# Modellparameter
n = 12 # Anzahl der Datenpunkte
mu = 0 # wahrer, aber unbekannter, Erwartungswertparameter
sigsqr = 2 # wahrer, aber unbekannter, Varianzparameter
# Testparameter
mu_0 = 0 # Nullhypothesenparameter, hier \mu = \mu_0
alpha_0 = 0.05 # Signifikanzlevel
k_alpha_0 = qt(1-alpha_0/2,n-1) # Kritischer Wert
# Simulation der Testumfangkontrolle
set.seed(1) # Random number generator seed
nsim = 1e6 # Anzahl Simulationen
phi = rep(NaN,nsim) # Testentscheidungsarray
for(j in 1:nsim){ # Simulationsiterationen
y = rnorm(n, mu, sqrt(sigsqr)) # y_i \sim N(\mu,\Sigma), i = 1,...,n
y_bar = mean(y) # Stichprobenmittel
s = sd(y) # Stichprobenstandardabweichung
Tee = sqrt(n)*((y_bar - mu_0)/s) # Einstichproben-T-Test-Statistik
if(abs(Tee) > k_alpha_0){ # Test 1_{\vert t \vert >= k_alpha_0}
phi[j] = 1 # Ablehnen der Nullhypothese
} else {
phi[j] = 0 # Nichtablehnen der Nullhypothese
}
}33 Hypothesentests
Die grundlegende Logik Frequentistischer Hypothesentests kann am Beispiel des Normalverteilungsmodells grob wie folgt umrissen werden. Man unterstellt, dass ein beobachteter Datensatz eine Realisierung einer Stichprobe \(y_1,...,y_n \sim N(\mu,\sigma^2)\) ist und berechnet basierend auf dem Datensatz eine Teststatistik, zum Beispiel das anhand der Stichprobenstandardabweichung und der Stichprobengröße normalisierte Stichprobenmittel \(\sqrt{n}\frac{\bar{y}}{s}\).
Man fragt sich dann, wie wahrscheinlich es wohl wäre, den beobachteten oder einen extremeren Wert der Teststatistik unter der Annahme eines Nullmodells zu observieren. Dabei versteht man unter einem Nullmodell intuitiv ein Wahrscheinlichkeitsverteilungsmodell bei dem kein “interessanter Effekt” vorliegt, also zum Beispiel im Sinne des Normalverteilungsmodells \(\mu = 0\) gilt. Dabei ist der Begriff der Wahrscheinlichkeit natürlich frequentistisch zu verstehen, also als idealisierte relative Häufigkeit, wenn man viele Stichprobenrealisationen des Nullmodells generieren würde. Je nach Beschaffenheit des zugrundeliegenden frequentistischen Inferenzmodells und der betrachteten Teststatistik kann es dabei durchaus möglich sein, diese Wahrscheinlichkeit exakt zu bestimmen.
Ist nun die betrachtete Wahrscheinlichkeit dafür, den beobachteten oder einen extremeren Wert der Teststatistik unter Annahme des Nullmodells zu observieren groß, so schließt man intuitiv, dass “es wohl ganz plausibel ist, dass das Nullmodell die Daten generiert hat”. Im Wissenschaftsjargon spricht man dann von einem “statistisch nicht-signifikanten Ergebnis”. Ist die betrachtete Wahrscheinlichkeit dafür, den beobachteten oder einen extremeren Wert der Teststatistik unter Annahme des Nullmodells zu observieren, dagegen klein, so schließt man intuitiv, dass “es wohl nicht so plausibel, dass das Nullmodell die Daten generiert hat”. Im Wissenschaftsjargon spricht man in diesem Fall von einem “statistisch signifikanten Ergebnis”.
Wie immer in der Frequentistischen Statistik weiß man nach Durchführung einer solchen Prozedur natürlich nicht, ob im vorliegenden Fall nun wirklich das Nullmodell oder ein anderes Modell die Daten generiert hat. Nan weiß nur, wie oft man bei dieser Prozedur im Mittel richtig oder falsch liegen würde, wenn alle Annahmen zuträfen und man diese Prozedur sehr oft wiederholen würde.
In den folgenden Abschnitten wollen wir diese intuitiven Gedanken formalisieren. Dabei ist es wichtig, immer zwischen Hypothesen im Sinne der Frequentistischen Inferenz und dem generellen Begriff der wissenschaftlichen Hypothese zu unterscheiden. Das Aufstellen einer wissenschaftlichen Hypothese impliziert keineswegs die Notwendigkeit eines frequentistischen Hypothesentests. Es bedeutet lediglich, dass bei quantitativer Arbeitsweise Unsicherheit anhand beobachteter, für die Hypothese relevanter Daten sinnvoll quantifiziert und kommuniziert werden sollte. Frequentistische Hypothesentests sind dabei nur eine, wenn auch sehr populäre, der vielen Möglichkeiten, dies zu tun. Es sei schon an dieser Stelle erwähnt, dass das “Nullhypothesen-Signifikanz-Testen”, wie wir es im Folgenden darlegen, wissenschaftliche umstritten ist (vgl. zum Beispiel Amrhein & Greenland (2018) und McShane et al. (2019)).
