[,1] [,2] [,3]
[1,] 2 3 0
[2,] 1 6 59 Matrizen
Matrizen sind die Worte der Sprache der modernen Datenanalyse. Ein Verständnis moderner datenanalytischer Verfahren und ihrer Implementation ist ohne ein Grundverständnis des Matrixbegriffs und ein Wissen um die grundlegenden Matrixoperationen nicht möglich. Matrizen können dabei sehr unterschiedliche Rollen spielen. So können Matrizen zum Beispiel Daten, experimentelle Designs und Modellparameter repräsentieren. Im Kontext der Linearen Algebra dienen Matrizen zur Repräsentation linearer Abbildungen und von Vektorräumen, hier werden Vektoren dann als spezielle Matrizen aufgefasst.
In diesem Kapitel geben wir eine Einführung zum Umgang mit Matrizen, wobei wir auf abstrakte Begrifflichkeiten der Linearen Algebra im Wesentlichen verzichten. Wir führen zunächst den Matrixbegriff ein und diskutieren dann mit der Matrixaddition, Matrixsubtraktion, Skalarmultiplikation und der Matrixtransposition erste grundlegende Matrixoperationen (Kapitel 9.1 und Kapitel 9.2). Wir führen dann die zentralen Begriffe der Matrixmultiplikation und der Matrixinversion ein (Kapitel 9.3 und Kapitel 9.4). Mit der Matrixdeterminante diskutieren wir dann in Kapitel 9.5 eine erste Maßzahl zur Beschreibung von Matrizen. Wir schließen in Kapitel 9.6 mit einer Übersicht zu besonders häufig auftretenden Matrizen.
9.1 Definition
Wir beginnen mit der Definition einer Matrix.
Definition 9.1 Eine Matrix ist eine rechteckige Anordnung von Zahlen, die wie folgt bezeichnet wird \[\begin{equation} A := \begin{pmatrix} a_{11} & a_{12} & \cdots & a_{1m} \\ a_{21} & a_{22} & \cdots & a_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nm} \end{pmatrix} := {(a_{ij})}_{1\le i\le n,\, 1\le j\le m}. \end{equation}\]
Matrizen bestehen aus Zeilen (rows) und Spalten (columns). Die Matrixeinträge \(a_{ij}\) werden mit einem Zeilenindex \(i\) und einem Spaltenindex \(j\) indiziert. Zum Beispiel gilt für \[\begin{equation} A:=\begin{pmatrix} 2 & 7 & 5 & 2 \\ 8 & 2 & 5 & 6 \\ 6 & 4 & 0 & 9 \\ 9 & 2 & 1 & 2 \end{pmatrix}, \end{equation}\] dass \(a_{32} = 4\). Die Größe oder Dimension einer Matrix ergibt sich aus der Anzahl ihrer Zeilen \(n \in \mathbb{N}\) und Spalten \(m \in \mathbb{N}\). Matrizen mit \(n = m\) heißen quadratische Matrizen.
In der Folge benötigen wir nur Matrizen mit reellen Einträgen, also \(a_{ij} \in \mathbb{R}\) für alle \(i = 1,...,n\) und \(j = 1,...,m\). Wir nennen die Matrizen mit reellen Einträgen reelle Matrizen und bezeichnen die Menge der reellen Matrizen mit \(n\) Zeilen und \(m\) Spalten mit \(\mathbb{R}^{n \times m}\). An dem Ausdruck \[\begin{equation} A \in \mathbb{R}^{n\times m} \end{equation}\] können wir also ablesen, dass \(A\) eine reelle Matrix mit \(n\) Zeilen und \(m\) Spalten ist. Wir identifizieren dabei die Menge \(\mathbb{R}^{1 \times 1}\) mit der Menge \(\mathbb{R}\), die Menge \(\mathbb{R}^{n \times 1}\) mit der Menge \(\mathbb{R}^n\). Reelle Matrizen mit einer Spalte und \(n\) Zeilen entsprechen also \(n\)-dimensionalen reellen Vektoren und reelle Matrizen mit einer Spalte und einer Zeile entsprechen reellen Zahlen.
Definition von Matrizen in R
In R werden Matrizen definiert, indem R Vektoren mithilfe der matrix() Funktion in die Repräsentation einer mathematischen Matrix transformiert werden. Die Einträge eines R Vektors werden dabei anhand der spezifizierten Zeilenanzahl nrow entsprechend ihrer Gesamtanzahl auf die Matrix verteilt. Wollen wir beispielsweise die Matrix \[\begin{equation}
A :=
\begin{pmatrix}
2 & 3 & 0 \\
1 & 6 & 5
\end{pmatrix}
\end{equation}\] in R definieren, so ergibt sich
R folgt hier per default einer sogenannten column-major-order, das heißt, die Elemente des R Vektors c(2,1,3,6,0,5) werden der Reihe nach von oben nach unten in die Spalten der Matrix von links nach rechts überführt. Einen etwas klareren Zusammenhang zwischen dem visuellen Layout des R Codes und der resultierenden Matrix erhält man, indem man den R Vektor mithilfe von Zeilenumbrüchen anhand des intendierten Matrixlayouts formatiert und dann die column-major-order mithilfe des Arguments byrow = TRUE zu einer row-major-order umstellt. Es wird dann zunächst die erste Zeile der Matrix von links nach rechts mit den Elementen des R Vektors gefüllt und dann die zweite Zeile usw. bis alle Elemente des Vektors auf die Matrix verteilt sind.
[,1] [,2] [,3]
[1,] 2 3 0
[2,] 1 6 59.2 Grundlegende Matrixoperationen
Man kann mit Matrizen rechnen. Dabei sind folgende Matrixoperationen grundlegend:
- Die Addition von Matrizen gleicher Größe, genannt Matrixaddition,
- die Subtraktion von Matrizen gleicher Größe, genannt Matrixsubtraktion,
- die Multiplikation einer Matrix mit einem Skalar, genannt Skalarmultiplikation,
- das Vertauschen der Zeilen und Spalten einer Matrix, genannt Matrixtransposition.
Wir führen diese Operationen in der Folge in Operatorform, also als Funktionen ein. Dies dient insbesondere dazu, bei jeder Operation mit Hilfe ihrer Definitionsmenge zu betonen, von welcher Art die Objekte der jeweiligen Operation sind und mithilfe ihrer Bildmenge zu betonen, von welcher Art das Resultat der jeweiligen Operation ist.
9.2.1 Matrixaddition
Definition 9.2 Es seien \(A,B\in \mathbb{R}^{n\times m}\). Dann ist die Addition von \(A\) und \(B\) definiert als die Abbildung \[\begin{equation} + : \mathbb{R}^{n\times m} \times \mathbb{R}^{n\times m} \to \mathbb{R}^{n \times m}, \, (A,B) \mapsto +(A,B) := A + B \end{equation}\] mit \[\begin{align} \begin{split} A + B & = \begin{pmatrix} a_{11} & a_{12} & \cdots & a_{1m} \\ a_{21} & a_{22} & \cdots & a_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nm} \end{pmatrix} + \begin{pmatrix} b_{11} & b_{12} & \cdots & b_{1m} \\ b_{21} & b_{22} & \cdots & b_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ b_{n1} & b_{n2} & \cdots & b_{nm} \end{pmatrix} \\ & := \begin{pmatrix} a_{11} + b_{11} & a_{12} + b_{12} & \cdots & a_{1m} + b_{1m} \\ a_{21} + b_{21} & a_{22} + b_{22} & \cdots & a_{2m} + b_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} + b_{n1} & a_{n2} + b_{n2} & \cdots & a_{nm} + b_{nm} \end{pmatrix}. \end{split} \end{align}\]
Die Definition der Matrixaddition legt insbesondere fest, dass nur Matrizen gleicher Größe addiert werden können und dass die Operation der Matrixaddition elementweise definiert ist.
Beispiel
Es seien \(A,B\in \mathbb{R}^{2\times 3}\) definiert als \[\begin{equation} A:=\begin{pmatrix} 2 & -3 & 0\\ 1 & 6 & 5\\ \end{pmatrix} \mbox{ und } B := \begin{pmatrix} 4 & 1 & 0\\ -4 & 2 & 0\\ \end{pmatrix}. \end{equation}\] Da \(A\) und \(B\) gleich groß sind, können wir sie addieren \[\begin{align} \begin{split} C = A+B & = \begin{pmatrix} 2 & -3 & 0\\ 1 & 6 & 5\\ \end{pmatrix} + \begin{pmatrix} 4 & 1 & 0\\ -4 & 2 & 0\\ \end{pmatrix}\\ & = \begin{pmatrix} 2 + 4 & -3 + 1 & 0 + 0\\ 1 - 4 & 6 + 2 & 5 + 0\\ \end{pmatrix}\\ & = \begin{pmatrix} 6 & -2 & 0\\ -3 & 8 & 5 \\ \end{pmatrix}. \end{split} \end{align}\]
In R führt man obige Rechnung wie folgt aus.
9.2.2 Matrixsubtraktion
Die Subtraktion von Matrizen gleicher Größe ist analog zur Addition definiert.
Definition 9.3 (Matrixsubtraktion) Es seien \(A,B\in \mathbb{R}^{n\times m}\). Dann ist die Subtraktion von \(A\) und \(B\) definiert als die Abbildung \[\begin{equation} - : \mathbb{R}^{n\times m} \times \mathbb{R}^{n\times m} \to \mathbb{R}^{n\times m}, \, (A,B) \mapsto -(A,B) := A - B \end{equation}\] mit \[\begin{align} \begin{split} A - B & = \begin{pmatrix} a_{11} & a_{12} & \cdots & a_{1m} \\ a_{21} & a_{22} & \cdots & a_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nm} \end{pmatrix} - \begin{pmatrix} b_{11} & b_{12} & \cdots & b_{1m} \\ b_{21} & b_{22} & \cdots & b_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ b_{n1} & b_{n2} & \cdots & b_{nm} \end{pmatrix} \\ & := \begin{pmatrix} a_{11} - b_{11} & a_{12} - b_{12} & \cdots & a_{1m} - b_{1m} \\ a_{21} - b_{21} & a_{22} - b_{22} & \cdots & a_{2m} - b_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} - b_{n1} & a_{n2} - b_{n2} & \cdots & a_{nm} - b_{nm} \end{pmatrix}. \end{split} \end{align}\]
Wie bei der Matrixaddition legt die Definition der Matrixsubtraktion fest, dass nur Matrizen gleicher Größe voneinander subtrahiert werden können und dass die Subtraktion zweier gleich großer Matrizen elementweise definiert ist.
Beispiel
Wir können die im Beispiel zur Matrixaddition definierten Matrizen \(A\) und \(B\) auch voneinander subtrahieren, \[\begin{align} \begin{split} D = A-B & = \begin{pmatrix} 2 & -3 & 0\\ 1 & 6 & 5\\ \end{pmatrix} - \begin{pmatrix} 4 & 1 & 0\\ -4 & 2 & 0\\ \end{pmatrix}\\ & = \begin{pmatrix} 2 - 4 & -3 - 1 & 0 - 0\\ 1 + 4 & 6 - 2 & 5 - 0\\ \end{pmatrix}\\ & = \begin{pmatrix} -2 & -4 & 0\\ 5 & 4 & 5 \\ \end{pmatrix}. \end{split} \end{align}\]
In R führt man diese Rechnung wie folgt aus.
9.2.3 Skalarmultiplikation
Die Skalarmultiplikation einer Matrix bezeichnet die Multiplikation eines Skalars mit einer Matrix.
Definition 9.4 (Skalarmultiplikation) Es sei \(c \in \mathbb{R}\) ein Skalar und \(A \in \mathbb{R}^{n\times m}\). Dann ist die Skalarmultiplikation von \(c\) und \(A\) definiert als die Abbildung \[\begin{equation} \cdot : \mathbb{R} \times \mathbb{R}^{n\times m} \to \mathbb{R}^{n\times m}, \, (c,A) \mapsto \cdot (c,A) := cA \end{equation}\] mit \[\begin{align} \begin{split} cA = c \begin{pmatrix} a_{11} & a_{12} & \cdots & a_{1m} \\ a_{21} & a_{22} & \cdots & a_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nm} \end{pmatrix} := \begin{pmatrix} ca_{11} & ca_{12} & \cdots & ca_{1m} \\ ca_{21} & ca_{22} & \cdots & ca_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ ca_{n1} & ca_{n2} & \cdots & ca_{nm} \end{pmatrix}. \end{split} \end{align}\]
Die Skalarmultiplikation ist mit dieser Definition also elementweise definiert.
