[[1]]
[1] 1 4 5
[[2]]
[,1] [,2] [,3] [,4]
[1,] 1 3 5 7
[2,] 2 4 6 8
[[3]]
function (x) .Primitive("exp")16 Listen, Dataframes und Tibbles
16.1 Listen
R Listen sind geordnete Folgen von R Objekten. Listen werden als rekursiver Datentyp bezeichnet, da sie Objekte verschiedener Datentypen, insbesondere auch wiederum Listen bündeln können. Obwohl sich die intuitive Sichtweise, dass Listen Objekte “enthalten”, anbietet, “enthalten” Listen de facto keine Objekte, sondern lediglich die Referenzen zu den entsprechenden Objekten im Arbeitsspeicher (Abbildung 16.1). Listen sind ein wesentlicher Baustein von R Dataframes.
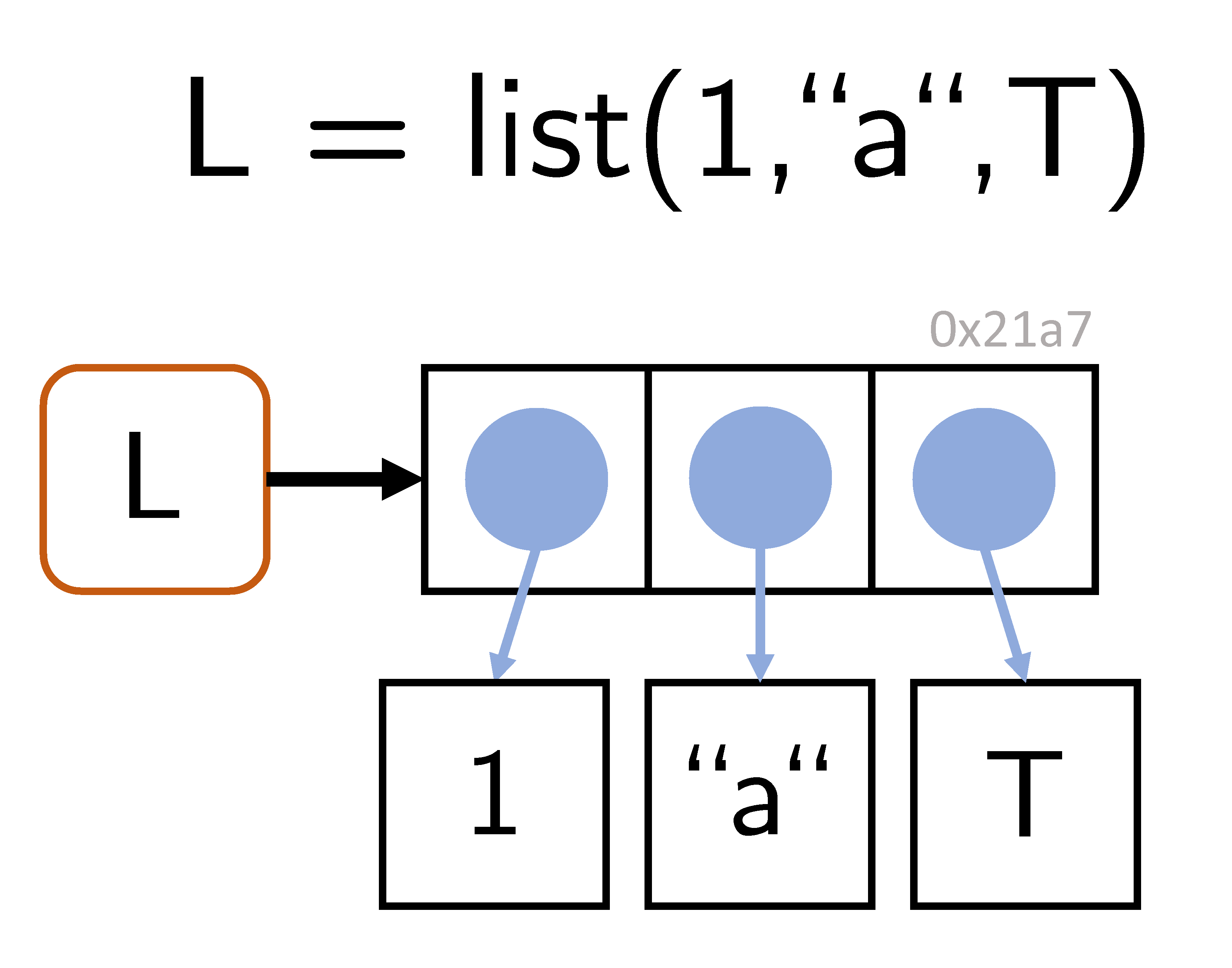
Erzeugung
Listen können durch die direkte Konkatenation der Listenelemente mithilfe der Funktion list() erzeugt werden.
Insbesondere können auch Listen selbst Elemente von Listen sein, was ihre Bezeichnung als rekursiver Datentyp motiviert.
Die von den R Vektoren vertraute Funktion c() kann auch zum Konkatenieren von mehreren Listen genutzt werden.
Charakterisierung
Der Datentyp von Listen ist list:
length() gibt die Anzahl der Listenelemente auf dem obersten Listenlevel aus, die Elementinhalte werden also ignoriert:
[1] 3Die Dimension, Zeilen- und Spaltenanzahlen von Listen sind NULL:
Indizierung
Bei der Indizierung von Listen ist zu beachten, dass Listen auf zwei unterschiedliche Arten indiziert werden können. Einfache eckige Klammern [ ] indizieren Listenelemente als Listen:
[[1]]
[1] 1 2 3[1] "list"Doppelte eckige Klammern [[ ]] indizieren den Inhalt von Listenelementen:
Auch beim Ersetzen von Listeninhalten sind diese Konventionen zu beachten. So ist es zum Beispiel nicht möglich, durch den Ausdruck L[1] = c(1,2,3) das erste Listenelement zu ändern, da der Vektor c(1,2,3) keine Liste ist:
Indizierung
Die Prinzipien der Listenindizierung sind analog zu denen der Vektorindizierung. Vektoren positiver Zahlen adressieren die entsprechenden Elemente:
[[1]]
[1] 1 2 3
[[2]]
[1] 3.141593Vektoren negativer Zahlen adressieren die zu ihren Werten komplementären Elemente:
Logische Vektoren adressieren Elemente mit Index TRUE:
[[1]]
[1] 1 2 3
[[2]]
[1] "a"Zur nicht numerischen Adressierung können Listenelemente auch Namen gegeben werden. Dies ist nach der Erzeugung einer Liste mithilfe der names() Funktion möglich:
$Frodo
[1] 1 2
$Sam
[1] TRUEEbenso ist es möglich, die Namen der Listenelemente direkt bei Erzeugung der Liste durch Zuweisung zu vergeben:
Sowohl Listenelemente als auch Listenelementinhalte können dann mit ihren Namen adressiert werden:
$frodo
[1] 1 2 3[1] "list"[1] 1 2 3[1] "character"Insbesondere können Listenelementinhalte auch mit dem $ Operator und ihrem Namen indiziert werden. Dies stellt im Rahmen der Dataframes die gebräuchlichste Art der Listenindizierung dar:
[1] 1 2 3[1] "integer"[1] "a"[1] "character"[1] "b"[1] "character"Arithmetik
Eine allgemeine Listenarithmetik ist nicht definiert, da Listenelementinhalte ja unterschiedlichen Datentyps sein können, für die unitäre oder binäre Operationen nicht definiert sind:
Error in `L1 + L2`:
! nicht-numerisches Argument für binären OperatorSind Inhalte von Listenelementen allerdings von einem gemeinsamen Datentyp, für den bestimmte binäre Operationen definiert sind, so können sie auch z.B. arithmetisch verknüpft werden:
Copy-on-modify
Wie bei Vektoren gilt bei Listen das Copy-on-modify-Prinzip. Speziell gilt bei Listen, dass sogenannte shallow copies bei Modifikation einer Liste erzeugt werden. Dabei wird nur das Listenobjekt selbst kopiert und erhält eine neue Adresse im Arbeitsspeicher, nicht aber die durch die Liste gebundenen Objekte, die an den gleichen Adressen im Arbeitsspeicher verbleiben. lobstr::ref() erlaubt es, dieses Verhalten nachzuvollziehen.
█ [1:0x2269e896648] <list>
├─[2:0x2269d0c1620] <dbl>
├─[3:0x2269d0c1428] <dbl>
└─[4:0x2269d0c11c0] <dbl> █ [1:0x2269e896648] <list>
├─[2:0x2269d0c1620] <dbl>
├─[3:0x2269d0c1428] <dbl>
└─[4:0x2269d0c11c0] <dbl> █ [1:0x2269ef521d8] <list>
├─[2:0x2269d0c1620] <dbl>
├─[3:0x2269d0c1428] <dbl>
└─[4:0x2269d286c48] <dbl> Offenbar ändert die Zuweisung L2 = L1 zunächst nichts an den Arbeitsspeicheradressen, auf die L1 und L2 sowie ihre Elemente verweisen. Die Modifikation des Inhalts des dritten Listenelements von L2 durch L2[[3]] = 4 allerdings ändert dann die Adresse des Listenobjekts im Arbeitsspeicher, da eine Kopie des Listenobjekts erzeugt wird. Gleichzeitig ändern sich gemäß dem Shallow-Copy-Prinzip die Adressen der ersten beiden Inhalte von L2 aber nicht. Abbildung 16.2 visualisiert diese Prinzipien an einem Beispiel.
L2 = L1 für eine Liste L1 sowie der Modifikation eines Elements von L2.
16.2 Dataframes
R Dataframes sind die zentrale Datenstruktur in R. Dataframes stellt man sich am besten als Tabelle vor, deren Spalten Namen haben. Technisch ist ein Dataframe eine Liste, deren Elemente Vektoren gleicher Länge sind. Die Listenelemente entsprechen dabei den Spalten einer Tabelle und die Vektorelemente an gleicher Position entsprechen den Zeilen einer Tabelle.
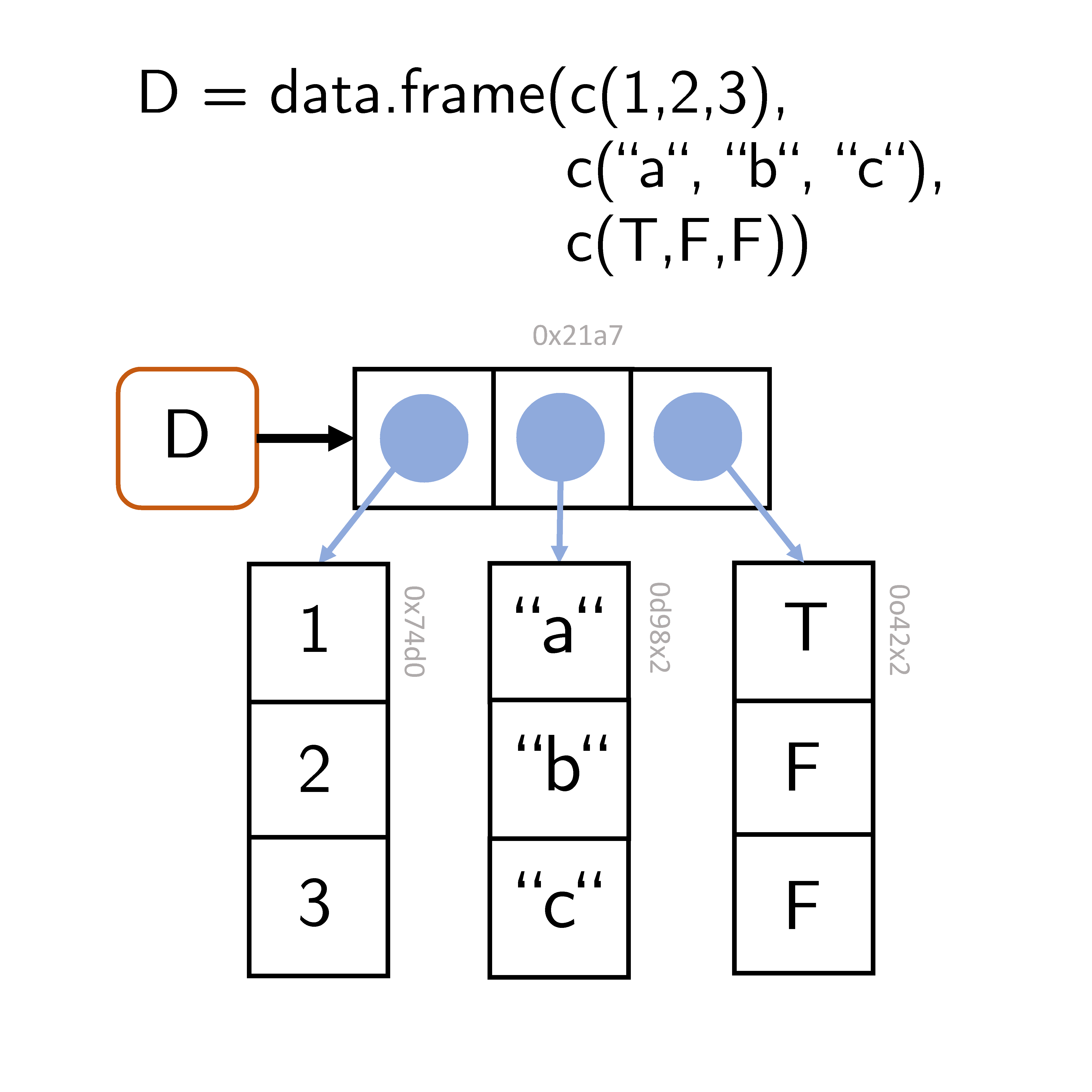
Erzeugung
Dataframes werden mit der Funktion data.frame() erzeugt. Dabei werden als Argumente der Funktion die Spaltennamen und ihre vektorwertigen Inhalte festgelegt:
x y z
1 a 1 TRUE
2 b 2 TRUE
3 c 3 FALSE
4 d 4 TRUEDie Spalten des Dataframes müssen die gleiche Länge haben, ansonsten ist ein Dataframe nicht definiert:
Error in `data.frame()`:
! Argumente implizieren unterschiedliche Anzahl Zeilen: 4, 3Die Spalten eines Dataframes können offenbar unterschiedlichen Datentyps sein, dies ist natürlich mit dem Charakter von R Listen kongruent.
Charakterisierung
Mit den Funktionen names() und colnames() können die Namen der Spalten eines Dataframes ausgegeben werden, mit der Funktion rownames() seine Zeilennamen. Per Default sind die Zeilennamen eines Dataframes die ganzen Zahlen 1,2,…,n:
[1] "age" "height" "weight"[1] "age" "height" "weight"[1] "1" "2" "3" "4"Des Weiteren ist ein Dataframe durch die Anzahl seiner Zeilen und Spalten charakterisiert. Diese können mit den Funktionen nrow() bzw. ncol() ausgegeben werden. Die Funktion length() gibt für Dataframes wie für Listen die Anzahl der Listeneinträge, bei Dataframes also entsprechend die Spaltenanzahl, aus.
[1] 4[1] 3[1] 3Eine hilfreiche Funktion zur Charakterisierung eines Dataframes ist die Funktion str(), die in kompakter Form wesentliche Aspekte eines Dataframes anzeigt. str() steht dabei für structure und bezeichnet die Spalten des Dataframes als variables und Zeileneinträge als observations:
Attribute
Technisch sind Dataframes Listen mit Attributen für (column) names und row.names. Dataframes sind von der class “data.frame”:
Indizierung
Dataframes kann man sowohl wie Matrizen als auch wie Listen indizieren. Die Prinzipien der Indizierung entsprechen dabei denen von Vektoren. Folgendes Beispiel zeigt zunächst, wie ein Dataframe im Sinne einer Liste mit einfachen Klammern indiziert wird. Das entsprechende Listenelement ist bei Dataframes dann selbst ein Dataframe:
[1] "data.frame" x
1 a
2 b
3 c
4 d[1] "data.frame"Des Weiteren können Dataframes wie Listen mit doppelten Klammern indiziert werden. Dadurch werden entsprechend die Inhalte eines Listenelements adressiert:
[1] "a" "b" "c" "d"[1] "character"Die typische Indizierung eines Dataframes erfolgt mit der von den Listen bekannten $-Indizierung, die den Inhalt der entsprechenden Dataframe-Spalte adressiert:
[1] 1 2 3 4[1] "integer"Ist man an speziellen Inhalten des Dataframes in spezifischen Zeilen und Spalten interessiert, so bieten sich die Prinzipien der Matrixindizierung an, wie folgendes Beispiel zeigt:
Copy-on-modify
Zur optimalen Nutzung des Arbeitsspeichers gelten die Copy-on-Modify Prinzipien für Listen auch für Dataframes. Weiterhin gilt dabei, dass die Modifikation einer Spalte zur Kopie der entsprechenden Spalte führt, wohingegen die Modifikation einer Zeile in der Kopie des gesamten Dataframes resultiert.
16.3 Tibbles
In Ergänzung zu den R Dataframes haben in den letzten zehn Jahren die Tibbles (diminutiv für tables) als Teil des tidyverse-Pakets Verbreitung gefunden. Tibbles sind eine modernere, technisch verbesserte Form von Dataframes und zeigen, wie R für datenwissenschaftliche Aufgaben über die Anwendung von klassischen linearen Modellen hinaus erweitert wurde. Zur Nutzung von Tibbles muss das tidyverse-Paket installiert und der Tibble-Code geladen sein:
Im Großen und Ganzen entsprechen Tibbles den Dataframes. Wie bei Dataframes handelt es sich bei Tibbles um Listen von Vektorreferenzen, wobei auch hier die Vektoren die gleiche Länge haben und die benannten Spalten einer Tabelle darstellen. Tibbles können mit der Funktion tibble() erzeugt werden. Die Anzeige im R Terminal ist im Vergleich zu Dataframes optimiert, wie folgendes Beispiel zeigt:
# A tibble: 3 × 3
x y z
<chr> <dbl> <lgl>
1 a 1 TRUE
2 c 2 FALSE
3 d 3 FALSE$row.names
[1] 1 2 3
$names
[1] "x" "y" "z"
$class
[1] "tbl_df" "tbl" "data.frame"16.3.1 Tibbles vs. Dataframes
Tibbles wurden 2016 im Rahmen des tidyverse-Pakets eingeführt, um wahrgenommene Schwächen der R Dataframes auszugleichen. Dazu gehörte unter anderem, dass die Funktion data.frame() character-Vektoren automatisiert in den R-Datentyp factor umwandelte. Dies ist seit einer R-Revision von 2019 allerdings nicht mehr der Fall, wie folgendes Beispiel zeigt:
'data.frame': 3 obs. of 2 variables:
$ x: int 1 2 3
$ y: chr "a" "b" "c"Per Default wandelt data.frame() weiterhin nicht zulässige Spaltennamen wie eine Zahl (1) in legale Spaltennamen (X1) um. Möchte man dies nicht, so kann man dieses Verhalten allerdings durch Setzen des Arguments check.names abstellen
[1] "X1"[1] "1"Wie in Kapitel 14 gesehen, hat R die Tendenz, bei von ihrer Länge unpassenden Datentypen selbst Daten durch Recycling zu erzeugen, was leicht zu Fehlern führen kann. So recyclet die Funktion data.frame() bei der Erzeugung eines Dataframes zum Beispiel Vektoren, wenn einer davon ein ganzzahliges Vielfaches des anderen ist:
x y
1 1 3
2 2 4
3 1 5
4 2 6tibble() dagegen ist hier genauer und gibt im obigen Fall einen Fehler aus:
Error in `tibble()`:
! Tibble columns must have compatible sizes.
• Size 2: Existing data.
• Size 4: Column `y`.
ℹ Only values of size one are recycled.Vektoren der Länge 1 werden allerdings auch von tibble() recyclet:
# A tibble: 3 × 2
x y
<int> <dbl>
1 1 3
2 2 3
3 3 3Dataframes sind manchmal inkonsistent, was die von ihnen ausgegebenen Datentypen angeht. So ergibt, wie das untere Beispiel zeigt, die Indizierung einer Dataframespalte mit ihrem Namen etwa einen Dataframe, die Indizierung der gleichen Spalte mit ihrem Namen in Matrixindizierung allerdings einen Vektor:
'data.frame': 3 obs. of 1 variable:
$ x: int 1 2 3 int [1:3] 1 2 3Tibbles sind in dieser Hinsicht konsistenter:
tibble [3 × 1] (S3: tbl_df/tbl/data.frame)
$ x: int [1:3] 1 2 3tibble [3 × 1] (S3: tbl_df/tbl/data.frame)
$ x: int [1:3] 1 2 3Ein zusätzliches Feature von Tibbles gegenüber Dataframes ist, dass die Funktion tibble() es erlaubt, Spaltennamen schon bei Erzeugung eines Tibble zu referenzieren, was bei Dataframes nicht möglich ist.
Error:
! Objekt 'x' nicht gefundenZusammenfassend lässt sich festhalten, dass Tibbles in mancher Hinsicht weniger flexibel und damit präziser als Dataframes funktionieren. Generell verhalten sich Tibbles in tidyverse Kontexten konsistenter als Dataframes. Allerdings sind die Unterschiede zwischen Dataframes und Tibbles wie oben gesehen eher subtil, sodass ein effizienter Umgang mit Dataframes auch einen effizienten Umgang mit Tibbles ermöglicht. Da nicht alle R Projekte die Pakete des tidyverse nutzen, werden wohl auch in Zukunft Dataframes die Standarddatenstruktur für tabellarische Daten in R bleiben.