33.1 Testhypothesen und Tests
Im Kontext eines frequentistischen Hypothesentests wird der Begriff des frequentistischen Inferenzmodells (vgl. Definition 30.1) zunächst durch die sogenannten Testhypothesen zu einem Testszenario erweitert. Wir nutzen dazu folgende Definition.
Definition 33.1 (Testhypothesen und Testszenario) Gegeben sei ein Frequentistisches Inferenzmodell mit Stichprobe \(y\), Ergebnisraum \(\mathcal{Y}\) und Parameterraum \(\Theta\). Weiterhin sei \(\{\Theta_0,\Theta_1\}\) eine Partition des Parameterraums, so dass \[\begin{equation} \Theta = \Theta_0 \cup \Theta_1 \mbox{ und } \Theta_0 \cap \Theta_1 = \emptyset. \end{equation}\] Dann ist eine Testhypothese eine Aussage über den wahren, aber unbekannten, Parameter \(\theta\) in Hinblick auf die Untermengen \(\Theta_0\) und \(\Theta_1\) des Parameterraums. Speziell werden die Aussagen
- \(\theta \in \Theta_0\) als Nullhypothese und
- \(\theta \in \Theta_1\) als Alternativhypothese
bezeichnet. Der Einfachheit halber bezeichnet man auch \(\Theta_0\) und \(\Theta_1\) direkt als Nullhypothese bzw. Alternativhypothese. Die Einheit aus Frequentistischem Inferenzmodell und Testhypothesen wird als Testszenario bezeichnet.
Je nach Beschaffenheit von \(\Theta_0\) und \(\Theta_1\) unterscheidet man zunächst einfache und zusammengesetzte Testhypothesen.
Definition 33.2 (Einfache und zusammengesetzte Testhypothesen) Für die Testhypothesen \(\Theta_i\) mit \(i = 0,1\) gilt:
- Enthält \(\Theta_i\) nur ein einziges Element, so heißt \(\Theta_i\) einfach.
- Enthält \(\Theta_i\) mehr als ein Element, so heißt \(\Theta_i\) zusammengesetzt.
Man beachte, dass weil nach Annahme der wahre, aber unbekannte, Parameter \(\theta\) die Verteilung \(\mathbb{P}_\theta\) der Stichprobe festlegt, eine einfache Testhypothese der Festlegung der Stichprobenverteilung auf genau eine Verteilung entspricht. Eine zusammengesetzte Testhypothese entspricht dagegen einer Menge möglicher Verteilungen der Stichprobe. Ein Beispiel für eine einfache Testhypothese in einem Testszenario mit Parameterraum \(\Theta := \mathbb{R}\) ist \[\begin{equation} \Theta_0 := \{0\}. \end{equation}\] Die entsprechende zusammengesetzte Alternativhypothese ist dann gegeben durch \[\begin{equation} \Theta_1 = \mathbb{R} \setminus \{0\}. \end{equation}\] Die Nullhypothese, also die Aussage “\(\theta \in \Theta_0\)” entspricht dabei der Aussage “\(\theta = 0\)”, da \(\Theta_0\) nur das eine Element 0 enthält.
Ist der Parameterraum eines Testszenarios eindimensional, so unterscheidet man weiterhin einseitige und zweiseitige Testhypothesen.
Definition 33.3 (Einseitige und zweiseitige Testhypothesen) Gegeben sei ein Testszenario mit eindimensionalem Parameteraum \(\Theta := \mathbb{R}\) und es sei \(\theta_0 \in \Theta\). Dann werden zusammengesetzte Nullhypothesen der Form \(\Theta_0 := ]-\infty,\theta_0]\) oder \(\Theta_0 := [\theta_0,\infty[\) einseitige Nullhypothesen genannt und auch in der Form \(H_0:\theta \le \theta_0\) bzw. \(H_0 : \theta \ge \theta_0\) geschrieben. Die entsprechenden Alternativhypothesen haben dabei die Form \(\Theta_1 := ]\theta_0,\infty[\) bzw. \(\Theta_1:= ]-\infty, \theta_0[\), auch geschrieben als \(H_1:\theta>\theta_0\) bzw. \(H_1:\theta < \theta_0\). Bei einer einfachen Nullhypothese der Form \(\Theta_0 := \{\theta_0\}\), auch geschrieben als \(H_0:\theta = \theta_0\), wird die Alternativhypothese \(\Theta_1 := \Theta \setminus \{\theta_0\}\), auch geschrieben als \(H_1:\theta \neq \theta_0\), zweiseitige Alternativhypothese genannt.
Vor dem Hintergrund eines Testszenarios definieren wir nun den Begriff des Tests.
Definition 33.4 (Test) Gegeben sei ein Testszenario. Dann ist ein Test eine Abbildung \(\phi\) aus dem Ergebnisraum der Stichprobe \(\mathcal{Y}\) in die Menge \(\{0,1\}\), also \[\begin{equation} \phi: \mathcal{Y} \to \{0,1\}, y \mapsto \phi(y), \end{equation}\] wobei
- \(\phi(y) = 0\) das Nichtablehnen der Nullhypothese und
- \(\phi(y) = 1\) das Ablehnen der Nullhypothese
repräsentieren.
Der Testbegriff ist nicht trivial, da Tests wie Schätzer und Konfidenzintervalle, als Funktionen der Stichprobenvariablen selbst Zufallsvariablen sind. Eigentlich sind Tests damit auf Zufallsvektorräumen definiert. Der Einfachheit halber betrachten wir in Definition 33.4 eine konkrete Realisierung \(y \in \mathcal{Y}\) der Stichprobe \(y\), die durch \(\phi\) in die Menge \(\{0,1\}\) abgebildet wird. Der Funktionswert \(\phi(y)\) von \(\phi\) ist vor diesem Hintergrund also eine Realisierung der Zufallsvariable \(\phi(y)\).
In der Anwendung ist man oft an Tests interessiert, die eine bestimmte Struktur haben. Wir formalisieren diese Struktur unter dem Begriff der Standardtests.
Definition 33.5 (Standardtest) Gegeben sei ein Testszenario. Dann ist ein Standardtest \(\phi\) definiert als die Verkettung einer Teststatistik \[\begin{equation} \gamma : \mathcal{Y} \to \Gamma \end{equation}\] und einer Entscheidungsregel \[\begin{equation} \delta : \Gamma \to \{0,1\} \end{equation}\] kann also geschrieben werden als \[\begin{equation} \phi := \delta \circ \gamma : \mathcal{Y} \to \{0,1\}. \end{equation}\]
Wie oben ist auch bei Definition 33.5 zu beachten, dass die Teststatistik eine Funktion der Stichprobenvariablen, also von Zufallsvariablen ist, die wir hier als Funktion der Werte dieser Zufallsvariablen in \(\mathcal{Y}\) definiert haben. Ebenso ist zu beachten, dass die Entscheidungsregel eine Funktion der zufälligen Teststatistik ist, die wir hier gleichfalls als Funktion der Werte dieser Zufallsvariable mit Ergebnisraum \(\Gamma\) geschrieben haben. Teststatistik und Entscheidungsregel sind in einem Testszenario also Zufallsvariablen. Entsprechend ist, wenn \(y\) eine Realisierung der Stichprobe \(y\) ist, \(\gamma(y) \in \Gamma\) eine Realisierung von \(\gamma(y)\) und \((\delta \circ \gamma)(y)\) eine Realisierung von \((\delta \circ \gamma)(y)\).
Die verteilungstheoretischen Eigenschaften eines Tests ergeben sich aus den ihnen zugrundeliegenden verteilungstheoretischen Eigenschaften des entsprechenden Frequentistischen Inferenzmodells und damit natürlich insbesondere der Verteilung der Stichprobenvariablen. Eine wichtige Brücke zwischen diesen beiden Ebenen bilden die Begriffe des kritischen Bereichs und des Ablehnungsbereichs eines Tests.
Definition 33.6 (Kritischer Bereich eines Tests) Gegeben sei ein Testszenario und ein Test \(\phi\). Dann heißt \[\begin{equation} K := \{y \in \mathcal{Y} |\phi(y) = 1 \} \subset \mathcal{Y}, \end{equation}\] also die Untermenge des Ergebnisraums \(\mathcal{Y}\) der Stichprobe \(y\), für die der Test den Wert \(1\) annimmt, kritischer Bereich des Tests
Man beachte, dass vor dem Hintergrund von Definition 33.6 die zufälligen Ereignisse \(\{y\in K\}\) und \(\{\phi(y) = 1\}\), dass also die Stichprobe einen Wert im kritischen Bereichs des Tests annimmt bzw. dass der Test den Wert 1 annimmt, äquivalent sind und damit die gleiche Wahrscheinlichkeit haben. Fragt man also nach der Wahrscheinlichkeit, dass ein Test den Wert \(1\) annimmt, also die Nullhypothese abgelehnt wird, so entspricht diese Wahrscheinlichkeit genau der Wahrscheinlichkeit, dass die Stichprobe einen Wert im kritischen Bereichs des Tests annimmt. Da die Verteilung der Stichprobe aber als bekannt vorausgesetzt ist, kann die Wahrscheinlichkeit für das Ablehnen der Nullhypothese basierend auf ihr bestimmt werden. Hat man speziell einen Standardtest vorliegen, so überträgt sich das Gesagte unmittelbar auch auf die zwischen Stichprobe und Test geschaltete Teststatistik. Dies führt auf die folgende Definition.
Definition 33.7 (Ablehnungsbereich eines Standardtests) Gegeben sei ein Testszenario und ein Standardtest \(\phi\) mit Teststatistik \(\gamma\). Dann heißt \[\begin{equation} A := \{\gamma(y) \in \Gamma |\phi(y) = 1 \} \subset \Gamma, \end{equation}\] also die Untermenge des Ergebnisraums \(\Gamma\) der Teststatistik, für die der Test den Wert 1 annimmt, Ablehnungsbereich des Tests.
Wie zum Begriff des kritischen Bereichs angemerkt gilt auch hier, dass die Ereignisse \(\{\phi(y) = 1\}\) und \(\{\gamma(y) \in A\}\) äquivalent sind und damit die gleiche Wahrscheinlichkeit besitzen. Insgesamt gelten mit Definition 33.6 und Definition 33.7 für einen Standardtest also \[\begin{equation} \{y\in K\} \Leftrightarrow \{\gamma(y) \in A\} \Leftrightarrow \{\phi(y) = 1\} \end{equation}\] und \[\begin{equation} \mathbb{P}_{\theta}\left(\{y\in K\}\right) = \mathbb{P}_{\theta}\left(\{\gamma(y) \in A\}\right) = \mathbb{P}_{\theta}\left(\{\phi(y) = 1\}\right). \end{equation}\] Dabei soll das Subskript \(\theta\) andeuten, dass die entsprechenden Verteilungen durch den Parameter der Stichprobenverteilung festgelegt sind.
In der Anwendung basiert die in Definition 33.5 allgemein angebene Form der Entscheidungsregel eines Standardtest meist darauf, dass eine beobachtete Teststatistik mit Ergebnisraum \(\Gamma := \mathbb{R}\) einen bestimmten sogenannten kritischen Wert \(k\in \mathbb{R}\) überschreitet oder unterschreitet. Dies führt auf die Konzepte der einseitigen und zweiseitigen kritischen Wert-basierte Tests.
Definition 33.8 (Kritischer Wert-basierte Tests) Ein kritischer Wert-basierter Test ist ein Standardtest, bei dem die Entscheidungsregel \(\delta\) von einem kritischen Wert \(k\) der Teststatistik mit Ergebnisraum \(\mathbb{R}\) abhängt. Speziell ist
- ein einseitiger kritischer Wert-basierter Test von der Form \[\begin{equation} \phi : \mathcal{Y} \to \{0,1\}, y \mapsto \phi(y) := 1_{\{\gamma(y) \ge k\}} = \begin{cases} 1 & \gamma(y) \ge k \\ 0 & \gamma(y) < k \end{cases}, \end{equation}\]
- ein zweiseitiger kritischer Wert-basierter Test von der Form \[\begin{equation} \phi : \mathcal{Y} \to \{0,1\}, y \mapsto \phi(y) := 1_{\{|\gamma(y)| \ge k\}} = \begin{cases} 1 & |\gamma(y)| \ge k \\ 0 & |\gamma(y)| < k \end{cases}. \end{equation}\]
Mit der Definition kritischer Wert-basierter Tests ist die praktische Durchführung eines Hypothesentests nun vorgezeichnet. Wie immer in der Frequentistischen Inferenz legt man vorliegenden Daten zunächst ein Frequentistisches Inferenzmodell zugrunde, nimmt also an, dass die vorliegenden Daten eine Realisierung einer Stichprobe sind. Basierend auf dieser Realisierung berechnet man eine Teststatistik und vergleicht diese abschließend mit einem kritischen Wert, um dann entweder die Nullhypothese nicht abzulehnen oder die Nullhypothese abzulehnen. Im folgenden Abschnitt wollen wir der Frage nachgehen, wie vor dem Hintergrund von Null- und Alternativhypothese dabei der kritische Wert eines kritischen Wert-basierten Tests so bestimmt werden kann, dass man im Sinne der frequentistischen Wahrscheinlichkeit möglichst gute Testentscheidungen trifft.
33.2 Testgütekriterien und Testkonstruktion
Die Tatsache, dass in einem Testszenario der wahre, aber unbekannte, