gibt eine untere Schranke für die Varianz erwartungstreuer Schätzer an. Ein erwartungstreuer Schätzer mit Varianz gleich der in der Cramér-Rao-Ungleichung gegebenen unteren Schranke hat die kleinstmögliche Varianz aller erwartungstreuen Schätzer und ist in diesem Sinne ein optimaler Schätzer.
31.2.1 Erwartungstreue
Der Begriff der Erwartungstreue eines Schätzers ergibt sich im Kontext des Fehlers und des systematischen Fehlers eines Schätzers wie folgt.
Definition 31.4 (Fehler, Systematischer Fehler und Erwartungstreue)\(y = (y_1,...,y_n)\) sei eine Stichprobe eines Frequentistischen Inferenzmodells und \(\hat{\tau}\) sei ein Schätzer für \(\tau\).
Der Fehler von \(\hat{\tau}\) ist definiert als \[\begin{equation}
\hat{\tau}(y) - \tau(\theta).
\end{equation}\]
Der systematische Fehler (engl. Bias) von \(\hat{\tau}\) ist definiert als \[\begin{equation}
\mbox{B}(\hat{\tau} ) := \mathbb{E}_{\theta}(\hat{\tau} (y)) - \tau(\theta).
\end{equation}\]
Der Schätzer \(\hat{\tau}\) heißt erwartungstreu (engl. unbiased), wenn \[\begin{equation}
\mbox{B}(\hat{\tau} ) = 0\Leftrightarrow
\mathbb{E}_{\theta}(\hat{\tau} (y)) = \tau(\theta) \mbox{ für alle } \theta \in \Theta \mbox{ und alle } n \in \mathbb{N}.
\end{equation}\] Andernfalls heißt \(\hat{\tau}\)verzerrt (engl. biased).
Man beachte, dass in Definition 31.4 der Fehler eines Schätzers von der spezifischen Realisation der Stichprobe \(y\) abhängt. Der systematische Fehler dagegen ist der erwartete Fehler über Stichprobenrealisationen und damit von einer spezifischen Realisation unabhängig. Für den speziellen Fall eines Parameterpunktschätzers gilt nach Definition 31.4, dass er erwartungstreu ist, wenn gilt, dass \[\begin{equation}
\mathbb{E}_{\theta}(\hat{\theta}) = \theta.
\end{equation}\]
Als erste Beispiele für erwartungstreue Schätzer betrachten wir in folgendem Theorem das Stichprobenmittel und die Stichprobenvarianz als Schätzer für den Erwartungswert und die Varianz einer Stichprobenvariable.
Theorem 31.3 (Erwartungstreue von Stichprobenmittel und Stichprobenvarianz)\(y := (y_1,...,y_n)\) sei die Stichprobe eines parametrischen Produktmodells. Dann gelten
Das Stichprobenmittel \[\begin{equation}
\bar{y} := \frac{1}{n}\sum_{i=1}^n y_i
\end{equation}\] ist ein erwartungstreuer Schätzer des Erwartungswerts \(\mathbb{E}_\theta(y_1)\).
Die Stichprobenvarianz \[\begin{equation}
S^2 := \frac{1}{n-1}\sum_{i=1}^n (y_i - \bar{y})^2
\end{equation}\] ist ein erwartungstreuer Schätzer der Varianz \(\mathbb{V}_\theta(y_1)\).
Beweis. (1) Die Erwartungstreue des Stichprobenmittels ergibt sich mit Theorem 23.2 aus \[\begin{align}
\mathbb{E}_\theta(\bar{y})
= \mathbb{E}_\theta \left(\frac{1}{n}\sum_{i=1}^n y_i \right)
= \frac{1}{n}\sum_{i=1}^n \mathbb{E}_\theta\left(y_i \right)
= \frac{1}{n}\sum_{i=1}^n \mathbb{E}_\theta\left(y_1 \right)
= \frac{1}{n} n \mathbb{E}_\theta\left(y_1 \right)
= \mathbb{E}_\theta\left(y_1 \right).
\end{align}\]
(2) Um die Erwartungstreue der Stichprobenvarianz zu zeigen, halten wir zunächst fest, dass mit Theorem 25.6 bei Unabhängigkeit der betrachteten Zufallsvariablen gilt, dass \[\begin{equation}
\mathbb{V}_\theta(\bar{y})
= \mathbb{V}_\theta\left(\frac{1}{n} \sum_{i=1}^n y_i \right)
= \frac{1}{n^2} \sum_{i=1}^n \mathbb{V}_\theta\left(y_i \right)
= \frac{1}{n^2} \sum_{i=1}^n \mathbb{V}_\theta\left(y_1 \right)
= \frac{1}{n^2} n \mathbb{V}_\theta\left(y_1 \right)
= \frac{\mathbb{V}_\theta\left(y_1 \right)}{n}.
\end{equation}\] Weiterhin gilt für den Term der summierten quadratischen Abweichungen in der Stichprobenvarianz, dass \[\begin{align}
\sum_{i=1}^n \left(y_i - \bar{y}\right)^2 = \sum_{i=1}^n (y_i - \mathbb{E}_\theta(y_1))^2 - n(\bar{y} - \mathbb{E}_\theta(y_1))^2,
\end{align}\] weil \[\begin{align}
\begin{split}
\sum_{i=1}^n \left(y_i - \bar{y}\right)^2
& = \sum_{i=1}^n \left(y_i - \mathbb{E}_\theta(y_1) - \bar{y} + \mathbb{E}_\theta(y_1) \right)^2 \\
& = \sum_{i=1}^n \left((y_i - \mathbb{E}_\theta(y_1)) - (\bar{y} - \mathbb{E}_\theta(y_1)) \right)^2 \\
& = \sum_{i=1}^n (y_i-\mathbb{E}_\theta(y_1))^2 - 2(\bar{y}-\mathbb{E}_\theta(y_1))\left(\sum_{i=1}^n(y_i-\mathbb{E}_\theta(y_1))\right) + \sum_{i=1}^n (\bar{y}-\mathbb{E}_\theta(y_1))^2 \\
& = \sum_{i=1}^n (y_i-\mathbb{E}_\theta(y_1))^2 - 2(\bar{y}-\mathbb{E}_\theta(y_1))\left(\sum_{i=1}^ny_i- n\mathbb{E}_\theta(y_1)\right) + n(\bar{y}-\mathbb{E}_\theta(y_1))^2 \\
& = \sum_{i=1}^n (y_i-\mathbb{E}_\theta(y_1))^2 - 2(\bar{y}-\mathbb{E}_\theta(y_1))\left(n\left(\frac{1}{n}\sum_{i=1}^ny_i\right)- n\mathbb{E}_\theta(y_1)\right) + n(\bar{y}-\mathbb{E}_\theta(y_1))^2 \\
& = \sum_{i=1}^n (y_i-\mathbb{E}_\theta(y_1))^2 - 2n(\bar{y}-\mathbb{E}_\theta(y_1))^2 + n(\bar{y}-\mathbb{E}_\theta(y_1))^2 \\
& = \sum_{i=1}^n (y_i - \mathbb{E}_\theta(y_1))^2 - n(\bar{y} - \mathbb{E}_\theta(y_1))^2.
\end{split}
\end{align}\] Zusammen ergibt sich also \[\begin{align}
\mathbb{E}_\theta\left((n-1)S^2\right)
& = \mathbb{E}_\theta\left(\sum_{i=1}^n \left(y_i - \bar{y}\right)^2 \right) \\
& = \mathbb{E}_\theta\left(\sum_{i=1}^n (y_i - \mathbb{E}_\theta(y_1))^2 - n(\bar{y} - \mathbb{E}_\theta(y_1))^2 \right) \\
& = \sum_{i=1}^n \mathbb{E}_\theta\left((y_i - \mathbb{E}_\theta(y_1))^2\right) - n \mathbb{E}_\theta\left((\bar{y} - \mathbb{E}_\theta(y_1))^2 \right) \\
& = n \mathbb{V}_\theta(y_1) - n \mathbb{V}_\theta(\bar{y}) \\
& = n \mathbb{V}_\theta(y_1) - n \frac{\mathbb{V}_\theta(y_1)}{n} \\
& = n \mathbb{V}_\theta(y_1) - \mathbb{V}_\theta(y_1) \\
& = (n - 1) \mathbb{V}_\theta(y_1).
\end{align}\] Schließlich ergibt sich dann \[\begin{equation}
\mathbb{E}_\theta\left(S^2\right)
= \mathbb{E}_\theta\left(\frac{1}{n-1}(n-1)S^2 \right)
= \frac{1}{n-1}\mathbb{E}_\theta\left((n-1)S^2 \right)
= \frac{1}{n-1}(n - 1) \mathbb{V}_\theta(y_1)
= \mathbb{V}_\theta(y_1)
\end{equation}\] und damit die Erwartungstreue der Stichprobenvarianz als Schätzer der Varianz.
Natürlich sind in Theorem 31.3 aufgrund der identischen Verteilung der Stichprobenvariablen eines parametrischen Produktmodells das Stichprobenmittel und die Stichprobenvarianz auch erwartungstreue Schätzer des Erwartungswertes und der Varianz einer beliebigen Stichprobenvariablen \(y_i\) mit \(1 \le i \le n\). Man beachte, dass im Beweis der Erwartungstreue der Stichprobenvarianz der Nenner \(n-1\) in der Definition der Stichprobenvarianz eine entscheidende Rolle spielt.
Obwohl die Stichprobenvarianz ein unverzerrter Schätzer der Varianz einer Stichprobenvariable eines parametrischen Produktmodells ist, trifft dies auf die Stichprobenstandardabweichung als Schätzer der Standardabweichung nicht zu. Dies ist Inhalt des folgenden Theorems.
Theorem 31.4 (Verzerrtheit der Stichprobenstandardabweichung)\(y = (y_1,...,y_n)\) sei die Stichprobe eines parametrischen Produktmodells. Dann ist die Stichprobenstandard- abweichung \[\begin{equation}
S := \sqrt{S^2}
\end{equation}\] ein verzerrter Schätzer der Standardabweichung \(\mathbb{S}_\theta(y_1)\).
Beweis. Wir halten zunächst fest, dass \(\sqrt{\cdot}\) eine strikt konkave Funktion und \(\sigma^2 > 0\) ist. Dann aber gilt mit der Jensenschen Ungleichung \(\mathbb{E}(f(\xi)) < f(\mathbb{E}(\xi))\) für strikt konkave Funktionen (vgl. Theorem 26.5), dass \[\begin{equation}
\mathbb{E}_\theta(S)
= \mathbb{E}_\theta\left(\sqrt{S^2}\right)
< \sqrt{\mathbb{E}_\theta(S^2)}
= \sqrt{\mathbb{V}_\theta(y_1)}
= \mathbb{S}_\theta(y_1).
\end{equation}\]
Allgemein führen nicht-lineare Transformationen von erwartungstreuen Schätzern oft auf verzerrte Schätzer, was wir hier aber nicht weiter vertiefen wollen.
Beispiel 31.1 (Simulationsbeispiel) Folgender R Code demonstriert exemplarisch die Begriffe der Unverzerrtheit und Verzerrtheit von Stichprobenmittel, Stichprobenvarianz und Stichprobenstandardabweichung am Beispiel eines parametrischen Produktmodells mit Stichprobenverteilung \[\begin{equation}
y_1,...,y_{12} \sim N(1.7,2)
\end{equation}\] Dabei werden die Erwartungswerte der Schätzer anhand ihrer Stichprobenmittel über viele Realisierungen von \(y_1,...,y_{12}\) als Funktion der Anzahl an Realisierungen (Simulationen) geschätzt.
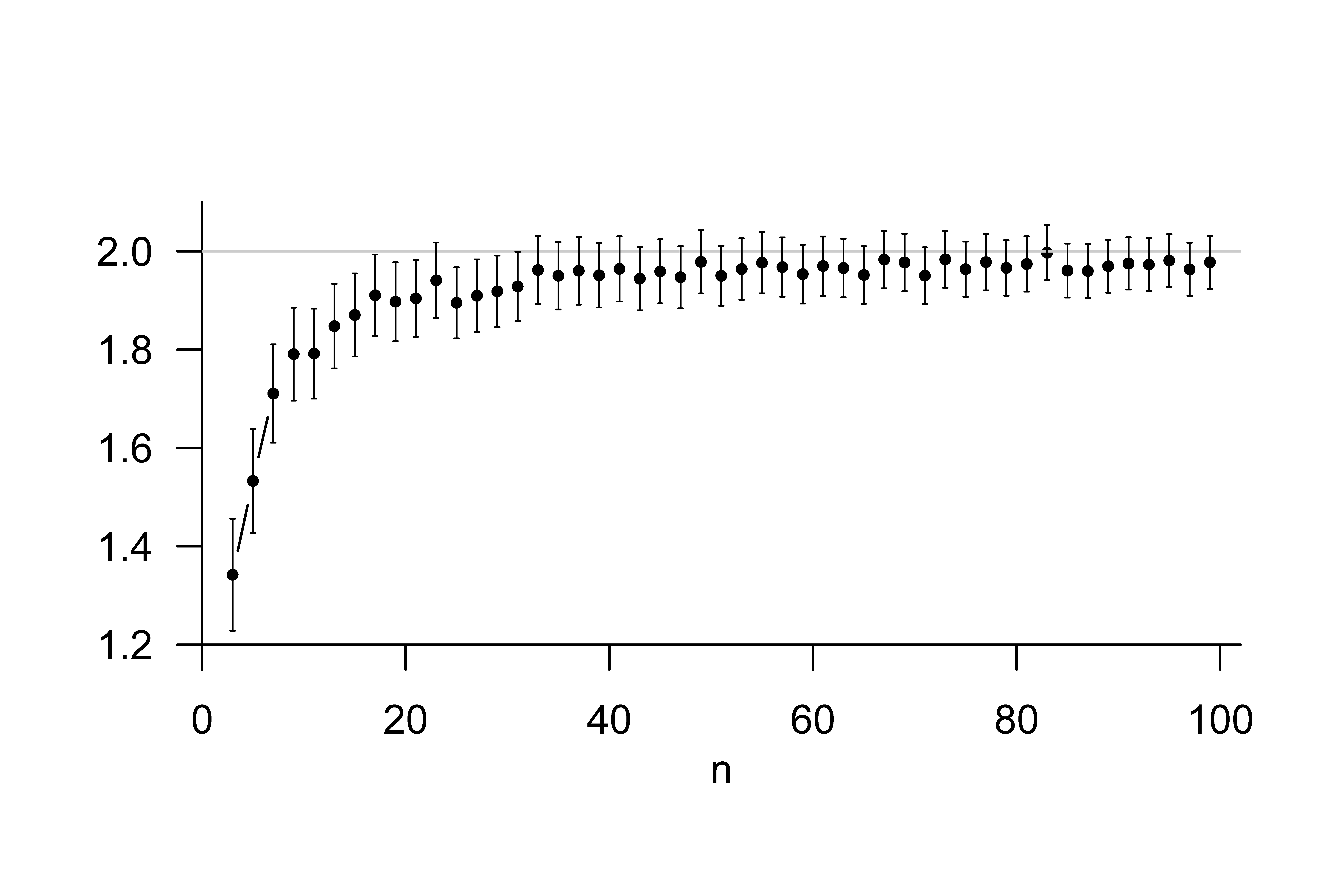
Abbildung 31.1 visualisiert die Ergebnisse obiger Simulation. Gezeigt sind Schätzungen der Erwartungswerte von Stichprobenmittel, Stichprobenvarianz und Stichprobenstandardabweichung als Funktion der Anzahl an Realisierungen der Stichprobenvariablen \(y_1,...,y_{12}\) sowie die wahren, aber unbekannten, Werte des Erwartungswerts, der Varianz und der Standardabweichung der \(y_1,...,y_{12}\). Es fällt auf, dass diese Schätzungen bei geringer Realisierungsanzahl variabler ausfallen. Ab einer Schätzung basierend auf etwa 10.000 Realisierungen von \(y_1,...,y_{12}\) entsprechen die Stichprobenmittel von \(\bar{y}\) und \(S^2\) gemäß ihrer Erwartungstreue ihren wahren, aber unbekannten, Werten. Die Stichprobenstandardabweichung dagegen zeigt gemäß ihrer Verzerrtheit auch bei weiter ansteigenden Anzahlen von der Realisierungen von \(y_1,...,y_{12}\) konstant eine zu niedrige Schätzung der wahren, aber unbekannten, Standardabweichung.
Abbildung 31.1: Simulation der Erwartungstreue von Stichprobenmittel und Stichprobenvarianz als Schätzer des Erwartungswerts und der Varianz bei normalverteilten Stichprobenvariablen und Simulation der Verzerrtheit der Stichprobenstandardabweichung als Schätzer der Standardabweichung bei normalverteilten Stichprobenvariablen
31.2.2 Varianz und Standardfehler
Im vorherigen Abschnitt haben wir den Erwartungswert eines Schätzers betrachtet. In diesem Abschnitt betrachten wir seine Varianz und seine Standardabweichung. Wir nutzen folgende Definition.
Definition 31.5 (Varianz und Standardfehler)\(y = (y_1,...,y_n)\) sei die Stichprobe eines Frequentistischen Inferenzmodells und \(\hat{\tau}\) sei ein Schätzer von \(\tau\).
Die Varianz von \(\hat{\tau}\) ist definiert als \[\begin{equation}
\mathbb{V}_\theta(\hat{\tau} ) :=
\mathbb{E}_\theta
\left((\hat{\tau} (y) - \mathbb{E}_\theta(\hat{\tau} (y)))^2\right).
\end{equation}\]
Der Standardfehler von \(\hat{\tau}\) ist definiert als \[\begin{equation}
\mbox{SE}(\hat{\tau} ) := \sqrt{\mathbb{V}_\theta(\hat{\tau})}.
\end{equation}\]
Die Varianz eines Schätzers \(\hat{\tau}\) ist also als die Varianz der Zufallsvariable \(\hat{\tau}(y)\) definiert. Der Standardfehler eines Schätzers \(\hat{\tau}\) ist als die Standardabweichung von \(\hat{\tau}(y)\) definiert. Als erstes Beispiel für einen Standardfehler betrachten wir den Standardfehler des Stichprobenmittels.
Theorem 31.5 (Standardfehler des Stichprobenmittels)\(y = (y_1,...,y_n)\) sei die Stichprobe eines parametrischen Produktmodells. Dann ist der gegeben durch \[\begin{equation}
\mbox{SE}(\bar{y}) = \frac{\mathbb{S}_\theta(y_1)}{\sqrt{n}}.
\end{equation}\].
Beweis. Mit der Varianz des Stichprobenmittels ergibt sich \[\begin{equation}
\mbox{SE}(\bar{y})
= \sqrt{\mathbb{V}_\theta(\bar{y})}
= \sqrt{\frac{\mathbb{V}_\theta(y_1)}{n}}
= \frac{\mathbb{S}_\theta(y_1)}{\sqrt{n}}.
\end{equation}\]
Der Standardfehler des Mittelwerts beschreibt die Variabilität des Stichprobenmittels. Da die Standardabweichung \(\mathbb{S}_\theta(y_1)\) unbekannt ist, ist auch der Standardfehler \(\mbox{SE}(\bar{y})\) unbekannt, kann also nur geschätzt werden. Mit der Stichprobenstandardabweichung als verzerrtem Schätzer der Standardabweichung \(\mathbb{S}_\theta(y_1)\) ergibt sich ein ebenfalls verzerrter Schätzer für den Standardfehler des Stichprobenmittels als \[\begin{equation}
\hat{\mbox{SE}}(\bar{y}) = \frac{S}{\sqrt{n}}.
\end{equation}\]
Als zweites Beispiel wollen wir den Standardfehler des Maximum-Likelihood-Schätzers für den Parameter eines Bernoulli-Modells betrachten.
Theorem 31.6 (Standardfehler des Maximum-Likelihood-Schätzers des Bernoullimodellparameters)\(y = (y_1,...,y_n)\) sei die Stichprobe eines Bernoullimodells und \(\hat{\mu}^{\mbox{\tiny ML}}\) sei der Maximum-Likelihood-Schätzer für den Bernoullimodellparameter \(\mu\). Dann ist der Standardfehler von \(\hat{\mu}^{\mbox{\tiny ML}}\) gegeben durch \[\begin{equation}
\mbox{SE}\left(\hat{\mu}^{\mbox{\tiny ML}}\right) = \sqrt{\frac{\mu(1-\mu)}{n}}.
\end{equation}\]
Beweis. Es gilt \[\begin{align}
\begin{split}
\mbox{SE}\left(\hat{\mu}^{\mbox{\tiny ML}}\right)
= \sqrt{\mathbb{V}_\mu\left(\hat{\mu}^{\mbox{\tiny ML}}\right)}
= \sqrt{\mathbb{V}_\mu\left(\frac{1}{n}\sum_{i=1}^n y_i \right)}
= \sqrt{\frac{1}{n^2}\sum_{i=1}^n \mathbb{V}_\mu(y_i)}
= \sqrt{\frac{n \mu(1-\mu)}{n^2}}
= \sqrt{\frac{\mu(1-\mu)}{n}},
\end{split}
\end{align}\] wobei die dritte Gleichung mit der Unabhängigkeit der \(y_i\) und die vierte Gleichung mit der Varianz \[\begin{equation}
\mathbb{V}_\mu(y_1) = \mathbb{V}_\mu(y_i) = \mu(1-\mu)
\end{equation}\] der Stichprobenvariablen folgt.
Wie im Falle des Standardfehlers des Stichprobenmittels ist auch der Standardfehler des Maximum-Likelihood-Schätzers des Bernoullimodellparameters ein wahrer, aber unbekannter, Wert. Ein Schätzer für \(\mbox{SE}\left(\hat{\mu}^{\mbox{\tiny ML}}\right)\) ergibt sich mit dem Maximum-Likelihood-Schätzer für den Bernoullimodellparameter durch \[\begin{equation}
\hat{\mbox{SE}}\left(\hat{\mu}^{\mbox{\tiny ML}}\right)
= \sqrt{\frac{\hat{\mu}^{\mbox{\tiny ML}}(1-\hat{\mu}^{\mbox{\tiny ML}})}{n}}.
\end{equation}\]
Beispiel 31.2 (Simulationsbeispiel) Folgender R Code simuliert die Verteilung des Maximum-Likelihood-Schätzers für den Parameter eines Bernoullimodells mit wahrem, aber unbekanntem, Parameterwert \(\mu := 0.4\) für die Stichprobenumfänge \(n = 20, n = 100\) und \(n = 200\). Abbildung 31.2 visualisiert die resultierenden Verteilungen mithilfe von Histogrammen. Die Variabilität der Schätzwerte, also die Breite der Histogrammverteilungen, hängt dabei offenbar vom Stichprobenumfang ab. Höhere Stichprobenumfänge resultieren in einer geringeren Variabilität des Schätzers. Diesen Gedanken werden wir in Kapitel 31.3 vertiefen.
# Modellformulierungmu =0.4# wahrer, aber unbekannter, Parameterwertn_all =c(20,100,200) # Stichprobenumfänge nns =1e4# Anzahl der Simulationenmu_hat =matrix(rep(NaN, length(n_all)*ns), nrow =length(n_all)) # Maximum-Likelihood-Schätzerarray# Stichprobenumfängeiterationenfor(i inseq_along(n_all)){# Simulationsiterationenfor(s in1:ns){ y =rbinom(n_all[i],1,mu) # Stichprobenrealisation von y_1,...,y_n mu_hat[i,s] =mean(y) # Stichprobenmittel }}
Abbildung 31.2: Simulation der Verteilung des Maximum-Likelihood-Schätzers eines Bernoullimodells. Die Variabilität des Schätzers hängt dabei offenbar vom Stichprobenumfang \(n\) ab.
31.2.3 Mittlerer quadratischer Fehler
Mit der Erwartungstreue und der Varianz eines Schätzers haben wir in den beiden vorherigen Abschnitten zwei unabhängige Kriterien für die Güte von Schätzern kennengelernt. Der in diesem Abschnitt eingeführte Mittlere quadratische Fehler eines Schätzers ermöglicht eine integrierte Betrachtung der Genauigkeit (Erwartungstreue) und Variabilität (Varianz) eines Schätzers im Sinne seiner sogenannten Bias-Varianz-Zerlegung. Wir definieren den mittleren quadratischen Fehler eines Schätzers zunächst wie folgt.
Definition 31.6 (Mittlerer quadratischer Fehler)\(y = (y_1,...,y_n)\) sei die Stichprobe eines parametrischen Produktmodells und \(\hat{\tau}\) ein Schätzer für \(\tau\). Dann ist der mittlere quadratischer Fehler (engl. mean squared error) von \(\hat{\tau}\) definiert als \[\begin{equation}
\mbox{MQF}(\hat{\tau})
:= \mathbb{E}_\theta\left((\hat{\tau}(y) - \tau(\theta))^2\right).
\end{equation}\]
Der mittlere quadratische Fehler von \(\hat{\tau}\) ist also die erwartete quadrierte Abweichung von \(\hat{\tau}(y)\) von \(\tau(\theta)\). Man beachte, dass in Abgrenzung dazu die Varianz von \(\hat{\tau}\) die erwartete quadrierte Abweichung von \(\hat{\tau}\) von \(\mathbb{E}_\theta(\hat{\tau}(y))\) ist. Dabei kann, wie in Kapitel 31.2.1 gesehen \(\mathbb{E}_\theta(\hat{\tau}(y))\) mit \(\tau(\theta)\) übereinstimmen, ein Schätzer also erwartungstreu sein, er muss es aber nicht. Nutzt man den mittleren quadratischen Fehler als Gütekriterium für einen Schätzer, zum Beispiel indem man versucht, einen Schätzer mit möglichst geringem mittleren quadratischen Fehler zu konstruieren, so kann man dabei eventuelle leichte Abweichungen von der Erwartungstreue zugunsten einer geringen Schätzervarianz in Kauf nehmen. Für den mittleren quadratischen Fehler gilt nämlich folgendes Theorem.
Theorem 31.7 (Zerlegung des mittleren quadratischen Fehlers)\(y = (y_1,...,y_n)\) sei die Stichprobe eines parametrischen Produktmodells, \(\hat{\tau}\) sei ein Schätzer für \(\tau\), und \(\mbox{MQF}(\hat{\tau})\) sei der mittlere quadratische Fehler von \(\hat{\tau}\). Dann gilt \[\begin{equation}
\mbox{MQF}(\hat{\tau}) = \mbox{B}(\hat{\tau})^2 + \mathbb{V}_\theta(\hat{\tau}).
\end{equation}\]
Hat man mehrere erwartungstreue Schätzer vorliegen, so gilt, dass derjenige Schätzer mit der kleinsten Varianz am verlässlichsten seinen Zweck erfüllt. Weil aber die Stichprobenrealisierungen Frequentistischer Inferenzmodelle in aller Regel variabel sind, kann auch die Variabilität erwartungstreuer Schätzer nicht beliebig klein sein. Die Cramér-Rao-Ungleichung gibt eine untere Schranke für die Varianz erwartungstreuer Schätzer an. Ein erwartungstreuer Schätzer mit Varianz gleich dieser unteren Schranke hat damit die kleinstmögliche Varianz aller erwartungstreuer Schätzer und ist - in diesem Sinne - ein optimaler Schätzer.
Die Cramér-Rao-Ungleichung basiert auf dem Begriff der sogenannten Fisher-Information, welche wiederum auf dem Begriff der Scorefunktion eines Frequentistischen Inferenzmodells beruht. Wir führen im Folgenden also zunächst diese beiden Begrifflichkeiten ein, bevor die Cramér-Rao-Ungleichung formuliert und bewiesen werden soll.
Dabei gelten die vorgestellten Resultate allgemein nur unter einer Reihe mathematischer Annahmen, den sogenannten Fisher-Regularitätsbedingungen. Diese bestehen für ein Frequentistisches Inferenzmodell mit WMF oder WDF \(p_\theta\) und Parameterraum \(\Theta\) darin, dass angenommen wird, dass (1) \(\Theta\) eine offene Menge ist, der wahre, aber unbekannte, Parameterwert damit nicht an einer Parameterraumgrenze liegen kann, (2) die Teilmenge von \(\Theta\), auf der \(p_\theta\) von null verschiedene Werte annimmt, nicht von \(\theta\) abhängt, (3) das Modell selbst identifizierbar ist, dass also WMFen oder WDFen mit unterschiedlichen Parameterwerten unterschiedliche Funktionen sind und damit unterschiedliche Stichprobenverteilungen implizieren, (4) die Likelihood-Funktion des Modells zweimal stetig differenzierbar und (5) dass für die Likelihood-Funktion Integration und Differentiation vertauscht werden dürfen. Wir setzen die Fisher-Regularitätsbedingungen also als erfüllt voraus und wollen nur Modelle mit eindimensionalem Parameterräumen \(\Theta \subseteq \mathbb{R}\) betrachten. Wir definieren zunächst die Begriffe der Scorefunktion und der Fisher-Information wie folgt.
Definition 31.7 (Scorefunktion und Fisher-Information)\(y = (y_1,...,y_n)\) sei die Stichprobe eines parametrischen Produktmodells mit eindimensionalem Parameter \(\theta \in \Theta \subseteq \mathbb{R}\) und \(\ell\) sei die zugehörige Log-Likelihood-Funktion. Dann gelten:
Die erste Ableitung von \(\ell\) wird Scorefunktion der Stichprobe genannt und wird mit \[\begin{equation}
S(\theta) := \frac{d}{d\theta}\ell(\theta)
\end{equation}\] bezeichnet. Für \(n = 1\) schreiben wir \(S(\theta) := S_1(\theta)\) und nennen \(S(\theta)\)Scorefunktion einer Zufallsvariable.
Die negative zweite Ableitung von \(\ell\) wird Fisher-Information der Stichprobe genannt und mit \[\begin{equation}
I(\theta) := -\frac{d^2}{d\theta^2}\ell(\theta)
\end{equation}\] bezeichnet. Für \(n = 1\) schreiben wir \(I(\theta) := I_1(\theta)\) und nennen \(I(\theta)\) die Fisher-Information einer Zufallsvariable.
Da Likelihood- und Log-Likelihood-Funktionen von der Realisierung einer Stichprobe abhängen, sind sie vor dem Hintergrund eines Frequentistischen Inferenzmodells zufällige Funktionen. Da die Fisher-Information als Funktion der Log-Likelihood-Funktion damit auch eine Zufallsvariable ist, muss man zwischen den beobachteten und den erwarteten Werten der Fisher-Information unterscheiden.
Definition 31.8 (Beobachtete und erwartete Fisher-Information)\(y = (y_1,...,y_n)\) sei die Stichprobe eines parametrischen Produktmodells mit eindimensionalem Parameter \(\theta \in \Theta \subseteq \mathbb{R}\), \(\ell\) sei die zugehörige Log-Likelihood-Funktion und \(\hat{\theta}^{\mbox{\tiny ML}}\) sei ein Maximum-Likelihood-Schätzer von \(\theta\). Dann gelten:
Die beobachtete Fisher-Information der Stichprobe ist definiert als \[\begin{equation}
I\left(\hat{\theta}^{\mbox{\tiny ML}}\right)
:= -\frac{d^2}{d\theta^2}\ell\left(\hat{\theta}^{\mbox{\tiny ML}}\right),
\end{equation}\] die beobachtete Fisher-Information der Stichprobe ist also die Fisher-Information an der Stelle des Maximum-Likelihood-Schätzers \(\hat{\theta}^{\mbox{\tiny ML}}\).
Die erwartete Fisher-Information der Stichprobe ist definiert als \[\begin{equation}
J(\theta) := \mathbb{E}_\theta(I(\theta)).
\end{equation}\] Für \(n = 1\) schreiben wir \(J(\theta) := J_1(\theta)\) und nennen \(J(\theta)\) die
Bevor wir diese Begrifflichkeiten anhand des Bernoullimodells (Theorem 31.10) und des Normalverteilungsmodells (Theorem 31.12 und Theorem 31.11) verdeutlichen wollen, führen wir mit der Additivität der Fisher-Information bei parametrischen Produktmodellen (Theorem 31.8) und dem Erwartungswert und der Varianz der Scorefunktion (Theorem 31.9) noch wichtige Eigenschaften der genannten Begriffe ein, die die folgende Diskussion vereinfachen.
Theorem 31.8 (Additivität der Fisher-Information)\(y = (y_1,...,y_n)\) sei die Stichprobe eines parametrischen Produktmodells mit Parameter \(\theta \in \Theta \subseteq \mathbb{R}\), \(\ell\) sei die zugehörige Log-Likelihood-Funktion und \(I(\theta)\) und \(J(\theta)\) seien die Fisher-Information und die erwartete Fisher-Information der Stichprobe, respektive. Dann gilt \[\begin{equation}
I(\theta) = nI_1(\theta) \mbox{ und } J(\theta) = nJ_1(\theta).
\end{equation}\]
Beweis. Wir zeigen das Resultat für die erwartete Fisher-Information, das Resultat für die beobachtete Fisher-Information gilt dann implizit. Mit der Linearität von Ableitungen und Erwartungswerten gilt \[\begin{align}
\begin{split}
J(\theta)
& = \mathbb{E}_\theta\left(-\frac{d^2}{d\theta^2} \ell(\theta)\right) \\
& = \mathbb{E}_\theta\left(-\frac{d^2}{d\theta^2} \ln \left(\prod_{i=1}^n p_\theta(y_i)\right)\right) \\
& = \mathbb{E}_\theta\left(-\frac{d^2}{d\theta^2} \sum_{i=1}^n \ln p_\theta(y_i)\right) \\
& = \mathbb{E}_\theta\left(-\frac{d^2}{d\theta^2} \sum_{i=1}^n \ln p_\theta(y_1)\right) \\
& = \mathbb{E}_\theta\left(-\frac{d^2}{d\theta^2} \ell_1(\theta)n\right) \\
& = n \mathbb{E}_\theta\left(-\frac{d^2}{d\theta^2}\ell_1(\theta))\right) \\
& = n J(\theta).
\end{split}
\end{align}\]
Nach Theorem 31.8 genügt es zur Berechnung der beobachteten oder erwarteten Fisher-Information einer Stichprobe bei parametrischen Produktmodellen also, die beobachtete oder erwartete Fisher-Information einer der Zufallsvariablen der Stichprobe zu berechnen. Weitere Vereinfachungen in der Bestimmung von Fisher-Informationen und der Begründung der Cramér-Rao-Ungleichung ergeben sich durch die im folgenden Theorem formulierten Identitäten.
Theorem 31.9 (Erwartungswert und Varianz der Scorefunktion) Der Erwartungswert der Scorefunktion einer Zufallsvariable ist \[\begin{equation}
\mathbb{E}_\theta(S(\theta)) = 0
\end{equation}\] und die Varianz der Scorefunktion einer Zufallsvariable ist \[\begin{equation}
\mathbb{V}_\theta(S(\theta)) = J(\theta).
\end{equation}\]
Beweis. Wir betrachten nur den Fall, dass \(p_\theta\) eine WDF ist und zeigen zunächst, dass \(\mathbb{E}_\theta(S(\theta)) = 0\) ist. \[\begin{align}
\begin{split}
\mathbb{E}_\theta(S(\theta))
& = \int S(\theta)p_\theta(x) \,dx \\
& = \int \frac{d}{d\theta}\ell(\theta)p_\theta(x) \,dx \\
& = \int \frac{d}{d\theta} \ln L(\theta) p_\theta(x) \,dx \\
& = \int \frac{1}{L(\theta)}\frac{d}{d\theta}L(\theta) p_\theta(x) \,dx \\
& = \int \frac{1}{p_\theta(x)}\frac{d}{d\theta}L(\theta) p_\theta(x) \,dx \\
& = \int \frac{d}{d\theta}L(\theta) \,dx \\
& = \frac{d}{d\theta} \int p_\theta(x)\,dx \\
& = \frac{d}{d\theta} 1 \\
& = 0.
\end{split}
\end{align}\] Mit der Definition der Varianz folgt dann sofort, dass \(\mathbb{V}_\theta(S(\theta)) = \mathbb{E}_\theta(S(\theta)^2)\) ist. Als Nächstes zeigen wir, dass \(J(\theta) = \mathbb{E}_\theta(S(\theta)^2)\) und deshalb \(\mathbb{V}_\theta(S(\theta)) = J(\theta)\) ist. \[\begin{align}
\begin{split}
J(\theta)
& = \mathbb{E}_\theta\left(-\frac{d^2}{d\theta^2} \ln L(\theta)\right) \\
& = \mathbb{E}_\theta\left(-\frac{d}{d\theta} \frac{\frac{d}{d\theta}L(\theta)}{L(\theta)}\right) \\
& = \mathbb{E}_\theta\left(-\frac{\frac{d^2}{d\theta^2} L(\theta) L(\theta) - \frac{d}{d\theta}L(\theta)\frac{d}{d\theta}L(\theta)}{L(\theta)L(\theta)}\right) \\
& = - \mathbb{E}_\theta\left(\frac{\frac{d^2}{d\theta^2} L(\theta)}{L(\theta)}\right) +
\mathbb{E}_\theta\left(\frac{\left(\frac{d}{d\theta}L(\theta)\right)^2}{(L(\theta))^2}\right) \\
& = - \int \frac{\frac{d^2}{d\theta^2} L(\theta)}{L(\theta)} p_\theta(x) \,dx +
\int \frac{\left(\frac{d}{d\theta}L(\theta)\right)^2}{(L(\theta))^2} p_\theta(x) \,dx \\
& = - \frac{d^2}{d\theta^2} \int p_\theta(x) \,dx +
\int \left(\frac{1}{L(\theta)}\frac{d}{d\theta}L(\theta)\right)^2 p_\theta(x) \,dx \\
& = - \frac{d^2}{d\theta^2} 1 +
\int \left(\frac{d}{d\theta} \ln L(\theta) \right)^2 p_\theta(x) \,dx \\
& = \mathbb{E}_\theta\left(S(\theta)^2\right).
\end{split}
\end{align}\]
Der Erwartungswert der Ableitung der Log-Likelihood-Funktion ist also immer Null und die erwartete Fisher-Information ist immer gleich der Varianz der Scorefunktion. Wir wollen die Scorefunktion und die verschiedenen Formen der Fisher-Information nun für die uns vertrauten Frequentistischen Inferenzmodelle konkret berechnen. Nachfolgendes Theorem fasst zunächst die Ergebnisse für das Bernoullimodell zusammen.
Theorem 31.10 (Scorefunktion und Fisher-Informationen des Bernoullimodells) Es sei \(y = (y_1,...,y_n)\) die Stichprobe eines Bernoullimodells mit Parameter \(\mu \in ]0,1[\). Dann gelten:
Die Scorefunktion der Stichprobe ist \[\begin{equation}
S : ]0,1[ \to \mathbb{R}, \mu \mapsto S(\mu) := \frac{1}{\mu}\sum_{i=1}^n y_i - \frac{1}{1-\mu} \left(n - \sum_{i=1}^n y_i \right).
\end{equation}\]
Die Fisher-Information der Stichprobe ist \[\begin{equation}
I : ]0,1[ \to \mathbb{R}, \mu \mapsto I(\mu) := I(\mu) = \frac{ny}{\mu^2} + \frac{n(1 - y)}{1-\mu}^{2}.
\end{equation}\]
Die beobachtete Fisher-Information der Stichprobe ist \[\begin{equation}
I: ]0,1[ \to \mathbb{R}, \hat{\mu}^{\mbox{\tiny ML}} \mapsto
I\left(\hat{\mu}^{\mbox{\tiny ML}}\right)
:= \frac{ny}{\hat{\mu}_{n}^{{\mbox{\tiny ML}}^2}} + \frac{n(1 - y)}{1-\hat{\mu}^{\mbox{\tiny ML}}}.
\end{equation}\]
Die erwartete Fisher-Information der Stichprobe ist \[\begin{equation}
J: ]0,1[ \to \mathbb{R}, \mu \mapsto J(\mu)
:= \frac{n}{\mu(1-\mu)}.
\end{equation}\]
Beweis. Die Scorefunktion wurde bereits im Kontext der Maximum-Likelihood-Schätzung von \(\mu\) hergeleitet. Wir betrachten die Fisher-Information einer einzelnen Bernoulli-Zufallsvariable \(y\). \[\begin{align}
\begin{split}
I(\mu)
& := -\frac{d^2}{d\mu^2} \ell_1(\mu) \\
& = -\frac{d^2}{d\mu^2} \ln p_\mu(y) \\
& = -\frac{d^2}{d\mu^2}\left(y \ln \mu + (1 - y) \ln (1-\mu)\right) \\
& = -\frac{\partial}{\partial{\mu}}\left(\frac{\partial}{\partial{\mu}}\left(y \ln \mu + (1 - y) \ln (1-\mu)\right)\right) \\
& = -\frac{\partial}{\partial{\mu}}\left(\frac{y}{\mu} + \frac{(1 - y)}{1-\mu}\right) \\
& = -\left(-\frac{y}{\mu^2} - \frac{(1 - y)}{1-\mu}^{2}\right) \\
& = \frac{y}{\mu^2} + \frac{(1 - y)}{1-\mu}^{2}. \\
\end{split}
\end{align}\] Damit ergibt sich die erwartete Fisher-Information der Zufallsvariable \(y\) als \[\begin{align}
\begin{split}
J(\mu)
& = \mathbb{E}_\mu(I(\mu)) \\
& = \mathbb{E}_\mu \left(\frac{y}{\mu^2} + \frac{(1 - y)}{1-\mu}^{2} \right) \\
& = \frac{\mathbb{E}_\mu(y)}{\mu^2} + \frac{(1 - \mathbb{E}_\mu(y))}{1-\mu}^{2} \\
& = \frac{\mu}{\mu^2} + \frac{(1 - \mu)}{1-\mu}^{2} \\
& = \frac{1}{\mu(1-\mu)}. \\
\end{split}
\end{align}\] Mit der Additivitätseigenschaft der Fisher-Information und der Definition der beobachteten Fisher-Information ergibt sich dann sofort \[\begin{equation}
I(\mu)
= \frac{ny}{\mu^2} + \frac{n(1 - y)}{1-\mu}^{2}
\mbox{ und }
J(\mu) = \frac{n}{\mu(1-\mu)}.