Beispiel
Es seien \(c:=-3\) und \(A\in \mathbb{R}^{4\times 3}\) definiert als
\[\begin{equation} A := \begin{pmatrix} 3 & 1 & 1\\ 5 & 2 & 5\\ 2 & 7 & 1\\ 3 & 4 & 2 \end{pmatrix}. \end{equation}\] Dann ergibt sich \[\begin{align} \begin{split} B := cA = -3\begin{pmatrix} 3 & 1 & 1\\ 5 & 2 & 5\\ 2 & 7 & 1\\ 3 & 4 & 2 \end{pmatrix} = \begin{pmatrix} -3\cdot3 & -3\cdot1 & -3\cdot1\\ -3\cdot5 & -3\cdot2 & -3\cdot5\\ -3\cdot2 & -3\cdot7 & -3\cdot1\\ -3\cdot3 & -3\cdot4 & -3\cdot2 \end{pmatrix} = \begin{pmatrix} -9 & -3 & -3 \\ -15 & -6 & -15 \\ -6 & -21 & -3 \\ -9 & -12 & -6 \end{pmatrix}. \end{split} \end{align}\]
In R führt man diese Skalarmultiplikation aus wie folgt.
[,1] [,2] [,3]
[1,] -9 -3 -3
[2,] -15 -6 -15
[3,] -6 -21 -3
[4,] -9 -12 -6Mithilfe der Definition von Matrixaddition und Skalarmultiplikation ist es möglich, einen Vektorraum zu definieren, dessen Elemente die reellen Matrizen sind. Insbesondere legt diese Definition auch die Rechenregeln beim Umgang mit Matrixaddition und Skalarmultiplikation fest.
Theorem 9.1 (Vektorraum der reellwertigen Matrizen) Das Tripel \((\mathbb{R}^{n \times m}, +, \cdot)\) mit der oben definierten Matrixaddition und Skalarmultiplikation ist ein Vektorraum. Insbesondere gelten damit für \(A,B,C\in \mathbb{R}^{n \times m}\) und \(r,s,t\in \mathbb{R}\) folgende Rechenregeln:
- Kommutativität der Addition: \(A + B = B + A\).
- Assoziativität der Addition: \((A + B) + C = A + (B + C)\).
- Existenz eines neutralen Elements der Addition: \(\exists\, 0 \in \mathbb{R}^{n \times m}\) mit \(A + 0 = 0 + A = A\).
- Existenz inverser Elemente der Addition: \(\forall A\,\exists -A \in \mathbb{R}^{n \times m}\) mit \(A + (-A) = 0\).
- Existenz eines neutralen Elements der Skalarmultiplikation: \(\exists\, 1 \in \mathbb{R}\) mit \(1 \cdot A = A\).
- Assoziativität der Skalarmultiplikation: \(r \cdot (s \cdot A) = (r \cdot s)\cdot A\).
- Distributivität hinsichtlich der Matrixaddition: \(r\cdot (A + B) = r\cdot A + r\cdot B\).
- Distributivität hinsichtlich der Skalaraddition: \((r + s)\cdot A = r\cdot A + s\cdot A\).
Wir verzichten auf einen Beweis, der sich mit einigem Notationsaufwand direkt aus dem elementweisen Charakter von Matrixaddition und Skalarmultiplikation sowie den aus dem Umgang mit den reellen Zahlen bekannten Rechenregeln ergibt. Das im Theorem erwähnte neutrale Element der Addition wird Nullmatrix genannt, wir werden dazu später eine allgemeine Notation einführen. Die inversen Elemente der Addition sind durch \[\begin{equation} -A := (-a_{ij})_{1\le i \le n, 1 \le j \le m} \end{equation}\] gegeben und erlauben es, die Matrixsubtraktion als Spezialfall der Matrixaddition zu betrachten.
9.2.4 Matrixtransposition
Eine weitere häufig auftretende grundlegende Matrixoperation ist das Vertauschen der Zeilen- und Spaltenanordnung einer Matrix, genannt Matrixtransposition.
Definition 9.5 (Matrixtransposition) Es sei \(A \in \mathbb{R}^{n\times m}\). Dann ist die Transposition von \(A\) definiert als die Abbildung \[\begin{equation} \cdot^{T} : \mathbb{R}^{n\times m} \to \mathbb{R}^{m \times n}, \, A \mapsto \cdot^{T}(A) := A^T \end{equation}\] mit \[\begin{align} \begin{split} A^T = \begin{pmatrix} a_{11} & a_{12} & \cdots & a_{1m} \\ a_{21} & a_{22} & \cdots & a_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nm} \end{pmatrix}^T := \begin{pmatrix} a_{11} & a_{21} & \cdots & a_{n1} \\ a_{12} & a_{22} & \cdots & a_{n2} \\ \vdots & \vdots & \ddots & \vdots \\ a_{1m} & a_{2m} & \cdots & a_{nm} \end{pmatrix}. \end{split} \end{align}\]
Für \(A \in \mathbb{R}^{n \times m}\) gilt damit also immer \(A^T \in \mathbb{R}^{m \times n}\). Weiterhin gelten folgende Rechenregeln der Matrixtransposition, wie man sich an Beispielen klar macht:
- Für \(A \in \mathbb{R}^{1 \times 1}\) gilt \[\begin{equation} A^T = A. \end{equation}\]
- Es gilt \[\begin{equation} \left(A^T\right)^T = A. \end{equation}\]
- Es gilt \[\begin{equation} \left(a_{ii}\right)_{1 \le i \le \mbox{min}(n,m)} = \left(a_{ii}\right)^T_{1 \le i \le \mbox{min}(n,m)}. \end{equation}\]
Letztere Eigenschaft der Transposition besagt, dass die Elemente auf der Hauptdiagonalen einer Matrix bei Transposition unberührt bleiben.
Beispiel
Es sei \(A \in \mathbb{R}^{2 \times 3}\) definiert durch \[\begin{equation} A:=\begin{pmatrix} 2 & 3 & 0 \\ 1 & 6 & 5 \\ \end{pmatrix}, \end{equation}\] Dann gilt \(A^T \in \mathbb{R}^{3 \times 2}\) und speziell \[\begin{equation} A^{T} := \begin{pmatrix} 2 & 1 \\ 3 & 6 \\ 0 & 5 \\ \end{pmatrix}. \end{equation}\] Weiterhin gilt offenbar \(\min(m,n) = 2\) und folglich \[\begin{equation} (a_{11}) = \left(a_{11}\right)^T \mbox{ und } (a_{22}) = \left(a_{22}\right)^T. \end{equation}\] In R führt man die Transposition einer Matrix wie folgt durch.
[,1] [,2] [,3]
[1,] 2 3 0
[2,] 1 6 5 [,1] [,2]
[1,] 2 1
[2,] 3 6
[3,] 0 5Schließlich gelten in der Verbindung mit der Matrixaddition, Matrixsubtraktion und der Skalarmultiplikation folgende Rechenregeln, wie man sich an Beispielen klar macht:
- Für \(A,B\in \mathbb{R}^{n \times m}\) gilt \[\begin{equation} (A+B)^T = A^T + B^T. \end{equation}\]
- Für \(A,B\in \mathbb{R}^{n \times m}\) gilt \[\begin{equation} (A-B)^T = A^T - B^T. \end{equation}\]
- Für \(c\in \mathbb{R}\) und \(A \in \mathbb{R}^{n \times m}\) gilt \[\begin{equation} (cA)^T = cA^T. \end{equation}\]
9.3 Matrixmultiplikation
Die Matrixmultiplikation ist die zentrale Operation beim Rechnen mit Matrizen. Sie ist definiert wie folgt.
Definition 9.6 (Matrixmultiplikation) Es seien \(A\in \mathbb{R}^{n \times m}\) und \(B \in \mathbb{R}^{m \times k}\). Dann ist die Matrixmultiplikation von \(A\) und \(B\) definiert als die Abbildung \[\begin{equation} \cdot : \mathbb{R}^{n\times m} \times \mathbb{R}^{m\times k} \to \mathbb{R}^{n \times k}, \, (A,B) \mapsto \cdot(A,B) := AB \end{equation}\] mit \[\begin{align} \begin{split} AB & = \begin{pmatrix} a_{11} & a_{12} & \cdots & a_{1m} \\ a_{21} & a_{22} & \cdots & a_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nm} \end{pmatrix} \begin{pmatrix} b_{11} & b_{12} & \cdots & b_{1k} \\ b_{21} & b_{22} & \cdots & b_{2k} \\ \vdots & \vdots & \ddots & \vdots \\ b_{m1} & b_{m2} & \cdots & b_{mk} \end{pmatrix} \\ & := \begin{pmatrix} \sum_{i=1}^m a_{1i}b_{i1} & \sum_{i=1}^m a_{1i}b_{i2} & \cdots & \sum_{i=1}^m a_{1i}b_{ik} \\ \sum_{i=1}^m a_{2i}b_{i1} & \sum_{i=1}^m a_{2i}b_{i2} & \cdots & \sum_{i=1}^m a_{2i}b_{ik} \\ \vdots & \vdots & \ddots & \vdots \\ \sum_{i=1}^m a_{ni}b_{i1} & \sum_{i=1}^m a_{ni}b_{i2} & \cdots & \sum_{i=1}^m a_{ni}b_{ik} \end{pmatrix} \\ & = \left(\sum_{i=1}^m a_{ji}b_{il} \right)_{1 \le j \le n, 1 \le l \le k} \end{split} \end{align}\]
Das Matrixprodukt \(AB\) ist also nur dann definiert, wenn \(A\) genau so viele Spalten hat wie \(B\) Zeilen hat. Informell gilt für die beteiligten Matrixgrößen dabei die Merkregel \[\begin{equation} (n \times m)(m \times k) = (n \times k). \end{equation}\] Der Eintrag \((AB)_{ij}\) in \(AB\) entspricht der Summe der multiplizierten \(i\)ten Zeile von \(A\) und \(j\)ten Spalte von \(B\). Zum Berechnen von \((AB)_{ij}\) geht man für \(i = 1,...,n\) und \(j = 1,...,k\) also in Gedanken wie folgt vor:
- Man legt die Transposition der \(i\)ten Zeile von \(A\) über die \(j\)te Spalte von \(B\).
- Weil \(A\) genau \(m\) Spalten hat und \(B\) genau \(m\) Zeilen hat, gibt es dann zu jedem Element der Zeile aus \(A\) ein korrespondierendes Element in der Spalte von \(B\).
- Man multipliziert die korrespondierenden Elemente miteinander.
- Die Summe dieser Produkte ist dann der Eintrag mit Index \(ij\) in \(AB\).
Beispiel
\(A\in \mathbb{R}^{2\times 3}\) und \(B\in \mathbb{R}^{3\times 2}\) seien definiert als \[\begin{equation} A := \begin{pmatrix} 2 & -3 & 0 \\ 1 & 6 & 5 \end{pmatrix} \mbox{ und } B := \begin{pmatrix} 4 & 2 \\ -1 & 0 \\ 1 & 3 \end{pmatrix}. \end{equation}\] Wir wollen \(C := AB\) und \(D := BA\) berechnen. Mit \(n = 2, m = 3\) und \(k = 2\) wissen wir schon, dass \(C \in \mathbb{R}^{2 \times 2}\) und \(D \in \mathbb{R}^{3 \times 3}\), weil \[\begin{equation} (2 \times 3)(3 \times 2) = (2 \times 2) \end{equation}\] und \[\begin{equation} (3 \times 2)(2 \times 3) = (3 \times 3). \end{equation}\] Es gilt hier also sicher \(AB \neq BA\). Für \(C\) ergibt sich dann \[\begin{align} \begin{split} C & = AB \\ & = \begin{pmatrix} 2 & -3 & 0 \\ 1 & 6 & 5 \\ \end{pmatrix} \begin{pmatrix} 4 & 2 \\ -1 & 0 \\ 1 & 3 \end{pmatrix} \\ & = \begin{pmatrix} 2\cdot 4 + (-3)\cdot (-1) + 0\cdot 1 & 2\cdot 2 + (-3)\cdot 0 + 0\cdot 3 \\ 1\cdot 4 + 6\cdot (-1) + 5\cdot 1 & 1\cdot 2 + 6\cdot 0 + 5\cdot 3 \\ \end{pmatrix} \\ & = \begin{pmatrix} 8 + 3 + 0 & 4 + 0 + 0 \\ 4 - 6 + 5 & 2 + 0 + 15 \\ \end{pmatrix} \\ & = \begin{pmatrix} 11 & 4 \\ 3 & 17 \\ \end{pmatrix}. \end{split} \end{align}\]
In R nutzt man für die Matrixmultiplikation den %*% Operator.
[,1] [,2]
[1,] 11 4
[2,] 3 17Für \(D\) ergibt sich weiterhin \[\begin{align} \begin{split} D & = BA \\ & = \begin{pmatrix} 4 & 2 \\ -1 & 0 \\ 1 & 3 \end{pmatrix} \begin{pmatrix} 2 & -3 & 0 \\ 1 & 6 & 5 \\ \end{pmatrix} \\ & = \begin{pmatrix} 4 \cdot 2 + 2 \cdot 1 & 4 \cdot (-3) + 2 \cdot 6 & 4 \cdot 0 + 2 \cdot 5 \\ (-1) \cdot 2 + 0 \cdot 1 & (-1) \cdot(-3) + 0 \cdot 6 & (-1) \cdot 0 + 0 \cdot 5 \\ 1 \cdot 2 + 3 \cdot 1 & 1 \cdot(-3) + 3 \cdot 6 & 1 \cdot 0 + 3 \cdot 5 \end{pmatrix} \\ & = \begin{pmatrix} 8 + 2 & -12 + 12 & 0 + 5 \\ -2 + 0 & 3 + 0 & 0 + 0 \\ 2 + 3 & -3 + 18 & 0 + 15 \end{pmatrix} \\ & = \begin{pmatrix} 10 & 0 & 10 \\ -2 & 3 & 0 \\ 5 & 15 & 15 \\ \end{pmatrix} \end{split} \end{align}\]
In R überprüft man diese Rechnung wie folgt.
[,1] [,2] [,3]
[1,] 10 0 10
[2,] -2 3 0
[3,] 5 15 15Ist allerdings eine Matrixmultiplikation aufgrund nicht-adäquater Matrizengrößen nicht definiert, so lässt sich diese auch nicht numerisch auswerten.
Error in `t(A) %*% B`:
! nicht passende ArgumenteFolgendes Theorem, das wir nicht beweisen wollen, stellt den Bezug zwischen dem Skalarprodukt zweier Vektoren und der Multiplikation zweier Matrizen her. Dieser ergibt sich im Wesentlichen durch die Identifikation von \(\mathbb{R}^{n}\) und \(\mathbb{R}^{n \times 1}\) und der Tatsache, dass nach Definition der Eintrag \((AB)_{ij}\) im Produkt von \(A \in \mathbb{R}^{n \times m}\) und \(B \in \mathbb{R}^{m \times k}\) dem Vektorskalarprodukt der \(i\)ten Spalte von \(A^T\) und der \(j\)ten Spalte von \(B\) entspricht.
Theorem 9.2 (Matrixmultiplikation und Vektorskalarprodukt) Es seien \(x,y \in \mathbb{R}^n\). Dann gilt \[\begin{equation} \langle x,y \rangle = x^Ty. \end{equation}\] Weiterhin seien für \(A \in \mathbb{R}^{n\times m}\) für \(i = 1,...,n\) \[\begin{equation} \bar{a}_i := (a_{ij})_{1 \le j \le m} \in \mathbb{R}^m \end{equation}\] die Spalten von \(A^T\) und für \(B \in \mathbb{R}^{m \times k}\) für \(j = 1,...,k\) \[\begin{equation} \bar{b}_j := (b_{ij})_{1 \le i \le m} \in \mathbb{R}^m \end{equation}\] die Spalten von \(B\), also \[\begin{equation} A^T = \begin{pmatrix} \bar{a}_1 & \bar{a}_2 & \cdots & \bar{a}_n \end{pmatrix} \in \mathbb{R}^{m \times n} \mbox{ und } B = \begin{pmatrix} \bar{b}_1 & \bar{b}_2 & \cdots & \bar{b}_k \end{pmatrix} \in \mathbb{R}^{m \times k}. \end{equation}\] Dann gilt \[\begin{equation} AB = \left(\langle \bar{a}_i,\bar{b}_j \rangle \right)_{1 \le i \le n, 1 \le j \le k}. \end{equation}\]
9.3.1 Rechenregeln der Matrixmultiplikation
Im Folgenden stellen wir einige grundlegende Rechenregeln der Matrixmultiplikation, insbesondere auch in Kombination mit anderen Matrixoperationen zusammen.
Für Beweise der folgenden zwei Theoreme zur Assoziativität und Distributivität, die sich im Wesentlichen mit den entsprechenden Rechenregeln für Summen und Produkte der reellen Zahlen ergeben, verweisen wir auf die weiterführende Literatur.
Theorem 9.3 (Assoziativität) Es seien \(A \in \mathbb{R}^{n \times m}\), \(B \in \mathbb{R}^{m \times k}\), \(C \in \mathbb{R}^{k \times p}\) und \(c \in \mathbb{R}\). Dann gelten
- Die Multiplikation von Matrizen ist assoziativ, es gilt \[\begin{equation} A(BC) = (AB)C. \end{equation}\]
- Die Kombination von Matrizenmultiplikation und Skalarmultiplikation ist assoziativ, \[\begin{equation} c(AB) = (cA)B = A(cB). \end{equation}\]
Die Assoziativität von Matrizenmultiplikation und Skalarmultiplikation erkennt man leicht bei Betrachtung des \(j,l\)ten Elements von \(c(AB), (cA)B\) und \(A(cB)\) anhand von \[\begin{equation} c\left(\sum_{i = 1}^m a_{ji}b_{il}\right) = \sum_{i = 1}^m \left(c a_{ji}\right) b_{il} = \sum_{i = 1}^m a_{ji}\left(c b_{il}\right). \end{equation}\]
Theorem 9.4 (Distributivität) Es seien \(A \in \mathbb{R}^{n \times m}\), \(B \in \mathbb{R}^{n \times m}\), \(C \in \mathbb{R}^{m \times p}\). Dann gelten \[\begin{equation} (A + B)C = AC + BC \end{equation}\] und \[\begin{equation} C^T(A + B) = C^TA + C^TB \end{equation}\]
Im Gegensatz zur Kommutativität der Multiplikation reeller Zahlen ist die Matrixmultiplikation im Allgemeinen nicht kommutativ.
Theorem 9.5 (Nichtkommutativität) Es seien \(A \in \mathbb{R}^{n \times m}\) und \(B \in \mathbb{R}^{m \times p}\). Dann gilt im Allgemeinen \[\begin{equation} AB \neq BA. \end{equation}\]
Beweis. Im Fall \(p \neq n\) ist \(BA\) nicht definiert, wir betrachten also nur den Fall \(p = n\). Wir zeigen durch Angabe eines Gegenbeispiels mit \(A,B\in \mathbb{R}^{2 \times 2}\), dass im Allgemeinen \(AB = BA\) nicht gilt. Es seien \[\begin{equation} A := \begin{pmatrix} 0 & 1 \\ 0 & 0 \end{pmatrix} \mbox{ und } B := \begin{pmatrix} 0 & 0 \\ 1 & 0 \end{pmatrix}. \end{equation}\] Dann gilt \[\begin{equation} AB = \begin{pmatrix} 0 & 1 \\ 0 & 0 \end{pmatrix} \begin{pmatrix} 0 & 0 \\ 1 & 0 \end{pmatrix} = \begin{pmatrix} 1 & 0 \\ 0 & 0 \end{pmatrix} \neq \begin{pmatrix} 0 & 0 \\ 0 & 1 \end{pmatrix} = \begin{pmatrix} 0 & 0 \\ 1 & 0 \end{pmatrix} \begin{pmatrix} 0 & 1 \\ 0 & 0 \end{pmatrix} = BA. \end{equation}\]
Theorem 9.6 (Kombination von Matrixmultiplikation und Transposition) Es seien \(A \in \mathbb{R}^{m \times n}\) und \(B \in \mathbb{R}^{n \times k}\). Dann gilt \[\begin{equation} (AB)^T = B^TA^T. \end{equation}\]
Beweis. Ein Beweis ergibt sich wie folgt \[\begin{align} \begin{split} (AB)^T & = \left(\left(\sum_{i=1}^n a_{ji}b_{il} \right)_{1 \le j \le m, 1 \le l \le k}\right)^T \\ & = \left(\sum_{i=1}^n a_{li}b_{ij} \right)_{1 \le j \le k, 1 \le l \le m} \\ & = \left(\sum_{i=1}^n b_{ij}a_{li} \right)_{1 \le j \le k, 1 \le l \le m} \\ & = B^TA^T. \end{split} \end{align}\]
9.4 Matrixinversion
Um den Begriff der inversen Matrix zu motivieren, betrachten wir zunächst das Problem des Lösens eines linearen Gleichungssystems. Dazu seien \(A\in \mathbb{R}^{n \times n},\, x \in \mathbb{R}^n\) und \(b \in \mathbb{R}^n\) und es gelte \[\begin{equation} Ax = b. \end{equation}\] \(A\) und \(b\) seien als bekannt vorausgesetzt, \(x\) sei unbekannt. Konkret seien beispielsweise \[\begin{equation} A := \begin{pmatrix} 1 & 2 \\ 3 & 4 \end{pmatrix} \mbox{ und } b := \begin{pmatrix} 5 \\ 11 \end{pmatrix}. \end{equation}\]
Dann liegt folgendes lineares Gleichungssystem mit zwei Gleichungen und zwei Unbekannten vor: \[\begin{equation} Ax = b \Leftrightarrow \begin{pmatrix} 1 & 2 \\ 3 & 4 \end{pmatrix} \begin{pmatrix} x_1 \\ x_2 \end{pmatrix} = \begin{pmatrix} 5 \\ 11 \end{pmatrix} \Leftrightarrow \begin{matrix} 1x_1 + 2x_2 & = 5 \\ 3x_1 + 4x_2 & = 11 \end{matrix}. \end{equation}\]
Ziel des Lösens von linearen Gleichungssystemen ist bekanntlich, herauszufinden, für welche \(x\) das Gleichungssystem erfüllt ist. Um in diesem Kontext den Begriff der inversen Matrix von \(A\) einzuführen, vereinfachen wir die Situation weiter. Wir nehmen an, dass \(A = a\) eine \(1 \times 1\) Matrix, also ein Skalar, sei und ebenso \(x\) und \(b\), dass wir also für \(a,x,b \in \mathbb{R}\) die Gleichung \[\begin{equation} ax = b \end{equation}\] haben. Um diese Gleichung nach \(x\) aufzulösen würde man natürlich beide Seiten der Gleichung mit dem multiplikativen Inversen von \(a\) multiplizieren, wobei das multiplikative Inverse von \(a\) den Wert bezeichnet, der mit \(a\) multipliziert \(1\) ergibt. Dieser ist bekanntlich durch \[\begin{equation} a^{-1} = \frac{1}{a} \end{equation}\] gegeben. Dann würde gelten \[\begin{equation} ax = b \Leftrightarrow a^{-1}ax = a^{-1}b \Leftrightarrow 1 \cdot x = a^{-1}b \Leftrightarrow x = \frac{b}{a}. \end{equation}\] Ganz konkret etwa \[\begin{equation} 2x = 6 \Leftrightarrow 2^{-1} 2x = 2^{-1}6 \Leftrightarrow \frac{1}{2}2x = \frac{1}{2}6 \Leftrightarrow x = 3. \end{equation}\] Analog zu dem Fall, dass die Matrizen in \(Ax = b\) allesamt Skalare sind, möchte man im Fall eines linearen Gleichungssystems beide Seiten der Gleichung mit dem multiplikativen Inversen \(A^{-1}\) von \(A\) multiplizieren können, sodass eine Gleichung der Form \[\begin{equation} A^{-1}A = "1". \end{equation}\] resultiert. Dann hätte man nämlich \[\begin{equation} Ax = b \Leftrightarrow A^{-1}Ax = A^{-1}b \Leftrightarrow x = A^{-1}b. \end{equation}\] Diese intuitive Idee des multiplikativen Inversen einer Matrix \(A\) wird im Folgenden unter dem Begriff der inversen Matrix formalisiert. Dazu benötigen wir zunächst den Begriff der Einheitsmatrix.
Definition 9.7 (Einheitsmatrix) Die Matrix \[\begin{equation} I_n := (a_{ij})_{1\le i \le n, 1 \le j \le n} \in \mathbb{R}^{n \times n} := \begin{pmatrix} 1 & 0 & \cdots & 0 \\ 0 & 1 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & 1 \\ \end{pmatrix} \end{equation}\] mit \(a_{ij} = 1\) für \(i = j\) und \(a_{ij} = 0\) für \(i \neq j\) heißt \(n\)-dimensionale Einheitsmatrix.
In R wird \(I_n\) mit dem Befehl diag(n) erzeugt. Die Einheitsmatrix ist für die Matrixmultiplikation das Analog zur 1 bei der Multiplikation reeller Zahlen. Das ist die Aussage des folgenden Theorems.
Theorem 9.7 (Neutrales Element der Matrixmultiplikation) \(I_n\) ist das neutrale Element der Matrixmultiplikation, das heißt es gilt für \(A \in \mathbb{R}^{n \times m}\), dass \[\begin{equation} I_nA = A \mbox{ und } AI_m = A. \end{equation}\]
Beweis. Es sei \(B = (b_{ij}) = I_nA \in \mathbb{R}^{n\times m}\). Dann gilt für alle \(1 \le i \le n\) und alle \(1 \le j \le m\) \[\begin{equation} b_{ij} = 0 \cdot a_{1j} + 0 \cdot a_{2j} + \cdots + 0 \cdot a_{i-1,j} + 1 \cdot a_{ij} + \cdots + 0 \cdot a_{i+1,j} + 0 \cdot a_{nj} = a_{ij}. \end{equation}\] Analog zeigt man dies für \(AI_m\).
Mit dem Begriff der Einheitsmatrix können wir jetzt die Begriffe der inversen Matrix und der invertierbaren Matrix definieren:
Definition 9.8 (Invertierbare Matrix und inverse Matrix) Eine quadratische Matrix \(A \in \mathbb{R}^{n \times n}\) heißt invertierbar, wenn es eine quadratische Matrix \(A^{-1} \in \mathbb{R}^{n \times n}\) gibt, so dass \[\begin{equation} A^{-1}A = AA^{-1} = I_n \end{equation}\] ist. Die Matrix \(A^{-1}\) heißt die inverse Matrix von \(A\).
Man beachte, dass sich die Begriffe der inversen Matrix und der Invertierbarkeit nur auf quadratische Matrizen beziehen. Insbesondere können quadratische Matrizen invertierbar sein, müssen es aber nicht sein (lineare Gleichungssysteme können also Lösungen haben, müssen es aber nicht). Nicht invertierbare Matrizen nennt man auch singuläre Matrizen, invertierbare Matrizen manchmal auch nicht-singuläre Matrizen. Schließlich beachte man, dass Definition 9.8 lediglich aussagt, was eine inverse Matrix ist, aber nicht wie man sie berechnet.
Beispiel für eine invertierbare Matrix
Die Matrix \[\begin{equation} A := \begin{pmatrix} 2.0 & 1.0 \\ 3.0 & 4.0 \end{pmatrix} \end{equation}\] ist invertierbar und ihre inverse Matrix ist gegeben durch \[\begin{equation} A^{-1} = \begin{pmatrix} 0.8 & -0.2 \\ -0.6 & 0.4 \end{pmatrix}, \end{equation}\] denn \[\begin{equation} \begin{pmatrix} 2.0 & 1.0 \\ 3.0 & 4.0 \end{pmatrix} \begin{pmatrix} 0.8 & -0.2 \\ -0.6 & 0.4 \end{pmatrix} = \begin{pmatrix} 1 & 0 \\ 0 & 1 \end{pmatrix} = \begin{pmatrix} 0.8 & -0.2 \\ -0.6 & 0.4 \end{pmatrix} \begin{pmatrix} 2.0 & 1.0 \\ 3.0 & 4.0 \end{pmatrix}, \end{equation}\] wovon man sich durch Nachrechnen überzeugt.
Beispiel für eine nicht-invertierbare Matrix
Die Matrix \[\begin{equation} B := \begin{pmatrix} 1 & 0 \\ 0 & 0 \end{pmatrix} \end{equation}\] ist nicht invertierbar, denn wäre \(B\) invertierbar, dann gäbe es \[\begin{equation} \begin{pmatrix} a & b \\ c & d \end{pmatrix} \end{equation}\] mit \[\begin{equation} \begin{pmatrix} 1 & 0 \\ 0 & 0 \end{pmatrix} \begin{pmatrix} a & b \\ c & d \end{pmatrix} = \begin{pmatrix} a & b \\ 0 & 0 \end{pmatrix} = \begin{pmatrix} 1 & 0 \\ 0 & 1 \end{pmatrix}. \end{equation}\] Das würde aber bedeuten, dass \(0 = 1\) in \(\mathbb{R}\) und das ist ein Widerspruch. Also kann \(B\) nicht invertierbar sein.
Zum Berechnen inverser Matrizen
\(2 \times 2\) bis etwa \(5 \times 5\) Matrizen kann man prinzipiell per Hand invertieren, dazu stellt die Lineare Algebra verschiedene Verfahren bereit. Wir wollen hier auf eine Einführung in die Matrizeninvertierung per Hand verzichten, da in der Anwendung Matrizen standardmäßig numerisch invertiert werden. Die numerische Matrixinversion ist dann auch ein großes Feld der Forschung zur Numerischen Mathematik, die eine Vielzahl von Algorithmen zu diesem Zweck bereitstellt. In R werden Matrizen per default mit der Funktion solve(), in Anlehnung an das Lösen linearer Gleichungssysteme, invertiert. Für das obige Beispiel einer invertierbaren Matrix ergibt sich dabei folgender R Code.
[,1] [,2]
[1,] 0.8 -0.2
[2,] -0.6 0.4 [,1] [,2]
[1,] 1 0
[2,] 0 1 [,1] [,2]
[1,] 1 -5.551115e-17
[2,] 0 1.000000e+00Nicht-invertierbare Matrizen sind dabei natürlich auch numerisch nicht-invertierbar, wie folgende Fehlermeldung in R bezüglich obigen Beispiels einer nicht-invertierbaren Matrix demonstriert.
9.5 Determinanten
Die Determinante ist eine vielseitig einsetzbare Maßzahl einer quadratischen Matrix. Für das Verständnis der Eigenanalyse und der Matrixzerlegung ist der Begriff der Determinante im Kontext des charakteristischen Polynoms grundlegend.
Allgemein ist eine Determinante eine nichtlineare Abbildung der Form \[\begin{equation} \lvert \cdot \rvert: \mathbb{R}^{n \times n} \to \mathbb{R}, A \mapsto \lvert A \rvert, \end{equation}\] das heißt, eine Determinante ordnet einer quadratischen Matrix \(A\) die reelle Zahl \(\lvert A \rvert\) zu. Die Zahl \(\lvert A \rvert\) wird dabei rekursiv anhand folgender Definition bestimmt.
Definition 9.9 (Determinante) Für \(A = (a_{ij})_{1 \le i,j \le n} \in \mathbb{R}^{n \times n}\) mit \(n>1\) sei \(A_{ij} \in \mathbb{R}^{n-1 \times n-1}\) die Matrix, die aus \(A\) durch Entfernen der \(i\)ten Zeile und der \(j\)ten Spalte entsteht. Dann heißt die Zahl \[\begin{align} \lvert A \rvert & := a_{11} \quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad \mbox{ für } n = 1\\ \lvert A \rvert & := \sum_{j = 1}^n a_{1j}(-1)^{1+j} \det\left(A_{1j}\right) \mbox{ für } n > 1 \end{align}\] die Determinante von \(A\).
Die Definition führt die Bestimmung der Determinante einer quadratischen Matrix also sukzessive durch Streichen von Zeilen und Spalten auf die Determinante einer \(1 \times 1\) Matrix zurück, die durch ihr einziges Element gegeben ist. Für \[\begin{equation} A := \begin{pmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \\ \end{pmatrix} \in \mathbb{R}^{3 \times 3} \end{equation}\] ergeben sich dabei zum Beispiel folgende Matrizen der Form \(A_{ij} \in \mathbb{R}^{3-1 \times 3-1}\): \[\begin{equation} A_{11} = \begin{pmatrix} 5 & 6 \\ 8 & 9 \\ \end{pmatrix}, A_{12} = \begin{pmatrix} 4 & 6 \\ 7 & 9 \\ \end{pmatrix}, A_{21} = \begin{pmatrix} 2 & 3 \\ 8 & 9 \\ \end{pmatrix}, A_{22} = \begin{pmatrix} 1 & 3 \\ 7 & 9 \\ \end{pmatrix}. \end{equation}\]
Für die Berechnung der Determinanten von zwei- und dreidimensionalen quadratischen Matrizen gibt es direkte, nicht-rekursive Rechenregeln, die in folgendem Theorem festgehalten sind.
Theorem 9.8 (Determinanten von zwei- und dreidimensionalen Matrizen) \(\quad\)
Es sei \(A = (a_{ij})_{1 \le i,j \le 2} \in \mathbb{R}^{2 \times 2}\). Dann gilt \[\begin{equation} \lvert A \rvert = a_{11}a_{22} - a_{12}a_{21}. \end{equation}\] Es sei \(A = (a_{ij})_{1 \le i,j \le 3} \in \mathbb{R}^{3 \times 3}\). Dann gilt \[\begin{equation} \lvert A \rvert= a_{11}a_{22}a_{33} + a_{12}a_{23}a_{31} + a_{13}a_{21}a_{32} - a_{12}a_{21}a_{33} - a_{11}a_{23}a_{32} - a_{13}a_{22}a_{31}. \end{equation}\]
Beweis. Für \(A \in \mathbb{R}^{2 \times 2}\) gilt nach Definition \[\begin{align} \begin{split} \lvert A \rvert & = \sum_{j = 1}^n a_{1j}(-1)^{1+j} |A_{1j}| \\ & = a_{11}(-1)^{1 + 1}|A_{11}| + a_{12}(-1)^{1 + 2}|A_{12}| \\ & = a_{11}|(a_{22})| - a_{12}|(a_{21})| \\ & = a_{11}a_{22} - a_{12}a_{21}. \\ \end{split} \end{align}\] Für \(A \in \mathbb{R}^{3 \times 3}\) gilt nach Definition und mit der Formel für Determinanten von \(2 \times 2\) Matrizen \[\begin{align} \begin{split} \lvert A \rvert & = \sum_{j = 1}^n a_{1j}(-1)^{1+j} |A_{1j}| \\ & = a_{11}(-1)^{1+1} |A_{11}| + a_{12}(-1)^{1+2} |A_{12}| + a_{13}(-1)^{1+3}|A_{13}| \\ & = a_{11}|A_{11}| - a_{12}|A_{12}| + a_{13}|A_{13}| \\ & = a_{11}\left\vert\begin{pmatrix} a_{22} & a_{23} \\ a_{32} & a_{33}\end{pmatrix}\right\vert - a_{12}\left\vert\begin{pmatrix} a_{21} & a_{23} \\ a_{31} & a_{33}\end{pmatrix}\right\vert + a_{13}\left\vert\begin{pmatrix} a_{21} & a_{22} \\ a_{31} & a_{32}\end{pmatrix}\right\vert \\ & = a_{11}(a_{22}a_{33} - a_{23}a_{32}) - a_{12}(a_{21}a_{33} - a_{23}a_{31}) + a_{13}(a_{21}a_{32} - a_{22}a_{31}) \\ & = a_{11}a_{22}a_{33} - a_{11}a_{23}a_{32} - a_{12}a_{21}a_{33} + a_{12}a_{23}a_{31} + a_{13}a_{21}a_{32} - a_{13}a_{22}a_{31} \\ & = a_{11}a_{22}a_{33} + a_{12}a_{23}a_{31} + a_{13}a_{21}a_{32} - a_{12}a_{21}a_{33} - a_{11}a_{23}a_{32} - a_{13}a_{22}a_{31}. \end{split} \end{align}\]
Für die Bestimmung der Determinanten von \(2 \times 2\) und \(3 \times 3\) Matrizen gilt somit die sogenannte Sarrusche Merkregel: \[\begin{equation*} \mbox{``Summe der Produkte auf den Diagonalen minus Summe der Produkte auf den Gegendiagonalen.''} \end{equation*}\] Dabei bezieht sich die Merkregel bei \(3 \times 3\) Matrizen auf das Schema \[\begin{equation} \begin{pmatrix} a_{11} & a_{12} & a_{13} & \vert & a_{11} & a_{12} \\ a_{21} & a_{22} & a_{23} & \vert & a_{21} & a_{22} \\ a_{31} & a_{32} & a_{33} & \vert & a_{31} & a_{32} \end{pmatrix}. \end{equation}\]
Beispiele für Determinanten von \(2 \times 2\) und \(3 \times 3\) Matrizen
Es seien \[\begin{equation} A := \begin{pmatrix} 2 & 1 \\ 3 & 4 \end{pmatrix}, B := \begin{pmatrix} 1 & 0 \\ 0 & 0 \end{pmatrix} \mbox{ und } C := \begin{pmatrix} 2 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 3 \end{pmatrix} \end{equation}\] Dann ergeben sich \[\begin{equation} \lvert A \rvert = 2 \cdot 4 - 1 \cdot 3 = 8 - 3 = 5 \end{equation}\] und \[\begin{equation} \lvert B \rvert = 1 \cdot 0 - 0 \cdot 0 = 0 - 0 = 0 \end{equation}\] und \[\begin{equation} \lvert C \rvert = 2 \cdot 1 \cdot 3 + 0 \cdot 0 \cdot 0 + 0 \cdot 0 \cdot 0 - 0 \cdot 0 \cdot 3 - 0 \cdot 0 \cdot 0 - 0 \cdot 1 \cdot 0 = 2 \cdot 1 \cdot 3 = 6. \end{equation}\]
In R rechnet man dies mithilfe der det() Funktion wie folgt nach.
[1] 5[1] 0[1] 6Für Determinanten bestehen zahlreiche Rechenregeln im Zusammenspiel mit Matrixmultiplikation und Matrixinversion. Ohne Beweis stellen wir diese in folgendem Theorem zusammen.
Theorem 9.9 (Rechenregeln für Determinanten) \(\quad\)
(Determinantenmultiplikationssatz). Für \(A,B \in \mathbb{R}^{n \times n}\) gilt \[\begin{equation} |AB| = \lvert A \rvert\lvert B \rvert. \end{equation}\] (Transposition). Für \(A \in \mathbb{R}^{n \times n}\) gilt \[\begin{equation} \lvert A \rvert = \left\vert A^T \right\vert. \end{equation}\] (Inversion). Für eine invertierbare Matrix \(A \in \mathbb{R}^{n \times n}\) gilt \[\begin{equation} \left\vert A^{-1}\right\vert = \frac{1}{\lvert A \rvert}. \end{equation}\] (Dreiecksmatrizen). Für Matrizen \(A = (a_{ij})_{1 \le i,j\le n} \in \mathbb{R}^{n \times n}\) mit \(a_{ij} = 0\) für \(i > j\) oder \(a_{ij} = 0\) für \(j > i\) gilt \[\begin{equation} \lvert A \rvert = \prod_{i=1}^n a_{ii}. \end{equation}\]
Folgendes sehr tiefgehendes Theorem, welches wir nicht vollständig beweisen wollen, gibt eine Möglichkeit an, anhand der Determinante einer quadratischen Matrix zu bestimmen, ob sie invertierbar ist.
Theorem 9.10 \(A \in \mathbb{R}^{n \times n}\) ist dann und nur dann invertierbar, wenn gilt, dass \(\lvert A \rvert \neq 0\). Es gilt also \[\begin{equation} A \mbox{ ist invertierbar} \Leftrightarrow \lvert A \rvert \neq 0 \mbox{ und } A \mbox{ ist nicht invertierbar} \Leftrightarrow \lvert A \rvert = 0. \end{equation}\]
Beweis. Wir deuten einen Beweis lediglich an und zeigen, dass aus der Invertierbarkeit von \(A\) folgt, dass \(\lvert A \rvert\) nicht gleich Null sein kann. Nehmen wir also an, dass \(A\) invertierbar ist. Dann gibt es eine Matrix \(B\) mit \(AB = I_n\) und mit dem Determinantenmultiplikationssatz folgt \[\begin{equation} \lvert AB \rvert = \lvert A \rvert\lvert B \rvert= |I_n| = 1. \end{equation}\] Also kann \(\lvert A \rvert = 0\) nicht gelten, denn sonst wäre \(0 = 1\).
Visuelle Intuition
Der abstrakte Begriff der Determinante einer quadratischen Matrix kann mithilfe des Vektorraumbegriffs etwas veranschaulicht werden. Dazu seien \(a_1,...,a_n \in \mathbb{R}^n\) die Spalten von \(A \in \mathbb{R}^{n \times n}\). Dann gilt (wie wir nicht beweisen wollen), dass \(\lvert A \rvert\) dem signierten Volumen des von \(a_1,...,a_n\in \mathbb{R}^n\) aufgespannten Parallelotops entspricht. Um dies visuell zu veranschaulichen betrachten wir die Matrizen \[\begin{equation} A_1 = \begin{pmatrix} 3 & 1 \\ 1 & 2 \end{pmatrix}, A_2 = \begin{pmatrix} 2 & 0 \\ 0 & 2 \end{pmatrix}, A_3 = \begin{pmatrix} 2 & 2 \\ 2 & 2 \end{pmatrix} \end{equation}\] mit den jeweiligen Determinanten \[\begin{equation} \lvert A_1 \rvert = 3\cdot 2 - 1 \cdot 1 = 5, \quad \lvert A_2 \rvert= 2\cdot 2 - 0 \cdot 0 = 4, \quad \lvert A_3 \rvert = 2\cdot 2 - 2 \cdot 2 = 0. \end{equation}\]
Abbildung 9.1 visualisiert die entsprechende Intuition.
9.6 Spezielle Matrizen
In dieser Sektion stellen wir einige häufig auftretende Typen von Matrizen und ihre Eigenschaften zusammen. Zum Beweis der allermeisten Eigenschaften verweisen wir dabei auf die weiterführende Literatur.
9.6.1 Einheitsmatrizen
Die Einheitsmatrix und die Einheitsvektoren haben wir bereits kennengelernt. Wir fassen sie hier noch einmal in einer gemeinsamen Definition zusammen.
Definition 9.10 (Einheitsmatrix und Einheitsvektoren) Wir bezeichnen die Einheitsmatrix mit \[\begin{equation} I_{n} := (i_{jk})_{1 \le j \le n, 1 \le k \le n} \in \mathbb{R}^{n \times n} \mbox{ mit } i_{jk} = 1 \mbox{ für } j = k \mbox{ und } i_{jk} = 0 \mbox{ für } j \neq k. \end{equation}\] Wir bezeichnen die Einheitsvektoren \(e_i, i = 1,...,n\) mit \[\begin{equation} e_{i} := (e_{{i}_j})_{1 \le j \le n} \in \mathbb{R}^{n} \mbox{ mit } e_{{i}_j} = 1 \mbox{ für } i = j \mbox{ und } e_{{i}_j} = 0 \mbox{ für } i \neq j. \end{equation}\]
Die Einheitsmatrix \(I_n\) besteht nur aus Nullen und Diagonalelementen gleich Eins, die Einheitsvektoren bestehen nur aus Nullen und einer Eins in der jeweils indizierten Komponente. Es gilt \[\begin{equation} I_n = \begin{pmatrix} e_1 & \cdots & e_n \end{pmatrix} \in \mathbb{R}^{n \times n} \end{equation}\] Für \(n = 3\) gilt also zum Beispiel \[\begin{equation} I_3 = \begin{pmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{pmatrix} \mbox{ und } e_1 = \begin{pmatrix} 1 \\ 0 \\ 0 \end{pmatrix}, e_2 = \begin{pmatrix} 0 \\ 1 \\ 0 \end{pmatrix}, e_3 = \begin{pmatrix} 0 \\ 0 \\ 1 \end{pmatrix}. \end{equation}\] Weiterhin gelten für die Einheitsvektoren bekanntlich für \(1 \le i,j \le n\) \[\begin{equation} e^T_ie_j = 0 \mbox{ für } i \neq j, e^T_ie_i = 1 \mbox{ und } e^T_iv = v^Te_i = v_i \mbox{ für } v \in \mathbb{R}^n. \end{equation}\]
9.6.2 Einsmatrizen und Nullmatrizen
Definition 9.11 (Nullmatrizen, Nullvektoren, Einsmatrizen, Einsvektoren) Wir bezeichnen Nullmatrizen und Nullvektoren mit \[\begin{equation} 0_{nm} := (0)_{1 \le i \le n, 1 \le j \le m} \in \mathbb{R}^{n \times m} \mbox{ und } 0_{n} := (0)_{1 \le i \le n} \in \mathbb{R}^{n}. \end{equation}\] Wir bezeichnen Einsmatrizen und Einsvektoren mit \[\begin{equation} 1_{nm} := (1)_{1 \le i \le n, 1 \le j \le m} \in \mathbb{R}^{n \times m} \mbox{ und } 1_n := (1)_{1 \le i \le n} \in \mathbb{R}^n. \end{equation}\]
\(0_{nm}\) und \(0_{n}\) bestehen also nur aus Nullen und \(1_{nm}\) und \(1_{n}\) bestehen nur aus Einsen. Es gilt also beispielsweise \[\begin{equation} 0_{32} = \begin{pmatrix} 0 & 0 \\ 0 & 0 \\ 0 & 0 \end{pmatrix}, 0_{3} = \begin{pmatrix} 0 \\ 0 \\ 0 \end{pmatrix}, 1_{32} = \begin{pmatrix} 1 & 1 \\ 1 & 1 \\ 1 & 1 \end{pmatrix} \mbox{ und } 1_{3} = \begin{pmatrix} 1 \\ 1 \\ 1 \end{pmatrix}. \end{equation}\] Weiterhin gelten zum Beispiel \[\begin{equation} 0_n0_n^T = 0_{nn} \mbox{ und } 1_n1_n^T = 1_{nn}, \end{equation}\] wovon man sich durch Nachrechnen überzeugt.
9.6.3 Diagonalmatrizen
Definition 9.12 (Diagonalmatrix) Eine Matrix \(D \in \mathbb{R}^{n \times m}\) heißt Diagonalmatrix, wenn \(d_{ij} = 0\) für \(1 \le i \le n, 1 \le j \le m\) mit \(i \neq j\).
Eine quadratische Diagonalmatrix \(D\in \mathbb{R}^{n \times n}\) mit den Diagonalelementen \(d_1,...,d_n \in \mathbb{R}\) schreibt man auch als \[\begin{equation} D = \mbox{diag}(d_1,...,d_n). \end{equation}\] Zum Beispiel gelten \[\begin{equation} D := \mbox{diag}(1,2,3) = \begin{pmatrix} 1 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 3 \end{pmatrix} \end{equation}\] und für \(\sigma^2 \in \mathbb{R}\) \[\begin{equation} \Sigma = \mbox{diag}(\sigma^2,\sigma^2,\sigma^2) = \begin{pmatrix} \sigma^2 & 0 & 0 \\ 0 & \sigma^2 & 0 \\ 0 & 0 & \sigma^2 \end{pmatrix} = \sigma^2I_3. \end{equation}\]
In folgendem Theorem stellen wir einige wichtige Eigenschaften von quadratischen Diagonalmatrizen zusammen.
Theorem 9.11 (Eigenschaften quadratischer Diagonalmatrizen) \(\quad\)
(Determinante.) \(D := \mbox{diag}(d_1,...,d_n) \in \mathbb{R}^{n \times n}\) sei eine quadratische Diagonalmatrix. Dann gilt \[\begin{equation} |D| = \prod_{i=1}^n d_i. \end{equation}\]
9.6.4 Symmetrische Matrizen
Symmetrische Matrizen sind quadratische Matrizen, die bei Transposition unverändert bleiben:
Definition 9.13 Eine Matrix \(S \in \mathbb{R}^{n \times n}\) heißt symmetrisch, wenn \(S^T = S\).
Ein Beispiel für eine symmetrische Matrix ist \[\begin{equation} S := \begin{pmatrix} 1 & 2 & 3 \\ 2 & 1 & 2 \\ 3 & 2 & 1 \end{pmatrix}. \end{equation}\]
In folgendem Theorem stellen wir einige wichtige Eigenschaften symmetrischer Matrizen zusammen.
Theorem 9.12 (Eigenschaften symmetrischer Matrizen) \(\quad\)
(Summation.) \(S_1 \in \mathbb{R}^{n \times n}\) und \(S_2 \in \mathbb{R}^{n \times n}\) seien symmetrische Matrizen. Dann gilt \[\begin{equation} S_1 + S_2 = (S_1 + S_2)^T. \end{equation}\] (Inverse.) \(S\) sei eine invertierbare symmetrische Matrix und \(S^{-1}\) ihre Inverse. Dann ist auch \(S^{-1}\) eine symmetrische Matrix, das heißt es gilt \[\begin{equation} \left(S^{-1}\right)^T = S^{-1}. \end{equation}\]
9.6.5 Orthogonale Matrizen
Definition 9.14 Eine Matrix \(Q \in \mathbb{R}^{n \times n}\) heißt orthogonal, wenn \(Q^TQ = I_n\).
Die Spalten einer orthogonalen Matrix sind also paarweise orthogonal, es gilt für \[\begin{equation} Q = \begin{pmatrix} q_1 & \cdots & q_n \end{pmatrix} \mbox{ mit } q_i \in \mathbb{R}^n \mbox{ für } 1 \le i \le n, \end{equation}\] dass \[\begin{equation} q_i^Tq_j = 0 \mbox{ für } i \neq j \mbox{ und } q_i^Tq_j = 1 \mbox{ für } i = j \mbox{ mit } 1 \le i,j \le n. \end{equation}\]
Theorem 9.13 (Eigenschaften orthogonaler Matrizen) \(Q \in \mathbb{R}^{n \times n}\) sei eine orthogonale Matrix. Dann gelten folgende Eigenschaften von \(Q\). \(\quad\)
(Inverse.) Die Inverse von \(Q\) ist \(Q^T\), es gilt \[\begin{equation} Q^{-1} = Q^T. \end{equation}\] (Transposition) Die Zeilen von \(Q\) sind orthonormal, es gilt \[\begin{equation} QQ^T = I_n \end{equation}\]
Beweis. (Inverse) Unter der Annahme, dass \(Q^{-1}\) existiert, gilt \[\begin{equation} Q^TQ = I_n \Leftrightarrow Q^TQQ^{-1} = I_nQ^{-1} \Leftrightarrow Q^{-1} = Q^T. \end{equation}\] (Transposition) Es gilt \[\begin{equation} Q^TQ = I_n \Leftrightarrow QQ^TQ = QI_n \Leftrightarrow QQ^TQQ^T = QQ^T \Leftrightarrow QQ^T = I_n. \end{equation}\]
9.6.6 Positiv-definite Matrizen
Positiv-definite Matrizen sind für die probabilistische Modellbildung unter Verwendung multivariater Normalverteilungen zentral.
Definition 9.15 Eine quadratische Matrix \(C \in \mathbb{R}^{n \times n}\) heißt positiv-definit (\(\mbox{p.d.}\)), wenn
- \(C\) eine symmetrische Matrix ist und
- für alle \(x \in \mathbb{R}^n, x \neq 0_n\) gilt, dass \(x^TCx > 0\) ist.
In folgendem Theorem stellen wir einige wichtige Eigenschaften positiv-definiter Matrizen zusammen.
Theorem 9.14 (Eigenschaften positiv-definiter Matrizen) \(\quad\)
(Inverse.) \(C \in \mathbb{R}^{n \times n}\) sei eine positiv-definite Matrix. Dann gilt, dass \(C^{-1}\) existiert und ebenfalls positiv-definit ist.
9.7 Eigenanalyse
Mit der Eigenanalyse einer quadratischen Matrix, der Orthonormalzerlegung einer symmetrischen Matrix und der Singulärwertzerlegung einer beliebigen Matrix behandeln wir in diesem Abschnitt drei eng zusammenhängende Konzepte der Matrixtheorie, die in vielen Gebieten der datenanalytischen Anwendung zentrale Rollen spielen. Allerdings erschließt sich die Bedeutung dieser Konzepte dann vor allem im jeweiligen Anwendungskontext, so dass dieser Abschnitt notwendigerweise etwas abstrakt anmuten mag.
Eigenvektoren und Eigenwerte
Unter der Eigenanalyse einer quadratischen Matrix versteht man das Bestimmen ihrer Eigenvektoren und Eigenwerte. Diese sind für eine quadratische Matrix wie folgt definiert.
Definition 9.16 (Eigenvektor und Eigenwert) \(A \in \mathbb{R}^{m \times m}\) sei eine quadratische Matrix. Dann heißt jeder vom Nullvektor \(0_m\) verschiedene Vektor \(v \in \mathbb{R}^m\), für den mit einem Skalar \(\lambda \in \mathbb{R}\) gilt, dass \[\begin{equation} Av = \lambda v \end{equation}\] ist, ein Eigenvektor von \(A\) und \(\lambda\) heißt dann ein Eigenwert von \(A\).
Nach Definition hat also jeder Eigenvektor einen zugehörigen Eigenwert, allerdings können die Eigenwerte verschiedener Eigenvektoren durchaus identisch sein. Intuitiv bedeutet die Definition von Eigenvektor und Eigenwert, dass ein Eigenvektor einer Matrix durch Multiplikation mit eben dieser Matrix in seiner Länge, nicht aber in seiner Richtung, verändert wird. Der zugehörige Eigenwert des Eigenvektors entspricht dem Faktor der Längenänderung. Allerdings ist die Zuordnung von Eigenvektoren und Eigenwerten nicht eindeutig, wie das folgende Theorem zeigt.
Theorem 9.15 (Multiplikativität von Eigenvektoren) \(A \in \mathbb{R}^{m \times m}\) sei eine quadratische Matrix. Wenn \(v \in \mathbb{R}^m\) Eigenvektor von \(A\) mit Eigenwert \(\lambda \in \mathbb{R}\) ist, dann ist für \(c \in \mathbb{R} \setminus \{0\}\) auch \(cv \in \mathbb{R}^m\) Eigenvektor von \(A\) und zwar wiederum mit Eigenwert \(\lambda \in \mathbb{R}\).
Beweis. Es gilt \[\begin{equation} Av = \lambda v \Leftrightarrow cAv = c\lambda v \Leftrightarrow A(cv) = \lambda(cv). \end{equation}\] Also ist \(cv\) ein Eigenvektor von \(A\) mit Eigenwert \(\lambda\).
Um nun die Uneindeutigkeit in der Definition des zu einem Eigenwert zugeordneten Eigenvektors aufzulösen, nutzen wir die Konvention, nur diejenigen Vektoren als Eigenvektoren zu einem Eigenwert \(\lambda\) zu betrachten, die die Länge 1 haben, für die also gilt, dass \[\begin{equation} \Vert v \Vert = 1. \end{equation}\] Sollten wir also einen Eigenvektor \(v\) zu einem Eigenwert \(\lambda\) einer Matrix \(A\) finden, der nicht von der Länge 1 ist, so können wir ihn immer mit \(\Vert v \Vert^{-1}\) multiplizieren. Der resultierende Vektor \(v' = v/\Vert v \Vert\) hat dann die Länge 1 und ist nach Theorem 9.15 ebenso ein Eigenvektor von \(A\) zum Eigenwert \(\lambda\). Bevor wir uns der Bestimmung von Eigenwerten und Eigenvektoren widmen, wollen wir die Konzepte von Eigenwert und Eigenvektor für den Fall einer \(2 \times 2\) Matrix an einem Beispiel veranschaulichen.
Beispiel
Es sei \[\begin{equation} A := \begin{pmatrix} 2 & 1 \\ 1 & 2 \end{pmatrix} \end{equation}\] Dann ist der Vektor der Länge 1 \[\begin{equation} v := \frac{1}{\sqrt{2}} \begin{pmatrix} 1 \\ 1 \end{pmatrix} \end{equation}\] ein Eigenvektor von \(A\) zum Eigenwert \(\lambda = 3\), da gilt, dass \[\begin{align} \begin{split} Av & = \begin{pmatrix} 2 & 1 \\ 1 & 2 \end{pmatrix} \left( \frac{1}{\sqrt{2}} \begin{pmatrix} 1 \\ 1 \end{pmatrix} \right) \\ & = \frac{1}{\sqrt{2}} \begin{pmatrix} 2 & 1 \\ 1 & 2 \end{pmatrix} \begin{pmatrix} 1 \\ 1 \end{pmatrix} \\ & = \frac{1}{\sqrt{2}} \begin{pmatrix} 3 \\ 3 \end{pmatrix} \\ & = \frac{1}{\sqrt{2}} 3 \begin{pmatrix} 1 \\ 1 \end{pmatrix} \\ & = 3 \left( \frac{1}{\sqrt{2}} \begin{pmatrix} 1 \\ 1 \end{pmatrix} \right) \\ & = \lambda v. \end{split} \end{align}\] Inspektion von Abbildung 9.2 zeigt dementsprechend, dass für die hier definierte Matrix \(A\) die Vektoren \(v\) und \(Av\) in die gleiche Richtung zeigen, dass aber \(Av\) um den Faktor \(\lambda\) länger ist als \(v\).
Der Vektor \[\begin{equation} w := \begin{pmatrix} 1 \\ 0 \end{pmatrix} \end{equation}\] dagegen hat zwar die Länge 1, ist aber im Gegensatz zu \(v\) kein Eigenvektor von \(A\), da es im Falle von \[\begin{equation} Aw = \begin{pmatrix} 2 & 1 \\ 1 & 2 \end{pmatrix} \begin{pmatrix} 1 \\ 0 \end{pmatrix} = \begin{pmatrix} 2 \\ 1 \end{pmatrix} \end{equation}\] keinen Skalar \(\lambda\) geben kann, der mit Null, dem zweiten Eintrag von \(w\), multipliziert einen Wert ungleich Null ergeben kann. Inspektion von Abbildung 9.2 zeigt dementsprechend, dass der aus der Multiplikation von \(w\) mit \(A\) resultierende Vektor in eine andere Richtung zeigt als \(w\).
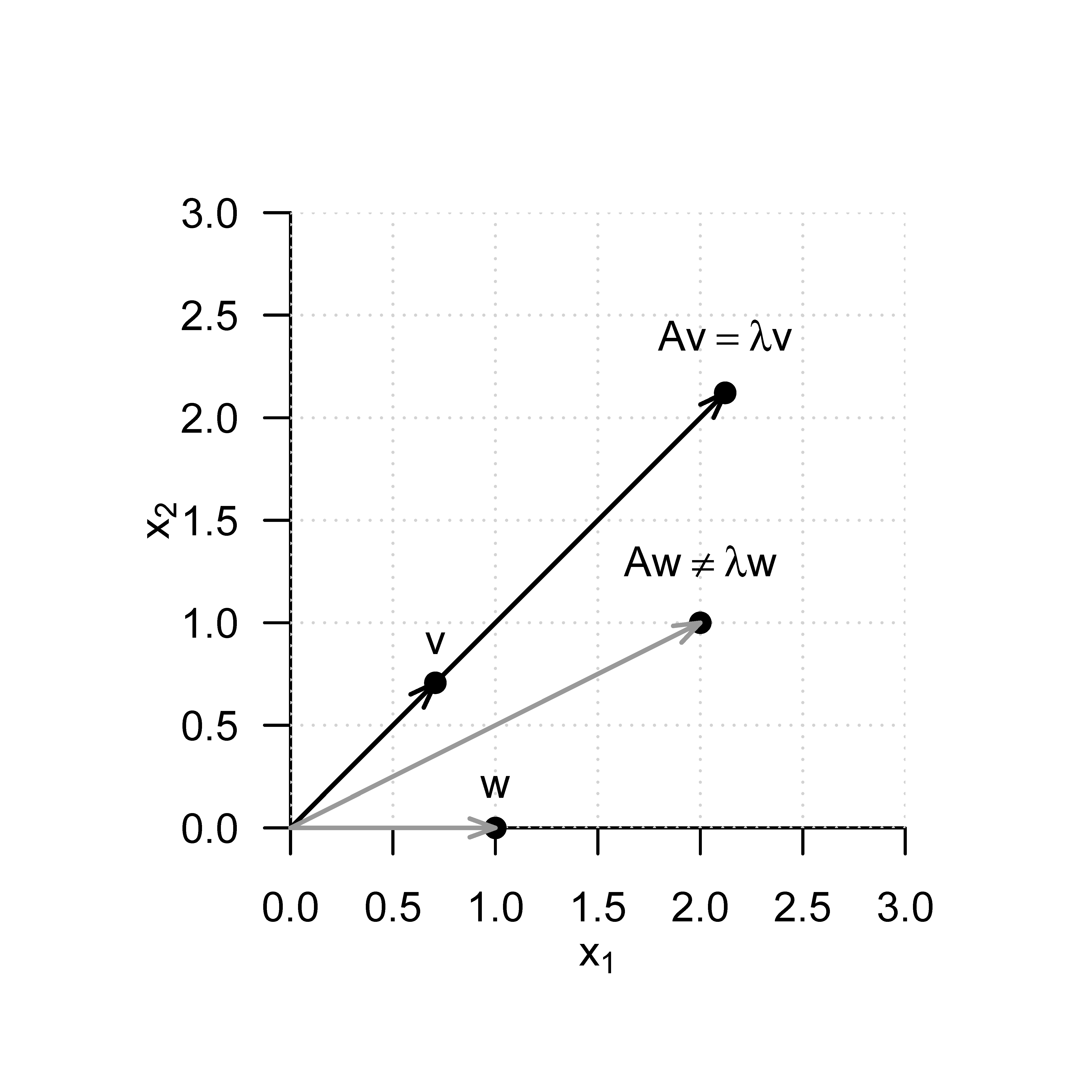
Bestimmung von Eigenwerten und Eigenvektoren
Folgendes Theorem besagt, wie die Eigenwerte und Eigenvektoren einer quadratischen Matrix berechnet werden können.
Theorem 9.16 (Bestimmung von Eigenwerten und Eigenvektoren) \(A \in \mathbb{R}^{m \times m}\) sei eine quadratische Matrix. Dann ergeben sich die Eigenwerte von \(A\) als die Nullstellen des \[\begin{equation} \chi_A(\lambda) := |A - \lambda I_m| \end{equation}\] von \(A\). Weiterhin seien \(\lambda_i^*, i = 1,2,...\) die auf diese Weise bestimmten Eigenwerte von \(A\). Die entsprechenden Eigenvektoren \(v_i, i = 1,2,...\) von \(A\) können dann durch Lösen der linearen Gleichungssysteme \[\begin{equation} (A - \lambda_i^* I_m)v_i = 0_m \mbox{ für } i = 1,2,... \end{equation}\] bestimmt werden.
Beweis. (1) Bestimmen von Eigenwerten
Wir halten zunächst fest, dass mit der Definition von Eigenvektoren und Eigenwerten gilt, dass \[\begin{equation} Av = \lambda v \Leftrightarrow Av - \lambda v = 0_m \Leftrightarrow (A - \lambda I_m)v = 0_m. \end{equation}\] Für den Eigenwert \(\lambda\) wird der Eigenvektor \(v\) also durch Multiplikation mit \((A - \lambda I_m)\) auf den Nullvektor \(0_m\) abgebildet. Weil aber per Definition \(v \neq 0_m\) gilt, ist die Matrix \((A - \lambda I_m)\) somit nicht invertierbar: sowohl der Nullvektor als auch \(v\) werden durch \((A - \lambda I_m)\) auf \(0_m\) abgebildet, die Abbildung \[\begin{equation} f : \mathbb{R}^m \to \mathbb{R}^m, x \mapsto (A - \lambda I_m)x \end{equation}\] ist also nicht bijektiv, und \((A - \lambda I_m)^{-1}\) kann nicht existieren. Die Tatsache, dass \((A - \lambda I_m)\) nicht invertierbar ist, ist aber äquivalent dazu, dass die Determinante von \((A -\lambda I_m)\) gleich Null ist. Also ist \[\begin{equation} \chi_A(\lambda) = |A - \lambda I_m| = 0 \end{equation}\] eine notwendige und hinreichende Bedingung dafür, dass \(\lambda\) ein Eigenwert von \(A\) ist.
(2) Bestimmen von Eigenvektoren
Es sei \(\lambda_i^*\) ein Eigenwert von \(A\). Dann gilt mit den obigen Überlegungen, dass Auflösen von \[\begin{equation} (A - \lambda_i^* I_m)v_i^* = 0_m \end{equation}\] nach \(v_i^*\) einen Eigenvektor zum Eigenwert \(\lambda_i^*\) ergibt.
Allgemein müssen zur Bestimmung von Eigenwerten und Eigenvektoren also Polynomnullstellen bestimmt und lineare Gleichungssysteme gelöst werden. Dies kann für kleine Matrizen mit \(m \le 4\) durchaus manuell geschehen. Die in der Anwendung auftretenden Matrizen sind jedoch meist weitaus größer, so dass zur Eigenanalyse numerische Verfahren der Nullstellenbestimmung und des Lösens linearer Gleichungssysteme eingesetzt werden, die zum Beispiel in Funktionen wie R’s eigen(), SciPy’s linalg.eig() oder Julia’s eigvals() und eigvecs() genutzt werden. Für Details zu diesen Verfahren verweisen wir auf die weiterführende Literatur, zum Beispiel Burden et al. (2016) und Richter & Wick (2017). Wir wollen Theorem 9.16 hier lediglich anhand eines Beispiels illustrieren.
Beispiel
Dazu sei wiederum \[\begin{equation} A := \begin{pmatrix} 2 & 1 \\ 1 & 2\end{pmatrix} \end{equation}\] Wir wollen zunächst die Eigenwerte von \(A\) berechnen. Nach Theorem 9.16 sind dies die Nullstellen des charakteristischen Polynoms von \(A\). Wir berechnen also zunächst das charakteristische Polynom von \(A\) durch \[\begin{equation} \chi_A(\lambda) = \left\vert \begin{pmatrix} 2 & 1 \\ 1 & 2\end{pmatrix} - \begin{pmatrix} \lambda & 0 \\ 0 & \lambda \end{pmatrix} \right\vert = \left\vert \begin{pmatrix} 2 - \lambda & 1 \\ 1 & 2 - \lambda \end{pmatrix} \right\vert = (2 - \lambda)^2 - 1. \end{equation}\] Mithilfe der pq-Formel zur Lösung quadratischer Gleichungen findet man dann \[\begin{equation} (2 - \lambda^*_{1/2})^2 - 1 = 0 \Leftrightarrow \lambda_1^* = 3 \mbox{ oder } \lambda_2^* = 1. \end{equation}\] Die Eigenwerte von \(A\) sind also \(\lambda_1 = 3\) und \(\lambda_2 = 1\). Die zugehörigen Eigenvektoren ergeben sich dann für \(i = 1,2\) durch Lösen des linearen Gleichungssystems \[\begin{equation} (A - \lambda_i I_2)v_i = 0_2. \end{equation}\] Speziell ergibt sich hier, dass für \(\lambda_1 = 3\) aus \[\begin{equation} (A - 3I_2)v_1 = 0_2 \Leftrightarrow \begin{pmatrix} -1 & 1 \\ 1 & -1 \end{pmatrix} \begin{pmatrix} v_{1_1} \\ v_{1_2} \end{pmatrix} = \begin{pmatrix} 0 \\ 0 \end{pmatrix} \end{equation}\] folgt, dass \[\begin{equation} v_1 = \frac{1}{\sqrt{2}} \begin{pmatrix} 1 \\ 1 \end{pmatrix} \end{equation}\] ein Eigenvektor zum Eigenwert \(\lambda_1\) ist und dass für \(\lambda_2 = 1\) aus \[\begin{equation} (A - I_2)v_2 = 0_2 \Leftrightarrow \begin{pmatrix} 1 & 1 \\ 1 & 1 \end{pmatrix} \begin{pmatrix} v_{2_1} \\ v_{2_2} \end{pmatrix} = \begin{pmatrix} 0 \\ 0 \end{pmatrix} \end{equation}\] folgt, dass \[\begin{equation} v_2 = \frac{1}{\sqrt{2}} \begin{pmatrix} -1 \\ 1 \end{pmatrix} \end{equation}\] ein Eigenvektor zum Eigenwert \(\lambda_2 = 1\) ist. Weiterhin gelten hier offenbar \[\begin{equation} v_1^Tv_2 = 0 \mbox{ und } \Vert v_1 \Vert = \Vert v_2 \Vert = 1. \end{equation}\]
Folgender R Code demonstriert die Bestimmung der Eigenwerte und Eigenvektoren der hier betrachteten Matrix mithilfe der eigen() Funktion.
eigen() decomposition
$values
[1] 3 1
$vectors
[,1] [,2]
[1,] 0.7071068 -0.7071068
[2,] 0.7071068 0.7071068Zum Abschluss dieses Abschnittes betrachten wir zwei technische Theoreme, die Aussagen zum Zusammenhang spezieller Matrixprodukte und ihrer Eigenwerte und Eigenvektoren machen. Wir benötigen diese Theoreme im Kontext der Kanonischen Korrelationsanalyse (Kapitel 48).
Theorem 9.17 (Eigenwerte und Eigenvektoren von Matrixprodukten) Für \(A \in \mathbb{R}^{n \times m}\) und \(B \in \mathbb{R}^{m \times n}\) sind die Eigenwerte von \(AB \in \mathbb{R}^{n \times n}\) und \(BA \in \mathbb{R}^{m \times m}\) gleich. Weiterhin gilt, dass für einen Eigenvektor \(v\) zu einem von Null verschiedenen Eigenwert \(\lambda\) von \(AB\) \(w := Bv\) ein Eigenvektor von \(BA\) zum Eigenwert \(\lambda\) ist.
Für einen Beweis verweisen wir auf Mardia et al. (1979), S. 468. Wir demonstrieren die Aussage dieses Theorems anhand untenstehenden R Codes.
A = matrix(1:6, nrow = 2, byrow = T) # Matrix A \in \mathbb{R}^{2 x 3}
B = matrix(1:6, ncol = 2, byrow = T) # Matrix B \in \mathbb{R}^{3 x 2}
EAB = eigen(A %*% B) # Eigenanalyse von AB \in \mathbb{R}^{2 \times 2}
EBA = eigen(B %*% A) # Eigenanalyse von BA \in \mathbb{R}^{3 \times 3}
w = B %*% EAB$vectors[,1] # Eigenvektor von BA
cat("Eigenwerte von AB :" , EAB$values[1:2],
"\nEigenwerte von BA :", EBA$values[1:2],
"\nBAw mit w = Bv :", B %*% A %*% w,
"\nlw mit w = Bv :", EBA$values[1] * w)Eigenwerte von AB : 85.57934 0.4206623
Eigenwerte von BA : 85.57934 0.4206623
BAw mit w = Bv : -191.1333 -416.7586 -642.3839
lw mit w = Bv : -191.1333 -416.7586 -642.3839Theorem 9.18 Für \(A \in \mathbb{R}^{n \times m}, B \in \mathbb{R}^{p \times n}, a \in \mathbb{R}^m\) und \(b \in \mathbb{R}^p\) gilt, dass der einzige von Null verschiedene Eigenwert von \(Aab^TB \in \mathbb{R}^{n \times n}\) gleich \(b^T BAa\) mit zugehörigem Eigenvektor \(Aa\) ist.
Für einen Beweis verweisen wir auf Mardia et al. (1979), S. 468. Wir demonstrieren die Aussage dieses Theorems anhand untenstehenden R Codes.
A = matrix(1:6, nrow = 2, byrow = T) # Matrix A \in \mathbb{R}^{2 x 3}
B = matrix(1:8, ncol = 2, byrow = T) # Matrix B \in \mathbb{R}^{4 x 2}
a = matrix(1:3, nrow = 3, byrow = T) # Vektor a \in \mathbb{R}^{3 x 1}
b = matrix(1:4, nrow = 4, byrow = T) # Vektor b \in \mathbb{R}^{4 x 1}
EAabTB = eigen(A %*% a %*% t(b) %*% B) # Eigenanalyse von Aab^TB \in \mathbb{R}^{2 x 2}
cat("Eigenwerte von AabTB :", EAabTB$values,
"\nbTBAa :", t(b) %*% B %*% A %*% a,
"\nAa :", A %*% a,
"\n(AabTB)Aa :",(A %*% a %*% t(b) %*% B) %*% A %*% a, # Mv
"\n(bTBAa)Aa :",as.vector((t(b) %*% B %*% A %*% a)) * (A %*% a)) # = \lambda vEigenwerte von AabTB : 2620 0
bTBAa : 2620
Aa : 14 32
(AabTB)Aa : 36680 83840
(bTBAa)Aa : 36680 838409.8 Orthonormalzerlegung
Mit dem Begriff der Zerlegung einer Matrix wird das Aufspalten einer gegebenen Matrix in das Matrixprodukt mehrerer Matrizen bezeichnet. Verschiedenste Matrixzerlegungen spielen in vielen mathematischen Anwendungen eine wichtige Rolle, für einen Überblick siehe beispielsweise Golub & Van Loan (2013). In diesem Abschnitt führen wir mit der Orthonormalzerlegung einer symmetrischen Matrix eine spezielle Matrixzerlegung ein, die direkt auf der Eigenanalyse aufbaut. Wir halten zunächst folgendes grundlegendes Theorem zu den Eigenwerten und Eigenvektoren symmetrischer Matrizen fest.
Theorem 9.19 (Eigenwerte und Eigenvektoren symmetrischer Matrizen)
\(S \in \mathbb{R}^{m \times m}\) sei eine symmetrische Matrix. Dann geltenBeweis. Wir setzen die Tatsache, dass eine symmetrische Matrix \(m\) reelle Eigenwerte hat, als gegeben voraus und zeigen lediglich, dass die Eigenvektoren zu je zwei verschiedenen Eigenwerten einer symmetrischen Matrix orthogonal sind. Ohne Beschränkung der Allgemeinheit seien also \(\lambda_i, \lambda_j \in \mathbb{R}\) mit \(1 \le i,j \le m\) und \(\lambda_i \neq \lambda_j\) zwei verschiedene Eigenwerte von \(S\) mit zugehörigen Eigenvektoren \(q_i\) und \(q_j\), respektive. Dann ergibt sich wie unten gezeigt, dass \[\begin{equation} \lambda_i q_i^Tq_j = \lambda_j q_i^Tq_j. \end{equation}\] Mit \(q_i \neq 0_m, q_j \neq 0_m\) und \(\lambda_i \neq \lambda_j\) folgt damit \(q_i^Tq_j = 0\), weil es keine andere Zahl \(c\) als die Null gibt, für die bei \(a,b\in \mathbb{R}\) und \(a \neq b\) gilt, dass \[\begin{equation} ac = bc. \end{equation}\] Um abschließend \[\begin{equation} \lambda_i q_i^Tq_j = \lambda_j q_i^Tq_j. \end{equation}\] zu zeigen, halten wir zunächst fest, dass \[\begin{equation} Sq_i = \lambda_i q_i \Leftrightarrow (Sq_i)^T = (\lambda_i q_i)^T \Leftrightarrow q_i^TS^T = \lambda_i q_i^T \Leftrightarrow q_i^T S = \lambda_i q_i^T \Leftrightarrow q_i^T Sq_j = \lambda_i q_i^Tq_j \end{equation}\] und \[\begin{equation} Sq_j = \lambda_j q_j \Leftrightarrow q_j^T S = \lambda_j q_j^T \Leftrightarrow q_j^T Sq_i = \lambda_j q_j^Tq_i \Leftrightarrow (q_j^T S q_i)^T = (\lambda_j q_j^Tq_i)^T \Leftrightarrow q_i^T S q_j = \lambda_j q_i^Tq_j \end{equation}\] gelten. Sowohl \(\lambda_i q_i^Tq_j\) als auch \(\lambda_j q_i^Tq_j\) sind also mit \(q_i^T Sq_j\) und damit auch miteinander identisch.
Offenbar haben wir nur Aussage (2) von Theorem 9.19 bewiesen. Ein vollständiger Beweis des Theorems findet sich zum Beispiel bei Strang (2009). Wir merken außerdem an, dass, weil wir nach Konvention Eigenvektoren der Länge 1 betrachten, die in Theorem 9.19 angesprochenen orthogonalen Eigenvektoren insbesondere auch orthonormal sind. Mithilfe von Theorem 9.19 können wir nun die Orthonormalzerlegung einer symmetrischen Matrix formulieren und ihre Existenz beweisen.
Theorem 9.20 (Orthonormalzerlegung einer symmetrischen Matrix) \(S \in \mathbb{R}^{m \times m}\) sei eine symmetrische Matrix mit \(m\) verschiedenen Eigenwerten. Dann kann \(S\) geschrieben werden als \[\begin{equation} S = Q \Lambda Q^T, \end{equation}\] wobei \(Q \in \mathbb{R}^{m \times m}\) eine orthogonale Matrix ist und \(\Lambda \in \mathbb{R}^{m\times m}\) eine Diagonalmatrix ist.
Beweis. Es seien \(\lambda_1 > \lambda_2 > ... > \lambda_m\) die der Größe nach geordneten Eigenwerte von \(S\) und \(q_1,...,q_m\) die zugehörigen orthonormalen Eigenvektoren. Mit \[\begin{equation} Q := \begin{pmatrix} q_1 & q_2 & \cdots & q_m \end{pmatrix} \in \mathbb{R}^{m \times m} \mbox{ und } \Lambda := \mbox{diag}\begin{pmatrix} \lambda_1,\lambda_2,...,\lambda_m \end{pmatrix} \in \mathbb{R}^{m \times m}, \end{equation}\] folgt dann mit den Definitionen von Eigenwerten und Eigenvektoren zunächst, dass \[\begin{equation} Sq_i = \lambda_i q_i \mbox{ für } i = 1,...,m \Leftrightarrow SQ = Q\Lambda. \end{equation}\] Rechtsseitige Multiplikation mit \(Q^T\) ergibt dann mit \(QQ^T = I_m\), dass \[\begin{equation} SQQ^T = Q \Lambda Q^T \Leftrightarrow SI_m = Q \Lambda Q^T \Leftrightarrow S = Q \Lambda Q^T. \end{equation}\]
Man nennt das Aufspalten von \(S\) in das Matrixprodukt \(Q\Lambda Q^T\) aufgrund der Diagonalität von \(\Lambda\) auch eine Diagonalisierung von \(S\). Wie im Beweis gezeigt, wählt man zur Darstellung von \(S\) in Diagonaldarstellung für die Diagonalelemente von \(\Lambda\) die der Größe nach geordneten Eigenwerte von \(S\) und für die Spalten von \(Q\) die jeweils zugehörigen Eigenvektoren von \(S\). Wir verdeutlichen dies an einem Beispiel.
Beispiel
Für die symmetrische Matrix \[\begin{equation} A = \begin{pmatrix} 2 & 1 \\ 1 & 2 \end{pmatrix} \end{equation}\] mit den oben bestimmten Eigenwerten \(\lambda_1 = 3\) und \(\lambda_2 = 1\) sowie den zugehörigen orthonormalen Eigenvektoren \[\begin{equation} v_1 = \frac{1}{\sqrt{2}} \begin{pmatrix} 1 \\ 1 \end{pmatrix}, v_2 = \frac{1}{\sqrt{2}} \begin{pmatrix} -1 \\ 1 \end{pmatrix} \end{equation}\] seien \[\begin{equation} Q := \begin{pmatrix} v_1 & v_2 \end{pmatrix} \mbox{ und } \Lambda = \mbox{diag}(\lambda_1,\lambda_2). \end{equation}\] Dann ergibt sich offenbar \[\begin{align*} Q\Lambda Q^T & = \begin{pmatrix} v_1 & v_2 \end{pmatrix} \mbox{diag}(\lambda_1,\lambda_2) \begin{pmatrix} v_1 & v_2 \end{pmatrix}^T \\ & = \left( \frac{1}{\sqrt{2}} \begin{pmatrix} 1 & -1\\ 1 & 1 \end{pmatrix} \begin{pmatrix} 3 & 0 \\ 0 & 1 \end{pmatrix} \right) \left( \frac{1}{\sqrt{2}} \begin{pmatrix} 1 & 1 \\ -1 & 1 \end{pmatrix} \right) \\ & = \left( \frac{1}{\sqrt{2}} \begin{pmatrix} 3 & -1 \\ 3 & 1 \end{pmatrix} \right) \left( \frac{1}{\sqrt{2}} \begin{pmatrix} 1 & 1 \\ -1 & 1 \end{pmatrix} \right) \\ & = \frac{1}{2} \begin{pmatrix} 4 & 2 \\ 2 & 4 \end{pmatrix} \\ & = \begin{pmatrix} 2 & 1 \\ 1 & 2 \end{pmatrix} \\ & = A \end{align*}\] und wir haben Theorem 9.20 für dieses Beispiel verifiziert.
Symmetrische Quadratwurzel einer Matrix
Die Definition der Orthonormalzerlegung einer symmetrischen Matrix erlaubt es, den Begriff der symmetrischen Quadratwurzel einer Matrix einzuführen.
Definition 9.17 (Symmetrische Quadratwurzel einer Matrix) \(S \in \mathbb{R}^{m \times m}\) sei eine invertierbare symmetrische Matrix mit positiven Eigenwerten. Dann sind für \(r \in \mathbb{N}^0\) und \(s \in \mathbb{N}\) die rationalen Potenzen von \(S\) mit der orthonormalen Matrix \(Q \in \mathbb{R}^{m \times m}\) der Eigenvektoren von \(S\) und der Diagonalmatrix \(\Lambda = \mbox{diag}(\lambda_i) \in \mathbb{R}^{m \times m}\) der zugehörigen Eigenwerte \(\lambda_1,...,\lambda_m\) von \(S\) definiert als \[\begin{equation} S^{r/s} = Q \Lambda^{r/s} Q^T \mbox{ mit } \Lambda^{r/s} = \mbox{diag}\left(\lambda_i^{r/s}\right). \end{equation}\] Der Spezialfall \(r:= 1, s := 2\) wird als symmetrische Quadratwurzel von \(S\) bezeichnet und hat die Form \[\begin{equation} S^{1/2} = Q\Lambda^{1/2}Q^T \mbox{ mit } \Lambda^{1/2} = \mbox{diag}\left(\lambda_i^{1/2}\right). \end{equation}\]
Wir halten fest, dass mit Definition 9.17 offenbar gilt, dass \[\begin{equation} \left(S^{1/2} \right)^2 = Q\Lambda^{1/2}Q^TQ\Lambda^{1/2}Q^T = Q\Lambda^{1/2}\Lambda^{1/2}Q^T = Q\Lambda Q^T = S. \end{equation}\] Weiterhin gilt, dass \[\begin{equation} \left(S^{-1/2} \right)^2 = Q\Lambda^{-1/2}Q^TQ\Lambda^{-1/2}Q^T = Q\Lambda^{-1/2}\Lambda^{-1/2}Q^T = Q\Lambda^{-1}Q^T = S^{-1}. \end{equation}\] Schließlich gilt, dass \[\begin{align} \begin{split} S^{-1/2}SS^{-1/2} & = Q\Lambda^{-1/2}Q^T Q\Lambda Q^T Q\Lambda^{-1/2}Q^T \\ & = Q\Lambda^{-1/2}\Lambda \Lambda^{-1/2}Q^T \\ & = Q\Lambda \Lambda^{-1}Q^T \\ & = I_m \end{split} \end{align}\]
9.9 Singulärwertzerlegung
Eine vielseitig einsetzbare Matrixzerlegung einer beliebigen Matrix ist die Singulärwertzerlegung. Wir sind an dieser Stelle lediglich an dem Zusammenhang von Singulärwertzerlegung und Eigenanalyse interessiert und verweisen für eine ausführliche Diskussion der Singulärwertzerlegung auf die weiterführende Literatur, beispielsweise Strang (2009). Der Begriff der Singulärwertzerlegung ist wie folgt definiert.
Definition 9.18 (Singulärwertzerlegung) \(Y \in \mathbb{R}^{m \times n}\) sei eine Matrix. Dann heißt die Zerlegung \[\begin{equation} Y = USV^T, \end{equation}\] wobei \(U \in \mathbb{R}^{m \times m}\) eine orthogonale Matrix ist, \(S \in \mathbb{R}^{m \times n}\) eine Diagonalmatrix ist und \(V \in \mathbb{R}^{n \times n}\) eine orthogonale Matrix ist, Singulärwertzerlegung von \(Y\). Die Diagonalelemente von \(S\) heißen die Singulärwerte von \(Y\).
Singulärwertzerlegungen werden auf Englisch singular value decompositions genannt und entsprechend mit SVD abgekürzt. Wir verzichten auf eine Diskussion der Berechnung einer Singulärwertzerlegung und weisen lediglich daraufhin, dass Singulärwertzerlegungen zum Beispiel in R mit der Funktion svd(), in SciPy mit scipy.linalg.svd() und in Julia mit svd() berechnet werden können. Folgendes Theorem beschreibt den Zusammenhang zwischen Singulärwertzerlegung und Eigenanalyse und wird an vielen Stellen eingesetzt.
Theorem 9.21 (Singulärwertzerlegung und Eigenanalyse)
\(Y \in \mathbb{R}^{m \times n}\) sei eine Matrix und \[\begin{equation} Y = USV^T \end{equation}\] sei ihre Singulärwertzerlegung. Dann gilt:Beweis. Wir halten zunächst fest, dass mit \[\begin{equation} \left(YY^T\right)^T = YY^T \mbox{ und } \left(Y^TY\right)^T = Y^TY, \end{equation}\] \(YY^T\) und \(Y^TY\) symmetrische Matrizen sind und somit Orthonormalzerlegungen haben. Wir halten weiterhin fest, dass mit \(V^TV = I_n\) und \(U^TU = I_m\) gilt, dass \[\begin{equation} YY^T = USV^T \left(USV^T\right)^T = USV^TVS^TU^T = USS^TU^T =: U\Lambda_U U^T \end{equation}\] und \[\begin{equation} Y^TY = \left(USV^T\right)^T USV^T = VS^TU^T USV^T = VS^TSV^T =: V\Lambda_V V^T \end{equation}\] ist, wobei wir \(\Lambda_U := SS^T\) und \(\Lambda_V := S^TS\) definiert haben. Weil das Produkt von Diagonalmatrizen wieder eine Diagonalmatrix ist, sind \(\Lambda_U\) und \(\Lambda_V\) Diagonalmatrizen und per Definition sind \(U\) und \(V\) orthogonale Matrizen. Wir haben also \(YY^T\) und \(Y^TY\) in Form der Orthonormalzerlegungen \[\begin{equation} YY^T = U \Lambda_U U^T \mbox{ und } Y^TY = V \Lambda_V V^T \end{equation}\] geschrieben, wobei für die von null verschiedenen Diagonalelemente von \(\Lambda_U\) und \(\Lambda_V\) gilt, dass sie die quadrierten Singulärwerte, also die quadrierten Diagonalelemente von \(S\), sind.
Burden, R. L., Faires, J. D., & Burden, A. M. (2016). Numerical Analysis (Tenth edition). Cengage Learning.
Golub, G. H., & Van Loan, C. F. (2013). Matrix Computations (Fourth edition). The Johns Hopkins University Press.
Mardia, K. V., Kent, J. T., & Bibby, J. M. (1979). Multivariate Analysis. Academic Press.
Richter, T., & Wick, T. (2017). Einführung in die Numerische Mathematik: Begriffe, Konzepte und zahlreiche Anwendungsbeispiele. Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-662-54178-4
Strang, G. (2009). Introduction to Linear Algebra. Cambridge University Press.