\end{equation}\]
Die Scorefunktion und die Fisher-Informationen des Normalverteilungsmodells betrachten wir lediglich unter der zusätzlichen Annahme eines bekannten Varianzparameters (Theorem 31.11) bzw. eines bekannten Erwartungswertparameters (Theorem 31.12)
Theorem 31.11 (Scorefunktion und Fisher-Informationen des Normalverteilungsmodells bei bekanntem Varianzparameter)\(y = (y_1,...,y_n)\) sei die Stichprobe eines Normalverteilungsmodells und der Varianzparameter \(\sigma^2\) sei als bekannt vorausgesetzt. Dann gelten:
Die Scorefunktion der Stichprobe ist \[\begin{equation}
S: \mathbb{R} \to \mathbb{R}, \mu \mapsto S(\mu) := \frac{1}{\sigma^2}\sum_{i=1}^n(y_i-\mu).
\end{equation}\]
Die Fisher-Information der Stichprobe ist \[\begin{equation}
I: \mathbb{R} \to \mathbb{R}, \mu \mapsto I(\mu) := \frac{n}{\sigma^2}.
\end{equation}\]
Die beobachtete Fisher-Information der Stichprobe ist \[\begin{equation}
I(\hat{\mu}^{\mbox{\tiny ML}}_n) = \frac{n}{\sigma^2}.
\end{equation}\]
Die erwartete Fisher-Information der Stichprobe ist \[\begin{equation}
J : \mathbb{R} \to \mathbb{R}, \mu \mapsto J(\mu) := \frac{n}{\sigma^2}.
\end{equation}\]
Beweis. Wir erinnern uns, dass die Log-Likelihood-Funktion eines Normalverteilungsmodells bei bekanntem Varianzparameter \(\sigma^2\) durch \[\begin{equation}
\ell: \mathbb{R} \to \mathbb{R},
\mu \mapsto \ell(\mu)
:= -\frac{n}{2} \ln 2\pi - \frac{n}{2} \ln \sigma^2 - \frac{1}{2\sigma^2}\sum_{i=1}^n(y_i-\mu)^2
\end{equation}\] gegeben ist. Damit ergibt sich die Scorefunktion als \[\begin{align}
\begin{split}
S(\mu)
= \frac{\partial}{\partial{\mu}}\ell(\mu)
= \frac{1}{\sigma^2}\sum_{i=1}^n(y_i-\mu)
\end{split}
\end{align}\] Die Fisher-Information der Stichprobe ergibt sich als \[\begin{align}
\begin{split}
I(\mu)
= -\frac{d^2}{d\mu^2}\ell(\mu)
= -\frac{\partial}{\partial{\mu}}S(\mu)
= -\frac{1}{\sigma^2}\frac{\partial}{\partial{\mu}}\left(\sum_{i=1}^n y_i - n\mu \right)
= \frac{n}{\sigma^2}.
\end{split}
\end{align}\] Die beobachtete Fisher-Information ist die Fisher-Information an der Stelle des Maximum-Likelihood-Schätzers \(\hat{\mu}^{\mbox{\tiny ML}}_n\). Die erwartete Fisher-Information schließlich ergibt sich als \[\begin{align}
\begin{split}
J(\mu)
= \mathbb{E}_\mu(I(\mu))
= \mathbb{E}_\mu\left(\frac{n}{\sigma^2}\right)
= \frac{n}{\sigma^2}.
\end{split}
\end{align}\]
Theorem 31.12 (Scorefunktion und Fisher-Informationen des Normalverteilungsmodells bei bekanntem Erwartungswertparameter)\(y = (y_1,...,y_n)\) sei die Stichprobe eines Normalverteilungsmodells und der Varianzparameter \(\sigma^2\) sei als bekannt vorausgesetzt. Dann gelten:
Die Scorefunktion der Stichprobe ist gegeben durch \[\begin{equation}
S: \mathbb{R}_{>0} \to \mathbb{R}, \sigma^2 \mapsto S(\sigma^2) := - \frac{n}{2 \sigma^2} + \frac{1}{2\sigma^4}\sum_{i=1}^n(y_i-\mu)^2
\end{equation}\]
Die Fisher-Information der Stichprobe ist gegeben durch \[\begin{equation}
I: \mathbb{R}_{>0} \to \mathbb{R}, \sigma^2 \mapsto I(\sigma^2) :=
\frac{1}{\sigma^6}\sum_{i=1}^n (y_i - \mu)^2 - \frac{n}{2\sigma^4}
\end{equation}\]
Die beobachtete Fisher-Information der Stichprobe ist gegeben durch \[\begin{equation}
I(\hat{\sigma}^{2\,\mbox{\tiny ML}}_n) = \frac{n}{2\hat{\sigma}_{\mbox{\tiny ML}}^4}
\end{equation}\]
Die erwartete Fisher-Information der Stichprobe ist gegeben durch \[\begin{equation}
J: \mathbb{R}_{>0} \to \mathbb{R}, \sigma^2 \mapsto J(\sigma^2) := \frac{n}{2\sigma^4}.
\end{equation}\]
Beweis. Wir erinnern uns, dass die Log-Likelihood-Funktion der Stichprobe eines Normalverteilungsmodells bei bekanntem Erwartungswertparameter \(\mu\) durch \[\begin{equation}
\ell: \mathbb{R}_{>0} \to \mathbb{R},
\sigma^2 \mapsto \ell(\sigma^2)
:= -\frac{n}{2} \ln 2\pi - \frac{n}{2} \ln \sigma^2 - \frac{1}{2\sigma^2}\sum_{i=1}^n(y_i-\mu)^2.
\end{equation}\] gegeben ist. Die Scorefunktion ergibt sich also als \[\begin{align}
\begin{split}
S(\sigma^2)
= \frac{\partial}{\partial\sigma^2}\ell(\sigma^2)
= - \frac{n}{2 \sigma^2} + \frac{1}{2\sigma^4}\sum_{i=1}^n(y_i-\mu)^2.
\end{split}
\end{align}\] Die Fisher-Information der Stichprobe ergibt sich als \[\begin{align}
\begin{split}
I(\sigma^2)
& = -\frac{\partial}{\partial\sigma^2}S(\sigma^2) \\
& = - \frac{\partial}{\partial\sigma^2}\left(\frac{n}{2\sigma^4} - \frac{1}{\sigma^6}\sum_{i=1}^n (y_i - \mu)^2\right) \\
& = \frac{1}{\sigma^6}\sum_{i=1}^n (y_i - \mu)^2 - \frac{n}{2\sigma^4}.
\end{split}
\end{align}\] Die beobachtete Fisher-Information ist die Fisher-Information an der Stelle des Maximum-Likelihood-Schätzers \(\hat{\sigma}^{2^{\mbox{\tiny ML}}}\), \[\begin{align}
\begin{split}
I(\hat{\sigma}^{2\,\mbox{\tiny ML}}_n)
& = \frac{\sum_{i=1}^n (y_i - \mu)^2}{\left(\hat{\sigma}^{2\,\mbox{\tiny ML}}_n \right)^3} -
\frac{n}{2\left(\hat{\sigma}^{2\,\mbox{\tiny ML}}_n \right)^2} \\
& = \frac{\sum_{i=1}^n (y_i - \mu)^2}{\frac{1}{n^3}\left(\sum_{i=1}^n (y_i - \mu)^2 \right)^3} -
\frac{n}{2\left(\hat{\sigma}^{2\,\mbox{\tiny ML}}_n \right)^2} \\
& = \frac{1}{\frac{1}{n^3}\left(\sum_{i=1}^n (y_i - \mu)^2 \right)^2} -
\frac{n}{2\left(\hat{\sigma}^{2\,\mbox{\tiny ML}}_n \right)^2} \\
& = \frac{n}{\left(\hat{\sigma}^{2\,\mbox{\tiny ML}}_n \right)^2} -
\frac{n}{2\left(\hat{\sigma}^{2\,\mbox{\tiny ML}}_n \right)^2} \\
& = \frac{n}{2\left(\hat{\sigma}^{2\,\mbox{\tiny ML}}_n \right)^2} \\
& = \frac{n}{2\hat{\sigma}^{4\,\mbox{\tiny ML}}_n}.
\end{split}
\end{align}\] Die erwartete Fisher-Information ergibt sich schließlich als \[\begin{align}
\begin{split}
J(\sigma^2)
& = \mathbb{E}_{\sigma^2}(I(\sigma^2)) \\
& = \mathbb{E}_{\sigma^2}\left(\frac{1}{\sigma^6}\sum_{i=1}^n (y_i - \mu)^2 - \frac{n}{2\sigma^4}\right) \\
& = \frac{1}{\sigma^6}\sum_{i=1}^n \mathbb{E}_{\sigma^2}\left((y_i - \mu)^2 \right) - \frac{n}{2\sigma^4} \\
& = \frac{1}{\sigma^6}\sum_{i=1}^n \sigma^2 - \frac{n}{2\sigma^4} \\
& = \frac{n\sigma^2}{\sigma^6} - \frac{n}{2\sigma^4} \\
& = \frac{n}{\sigma^4} - \frac{n}{2\sigma^4} \\
& = \frac{n}{2\sigma^4}. \\
\end{split}
\end{align}\]
Mit den oben diskutierten Eigenschaften der Scorefunktion können wir nun die Cramér-Rao-Ungleichung formulieren und beweisen.
Theorem 31.13 (Cramér-Rao-Ungleichung) Gegeben sei ein Frequentistisches Inferenzmodell mit eindimensionalem Parameter \(\theta \in \Theta \subseteq \mathbb{R}\), WMF oder WDF \(p_\theta\) und \(\hat{\tau}\) sei ein erwartungstreuer Schätzer von \(\tau(\theta)\). Dann gilt \[\begin{equation}
\mathbb{V}_\theta(\hat{\tau}) \ge \frac{\left(\frac{d}{d\theta}\tau(\theta)\right)^2}{J(\theta)}.
\end{equation}\] Speziell gilt für einen Parameterschätzer mit \(\tau(\theta) := \theta\) und somit \[\begin{equation}
\hat{\tau} = \hat{\theta} \mbox{ und } \left(\frac{d}{d\theta}\tau(\theta)\right)^2 = 1,
\end{equation}\] dass \[\begin{equation}
\mathbb{V}_\theta(\hat{\theta}) \ge \frac{1}{J(\theta)}.
\end{equation}\] Die rechte Seite obiger Ungleichungen wird dabei Cramér-Rao-Schranke genannt.
Beweis. Wir halten zunächst fest, dass für die Zufallsvariablen \(S(\theta)\) und \(\hat{\tau}\) mit der Korrelationsungleichung (Theorem 26.4) und der Identität von \(\mathbb{V}_\theta(S(\theta))\) und \(J(\theta)\) (Theorem 31.9) gilt, dass \[\begin{equation}
\frac{\mathbb{C}_\theta(S(\theta), \hat{\tau})^2}{\mathbb{V}_\theta(S(\theta))\mathbb{V}_\theta(\hat{\tau})}
\le 1
\Leftrightarrow \mathbb{V}_\theta(\hat{\tau})
\ge \frac{\mathbb{C}_\theta(S(\theta),\hat{\tau})^2}{J(\theta)}.
\end{equation}\] Mit dem Kovarianzverschiebungssatz (Theorem 25.2), der Tatsache, dass der Erwartungswert der Scorefunktion immer Null ist (Theorem 31.9) und der vorausgesetzten Erwartungstreue von \(\hat{\tau}\) ergibt sich dann zunächst \[\begin{align}
\begin{split}
\mathbb{C}_\theta(S(\theta),\hat{\tau})
& = \mathbb{E}_\theta(S(\theta)\hat{\tau}) - \mathbb{E}_\theta(S(\theta))\mathbb{E}_\theta(\hat{\tau}) \\
& = \mathbb{E}_\theta(S(\theta)\hat{\tau}) \\
& = \int S(\theta)\,\hat{\tau}\,p_\theta(x) \,dx \\
& = \int \frac{d}{d\theta} \ln L(\theta)\,\hat{\tau}\,p_\theta(x) \,dx \\
& = \int \frac{\frac{d}{d\theta} L(\theta)}{L(\theta)}\,\hat{\tau}\,p_\theta(x) \,dx \\
& = \int \frac{\frac{d}{d\theta} L(\theta)}{p_\theta(x)}\,\hat{\tau}\,p_\theta(x) \,dx \\
& = \int \frac{d}{d\theta} L(\theta)\, \hat{\tau} \,dx \\
& = \frac{d}{d\theta} \int L(\theta)\, \hat{\tau} \,dx \\
& = \frac{d}{d\theta} \int \hat{\tau}\, p_\theta(x) \,dx \\
& = \frac{d}{d\theta} \mathbb{E}_\theta(\hat{\tau}) \\
& = \frac{d}{d\theta} \tau(\theta).
\end{split}
\end{align}\] Damit folgt dann aber direkt \[\begin{equation}
\mathbb{V}_\theta(\hat{\tau}) \ge \frac{\left(\frac{d}{d\theta}\tau(\theta) \right)^2}{J(\theta)}.
\end{equation}\]
Für Parameterschätzer gilt also insbesondere, dass die Varianz eines erwartungstreuen Parameterschätzers \(\hat{\theta}\) immer größer oder gleich der reziproken erwarteten Fisher-Information \(J(\theta)\) ist. Im Fall, dass sogar \[\begin{equation}
\mathbb{V}_\theta(\hat{\theta}) = \frac{1}{J(\theta)}
\end{equation}\] ist, ist die Varianz des Parameterschätzers minimal und der Schätzer somit als optimaler Schätzer im Sinne der Cramér-Rao-Ungleichung nachgewiesen. Wir kommen auf diesen Gedanken in Kapitel 31.4 zurück.
31.3 Asymptotische Schätzereigenschaften
In diesem Abschnitt geben wir eine Kurzeinführung in die Asymptotische Statistik (Vaart (1998)). Die Asymptotische Statistik ist der Bereich der Frequentistischen Inferenz, der sich mit dem Verhalten von Statistiken und Schätzern bei großen Stichprobenumfängen beschäftigt. Dabei werden Methoden der Asymptotischen Statistik zum einen benutzt um, wie hier, qualitative Schätzereigenschaften zu studieren und andererseits um Schätzereigenschaften bei großen Stichprobenumfängen approximieren zu können. Da Stichprobenumfänge heutzutage durchaus groß sein können, sind die Methoden der Asymptotischen Statistik also für die Anwendung gut motiviert und dort vielseitig einsetzbar.
In Fortführung von Kapitel 31.2 wollen wir in diesem Abschnitt vier asymptotische Schätzereigenschaften beleuchten. Um zu betonen, dass in diesem Abschnitt die Eigenschaften eines Schätzers \(\hat{\tau}\) vom Stichprobenumfang \(n\) abhängen, schreiben wir in diesem Abschnitt für einen Schätzer \(\hat{\tau}_n\). In Kapitel 31.3.1 betrachten wir die Asymptotische Erwartungstreue eines Schätzers. Dabei heißt ein Schätzer \(\hat{\tau}_n\) für \(\tau\)asymptotisch erwartungstreu, wenn der Erwartungswert von \(\hat{\tau}_n\) für große Stichprobenumfänge \(n \to \infty\) mit dem wahren, aber unbekannten, Wert \(\tau(\theta)\) identisch ist. In Kapitel 31.3.2 führen wir den Begriff der Konsistenz eines Schätzers ein. Intuitiv heißt ein Schätzer \(\hat{\tau}_n\) für \(\tau\)konsistent, wenn für große Stichprobenumfänge \(n \to \infty\) die Wahrscheinlichkeit dafür, dass \(\hat{\tau}_n(y)\) vom wahren, aber unbekannten, Wert \(\tau(\theta)\) abweicht, beliebig klein wird. Für große Stichprobenumfänge resultieren die Verteilungen von Schätzern oft in Normalverteilungen. In Kapitel 31.3.3 führen wir mit dem Begriff der Asymptotischen Normalverteilung eine entsprechende Formalisierung ein. Ein Schätzer \(\hat{\tau}_n\) für \(\tau\) heißt dann asymptotisch normalverteilt, wenn für große Stichprobenumfänge \(n \to \infty\), die Verteilung von \(\hat{\tau}_n\) durch eine Normalverteilung gegeben ist. In Kapitel 31.3.4 schließlich betrachten wir mit der Asymptotischen Effizienz ein Optimalitätskriterium für Schätzer bei gegen unendlich strebenden Stichprobenumfängen. Danach heißt ein Schätzer \(\hat{\tau}_n\) für \(\tau\)asymptotisch effizient, wenn für große Stichprobenumfänge \(n \to \infty\) die Verteilung von \(\hat{\tau}_n\) durch eine Normalverteilung mit Erwartungswertparameter \(\tau(\theta)\) und Varianzparameter gleich der Cramér-Rao-Schranke gegeben ist.
31.3.1 Asymptotische Erwartungstreue
Die Asymptotische Erwartungstreue eines Schätzers verfeinert den Begriff des erwartungstreuen Schätzers wie folgt.
Definition 31.9 (Asymptotische Erwartungstreue)\(y = (y_1,...,y_n)\) sei die Stichprobe eines parametrischen Produktmodells und \(\hat{\tau}_n\) sei ein Schätzer für \(\tau\). \(\hat{\tau}_n\) heißt asymptotisch erwartungstreu, wenn gilt, dass \[\begin{equation}
\lim_{n\to\infty} \mathbb{E}_\theta(\hat{\tau}_n(y)) = \tau(\theta) \mbox{ für alle } \theta \in \Theta.
\end{equation}\]
Asymptotisch erwartungstreue Schätzer sind also nur erwartungstreu, wenn der Stichprobenumfang gegen Unendlich geht. Erwartungstreue Schätzer sind immer auch asymptotisch erwartungstreu, da ihre Erwartungstreue vom Stichprobenumfang unabhängig sind. Als Beispiel für einen nur asymptotisch erwartungstreuen Schätzer betrachten wir den Maximum-Likelihood-Schätzer des Varianzparameters des Normalverteilungsmodells.
Theorem 31.14 (Asymptotische Erwartungstreue des Varianzparameterschätzers)\(y = (y_1,...,y_n)\) sei die Stichprobe eines Normalverteilungsmodells mit Varianzparameter \(\sigma^2\). Dann ist der Maximum-Likelihood-Schätzer von \(\sigma^2\), \[\begin{equation}
\hat{\sigma}_n^{2^{\mbox{\tiny ML}}}
:= \frac{1}{n}\sum_{i=1}^n \left(y_i - \bar{y}_n \right)^2,
\end{equation}\] nicht erwartungstreu, aber asymptotisch erwartungstreu.
Beweis. Mit der Erwartungstreue der Stichprobenvarianz ergibt sich zunächst (vgl. Theorem 31.3) \[\begin{equation}
\mathbb{E}_{\mu,\sigma^2}\left(\hat{\sigma}_n^{2^{\mbox{\tiny ML}}} \right)
= \mathbb{E}_{\mu,\sigma^2}\left(\frac{1}{n}\sum_{i=1}^n \left(y_i - \bar{y}_n \right)^2 \right)
= \frac{1}{n}\mathbb{E}_{\mu,\sigma^2}\left(\sum_{i=1}^n \left(y_i - \bar{y}_n \right)^2 \right)
= \frac{n-1}{n}\sigma^2.
\end{equation}\] Also gilt \[\begin{equation}
\mathbb{E}_{\mu,\sigma^2}\left(\hat{\sigma}_n^{2^{\mbox{\tiny ML}}} \right) \neq \sigma^2
\end{equation}\] und \(\hat{\sigma}_n^{2^{\mbox{\tiny ML}}}\) kein erwartungstreuer Schätzer von \(\sigma^2\). Allerdings gilt auch \[\begin{equation}
\frac{n-1}{n} \to 1 \mbox{ für } n \to \infty,
\end{equation}\] so dass \[\begin{equation}
\lim_{n \to \infty} \mathbb{E}_{\mu,\sigma^2}\left(\hat{\sigma}_n^{2^{\mbox{\tiny ML}}}\right) =
\lim_{n \to \infty} \frac{n-1}{n}\sigma^2 =
\sigma^2 \lim_{n \to \infty} \frac{n-1}{n} =
\sigma^2
\end{equation}\] gilt und der Maximum-Likelihood-Schätzer von \(\sigma^2\) damit asymptotisch erwartungstreu ist.
Beispiel 31.4 (Simulationsbeispiel) Folgender R Code simuliert das Verhalten des Maximum-Likelihood-Schätzers für den Varianzparameter eines Normalverteilungsmodells mit wahren, aber unbekannten, Parametern \(\mu = 1\) und \(\sigma^2 = 2\) in Abhängigkeit des Stichprobenumfangs.
# Modellformulierungmu =1# wahrer, aber unbekannter, Erwartungswertparametersigsqr =2# wahrer, aber unbekannter, Varianzparametern =seq(1,100, by =2) # Stichprobenumfängens =1e3# Anzahl Simulationen pro Stichprobenumfangsigsqr_ml =matrix(rep(NaN, length(n)*ns),ncol =length(n)) # \hat{\sigma^2}^{ML} Array# Simulationfor(i inseq_along(n)){ # Stichprobenumfangsiterationenfor(s in1:ns){ # Stichprobenrealisierungsiterationen y =rnorm(n[i], mu, sqrt(sigsqr)) # Stichprobenrealisation sigsqr_ml[s,i] = ((n[i]-1)/n[i])*var(y) # \hat{\sigma^2}^{ML} }}E_sigsqr_ml =colMeans(sigsqr_ml) # Schätzererwartungswertschätzung
Wir visualisieren den basierend auf obigen Simulationen geschätzten Erwartungswert des Schätzers in Abhängigkeit des Stichprobenumfangs in Abbildung 31.3. Für kleine Stichprobenumfänge unterschätzt der Schätzer den wahren, aber unbekannten, Varianzparameter deutlich, für größere Stichprobenumfänge dagegen nicht.
Abbildung 31.3: Simulation des Erwartungswerts des Maximum-Likelihood-Schätzers für den Varianzparameter eines Normalverteilungsmodells. Bei kleinen Stichprobenumfängen unterschätzt der Maximum-Likelihood-Schätzer den wahren, aber unbekannten, Varianzparameter systematisch, bei größeren Stichprobenumfängen ist der Schätzer in etwa erwartungstreu.
31.3.2 Konsistenz
Der Begriff der Konsistenz eines Schätzers verallgemeinert das Schwache Gesetz der Großen Zahlen von Stichprobenmitteln und Erwartungswerten (vgl. Theorem 27.1) auf beliebige Schätzer und wahre, aber unbekannte, Parameterwerte.
Definition 31.10 (Konsistenz)\(y := (y_1,...,y_n)\) sei die Stichprobe eines parametrischen Produktmodells und \(\hat{\tau}_n\) sei ein Schätzer von \(\tau\). Dann heißt eine Folge von Schätzern \(\hat{\tau}_1, \hat{\tau}_2, ...\) eine konsistente Folge von Schätzern, wenn für jedes noch so kleine \(\epsilon > 0\) und jedes \(\theta \in \Theta\) gilt, dass \[\begin{equation}
\lim_{n\to \infty}
\mathbb{P}_\theta\left(|\hat{\tau}_n(y) - \tau(\theta)| \ge \epsilon \right) = 0.
\end{equation}\] Wenn \(\hat{\tau}_1,\hat{\tau}_2,...\) eine konsistente Folge von Schätzern ist, dann heißt \(\hat{\tau}_n\) ein konsistenter Schätzer.
Die Intuition zu Definition 31.10 entspricht dem Gesetz der Großen Zahlen. Für Stichprobenumfänge mit \(n \to \infty\) wird die Wahrscheinlichkeit, dass \(\hat{\tau}_n(y)\) beliebig nah bei \(\tau(\theta)\) liegt bzw. die Wahrscheinlichkeit, dass \(\hat{\tau}_n(y)\) weit von \(\tau(\theta)\) abweicht, klein. Allerdings müssen diese Eigenschaften für alle möglichen wahren, aber unbekannten, Parameterwerte gelten. Wie unten gezeigt werden soll, ist das Stichprobenmittel ein konsistenter Schätzer für den Erwartungswertparameter eines Normalverteilungsmodells.
Beispiel 31.5 Analog zu Kapitel 27.1 demonstrieren wir die Bedeutung der Konsistenz mithilfe der Simulation für \(\mu = 1\) und \(\sigma^2 = 2\) anhand folgenden R Codes.
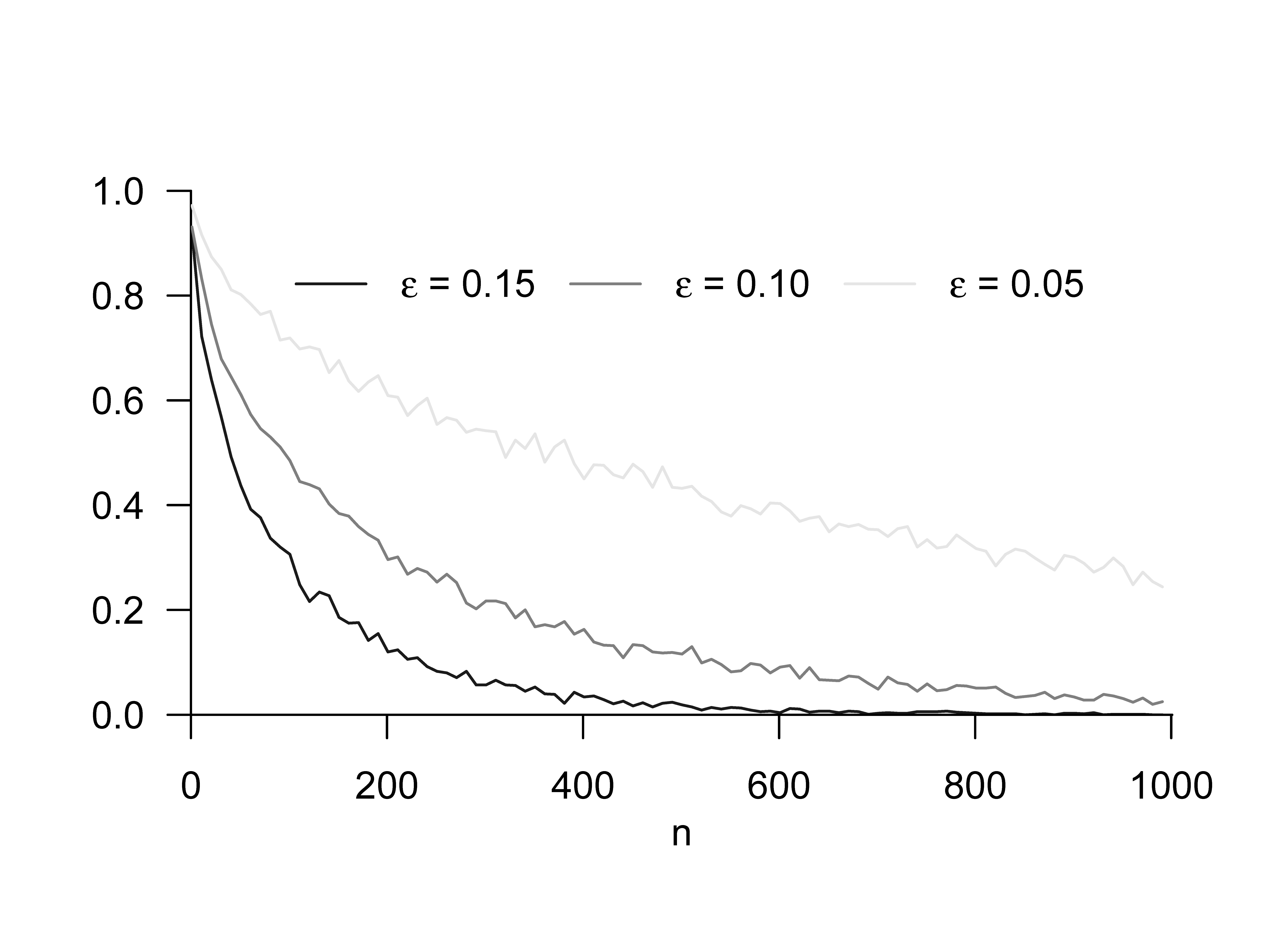
Wir visualisieren die Schätzung der Wahrscheinlichkeit \(\mathbb{P}(|\hat{\tau}_n(y)-\tau(\theta)| \ge \epsilon)\) für dieses Beispiel in Abbildung 31.4 in Abhängigkeit des Stichprobenumfangs und des Kriteriumwerts \(\epsilon\). Bei größeren Werten von \(\epsilon\) genügen geringe Stichprobenumfänge für eine geringe Wahrscheinlichkeit der Abweichung des Schätzers vom wahren, aber unbekannten, Parameterwert, bei kleineren Werten von \(\epsilon\) sind dazu größere Stichprobenumfänge nötig.
Abbildung 31.4: Simulation der Konsistenz des Stichprobenmittels als Schätzer für den Erwartungswertparameter des Normalverteilungsmodells.
Die in Theorem 31.15 und Theorem 31.16 angegebenen Kriterien für die Konsistenz von Schätzern vereinfachen den Nachweis der Konsistenz eines Schätzers mithilfe des Mittleren Quadratischen Fehlers (Definition 31.6).
Theorem 31.15 (Mittlerer Quadratischer Fehler Kriterium für Konsistenz)\(y := (y_1,...,y_n)\) sei die Stichprobe eines parametrischen Produktmodells und \(\hat{\tau}_n\) sei ein Schätzer von \(\tau\). Wenn gilt, dass \[\begin{equation}
\lim_{n\to \infty} \mbox{MQF}(\hat{\tau}_n) = 0,
\end{equation}\] dann ist \(\hat{\tau}_n\) ein konsistenter Schätzer.
Beweis. Mit der Chebychev-Ungleichung gilt, dass \[\begin{equation}
\mathbb{P}_\theta\left(|\hat{\tau}_n(y) - \tau(\theta)| \ge \epsilon \right) \le
\frac{\mathbb{E}_\theta\left((\hat{\tau}_n(y) - \tau(\theta))^2\right)}{\epsilon^2}
\end{equation}\] Grenzwertbildung ergibt dann \[\begin{equation}
\lim_{n\to \infty}\mathbb{P}_\theta\left(|\hat{\tau}_n(y) - \tau(\theta)| \ge \epsilon \right) \le
\frac{1}{\epsilon^2}\lim_{n\to\infty}\mathbb{E}_\theta\left((\hat{\tau}_n(y) - \tau(\theta))^2\right).
\end{equation}\] Wenn also \(\lim_{n\to\infty}\mathbb{E}_\theta\left((\hat{\tau}_n(y) - \tau(\theta))^2\right) = 0\) gilt, dann gilt mit \(\mathbb{P}_\theta(|\hat{\tau}_n(y) - \tau(\theta)| \ge \epsilon)\ge 0\), dass \[\begin{equation}
\lim_{n\to \infty}\mathbb{P}_\theta\left(|\hat{\tau}_n(y) - \tau(\theta)| \ge \epsilon \right) = 0.
\end{equation}\] Also ist \(\hat{\tau}_n\) ein konsistenter Schätzer.
Theorem 31.16 (Bias-Varianz-Kriterium für Konsistenz)\(y := (y_1,...,y_n)\) sei die Stichprobe eines parametrischen Produktmodells und \(\hat{\tau}_n\) sei ein Schätzer von \(\tau\). Wenn \[\begin{equation}
\lim_{n\to \infty} \mbox{B}(\hat{\tau}_n) = 0
\mbox{ und }
\lim_{n\to \infty} \mathbb{V}_\theta(\hat{\tau}_n) = 0
\end{equation}\] gelten, dann ist \(\hat{\tau}_n\) ein konsistenter Schätzer
Beweis. Wenn \(n \to \infty\), dann gilt \(\mbox{B}(\hat{\tau}_n) \to 0\), also auch \(\mbox{B}(\hat{\tau}_n)^2 \to 0\). Wenn für \(n \to \infty\) sowohl \(\mbox{B}(\hat{\tau}_n)^2 \to 0\) als auch \(\mathbb{V}_\theta(\hat{\tau}_n) \to 0\), dann gilt auch \(\lim_{n\to \infty} \mbox{MQF}(\hat{\theta}_n) = 0\). Also gilt mit Theorem 31.15, dass \(\hat{\tau}_n\) konsistent ist.
Als Anwendung von Theorem 31.16 wollen wir mit folgendem Theorem die Konsistenz des Stichprobenmittels als Schätzer für den Erwartungswert bei Normalverteilung nachweisen.
Theorem 31.17 (Konsistenz des Erwartungswertschätzers bei Normalverteilung) Es sei \(y\) die Stichprobe eines Normalverteilungsmodells. Dann ist \(\bar{y}_n\) ein konsistenter Schätzer von \(\mathbb{E}(y_1)\).
Beweis. Mit der Erwartungstreue des Stichprobenmittels als Schätzer für den Erwartungswert gilt zunächst \[\begin{equation}
\lim_{n \to \infty} \mbox{B}(\bar{y}_n) = 0.
\end{equation}\] Weiterhin gilt mit der Varianz des Stichprobenmittels \[\begin{equation}
\lim_{n \to \infty} \mathbb{V}_\theta(\bar{y}_n) = \lim_{n\to \infty} \frac{1}{n}\mathbb{V}(y_1) = 0.
\end{equation}\] Mit dem Bias-Varianz-Kriterium folgt dann die Konsistenz von \(\bar{y}_n\) als Schätzer von \(\mathbb{E}(y_1)\)
Man beachte, dass Theorem 31.17 natürlich auch schon im Schwachen Gesetz der Großen Zahlen impliziert ist (vgl. Theorem 27.1).
31.3.3 Asymptotische Normalität
In manchen Fällen nähert sich die frequentistische Verteilung eines Schätzers bei großen Stichprobenumfängen einer Normalverteilung. Man nennt einen solchen Schätzer dann asymptotisch normalverteilt.
Definition 31.11 (Asymptotisch normalverteilter Schätzer)\(y = (y_1,...,y_n)\) sei die Stichprobe eines parametrischen Produktmodells und \(\hat{\theta}_n\) sei ein Parameterschätzer für \(\theta\). Weiterhin sei \[\begin{equation}
\tilde{\theta} \sim N(\mu,\sigma^2)
\end{equation}\] eine normalverteilte Zufallsvariable mit Erwartungswertparameter \(\mu\) und Varianzparameter \(\sigma^2\). Wenn \(\hat{\theta}_n\) in Verteilung gegen \(\tilde{\theta}\) konvergiert, wenn also für die KVFen \(P_n\) und \(P\) von \(\hat{\theta}_n\) und \(\tilde{\theta}\), respektive, gilt, dass \[\begin{equation}
\lim_{n\to \infty} P_n(\hat{\theta}_n) = P(\tilde{\theta}),
\end{equation}\] dann heißt \(\hat{\theta}_n\)asymptotisch normalverteilt und wir schreiben \[\begin{equation}
\hat{\theta}_n \stackrel{a}{\sim} N(\mu,\sigma^2).
\end{equation}\]
Als Beispiel für einen asymptotisch normalverteilten Schätzer betrachten wir in Kapitel 31.3.4 den Maximum-Likelihood-Schätzer des Bernoullimodellparameters. Es ist bemerkenswert, dass dieser Schätzer asymptotisch normalverteilt ist, da die Stichprobenvariablen des Bernoullimodells lediglich die Werte null und eins annehmen.
31.3.4 Asymptotische Effizienz
In manchen Fällen lassen sich neben der asymptotischen Normalität eines Schätzers auch in der Form des Frequentistischen Modells begründete Aussagen zum Erwartungswertparameter und Varianzparameter dieser asymptotischen Normalverteilung machen. Der Begriff des effizienten Schätzers formuliert einen solchen Spezialfall.
Definition 31.12\(y = (y_1,...,y_n)\) sei die Stichprobe eines parametrischen Produktmodells und \(\hat{\theta}_n\) sei ein Parameterschätzer für \(\theta\). Weiterhin sei \(J(\theta)\) die erwartete Fisher-Information der Stichprobe \(y\). Wenn gilt, dass \[\begin{equation}
\hat{\theta}_n \stackrel{a}{\sim} N\left(\theta, J(\theta)^{-1}\right),
\end{equation}\] dann heißt \(\hat{\theta}_n\) .
Ein asymptotisch effizienter Schätzer ist offenbar auch immer asymptotisch normalverteilt und erwartungstreu. Die Varianz der asymptotischen Verteilung eines Schätzers nennt man auch die asymptotische Varianz. Für einen asymptotisch effizienten Schätzers ist die asymptotische Varianz mit der Cramér-Rao-Schranke identisch und damit in der Menge der erwartungstreuen asymptotisch normalverteilten Schätzer minimal.
Beispiel 31.6 Als Beispiel für einen asymptotisch effizienten Schätzer betrachten wir den Maximum-Likelihood-Schätzer des Bernoullimodellparameters. Folgender R Code simuliert die Frequentistische Verteilung dieses Schätzers und bestimmt die WDF seiner asymptotischen Verteilung
Abbildung 31.5: Simulation der asymptotischen Effizienz des Maximum-Likelihood-Parameterschätzers für den Parameter eines Bernoullimodells. Mit steigendem Stichprobenumfang gleicht sich die durch ein Histogramm dargestellte Verteilung der simulierten Schätzerwerte der in Definition 31.12 formulierten Normalverteilung
31.4 Eigenschaften von Maximum-Likelihood-Schätzern
Das Maximum-Likelihood-Prinzip zur Gewinnung von Schätzern für Parameter Frequentistischer Inferenzmodelle ist durch folgendes Theorem zu den Eigenschaften von Maximum-Likelihood-Schätzern begründet.
Theorem 31.18 (Eigenschaften von Maximum-Likelihood-Schätzern)\(y\) sei die Stichprobe eines parametrischen Produktmodells und \(\hat{\theta}_n^{\mbox{\tiny{ML}}}\) sei ein Maximum-Likelihood-Schätzer für \(\theta\). Dann gilt, dass \(\hat{\theta}_n^{\mbox{\tiny{ML}}}\)
nicht notwendigerweise erwartungstreu, aber
asymptotisch erwartungstreu,
konsistent,
asymptotisch normalverteilt und
asymptotisch effizient
ist.
Für einen Beweis von Theorem 31.18 verweisen wir auf Held & Sabanés Bové (2014), Abschnitt 3.4. Nutzt man also das Maximum-Likelihood-Prinzip zur Gewinnung eines Schätzers, so erfüllt der gewonnene Schätzer garantiert die in Theorem 31.18 zusammengefassten Schätzergütekriterien.
31.5 Literaturhinweise
Die in diesem Kapitel vorgestellten Resultate gehen in ganz wesentlicher Weise auf Fisher (1922) zurück. Aldrich (1997) gibt dazu eine historische Einordnung.
Selbstkontrollfragen
Geben Sie die Definition des Begriffs eines Parameterpunktschätzers wieder.
Erläutern Sie den Begriff des Parameterpunktschätzers.
Geben Sie die Definition der Begriffe der Likelihood-Funktion und der Log-Likelihood-Funktion wieder.
Geben Sie die Definition des Begriffs des Maximum-Likelihood-Schätzers wieder.
Erläutern Sie das Vorgehen zur Gewinnung von Maximum-Likelihood-Schätzern.
Geben Sie das Theorem zum Maximum-Likelihood-Schätzer des Bernoullimodellparameters wieder.
Geben Sie das Theorem zu den Maximum-Likelihood-Schätzern der Normalverteilungsmodellparameter wieder.
Geben Sie die Definition des Begriffs der Erwartungstreue eines Schätzers wieder.
Erläutern Sie den Begriff der Erwartungstreue eines Schätzers.
Geben Sie die Definition der Begriffe der Varianz und des Standardfehlers eines Schätzers wieder.
Geben Sie die Definition des Begriffs der Asymptotischen Erwartungstreue eines Schätzers wieder.
Erläutern Sie den Begriff der asymptotischen Erwartungstreue eines Schätzers.
Geben Sie die Definition des Begriffs der Konsistenz eines Schätzers wieder.
Erläutern Sie den Begriff der Konsistenz eines Schätzers.
Geben Sie die ersten drei Aussagen des Theorems zu den Eigenschaften von Maximum-Likelihood-Schätzern wieder.
Um einen Maximum-Likelihood-Schätzer zu gewinnen, formuliert man zunächst die Log-Likelihood-Funktion und bestimmt dann die Nullstellen ihrer Ableitung als potenzielle Maximumstellen. Dazu nutzt man in klassischen Beispielen meist die analytische, in der Anwendung auf komplexere Modelle dagegen meist die numerische Optimierung.
Ein Schätzer heißt asymptotisch erwartungstreu, wenn sein Erwartungswert für gegen unendlich gehende Stichprobenumfänge mit dem von ihm geschätzten wahren, aber unbekannten, Wert identisch ist.
Ein Schätzer heißt konsistent, wenn für große Stichprobenumfänge die Wahrscheinlichkeit dafür, dass der Schätzerwert vom wahren, aber unbekannten, Wert abweicht, beliebig klein wird.
Aldrich, J. (1997). R.A. Fisher and the Making of Maximum Likelihood 1912-1922. Statistical Science, 12(3), 162–176. https://doi.org/10.1214/ss/1030037906
Fisher, R. A. (1922). On the Mathematical Foundations of Theoretical Statistics. Philosophical Transactions of the Royal Society of London. Series A, Containing Papers of a Mathematical or Physical Character, 222(594-604), 309–368. https://doi.org/10.1098/rsta.1922.0009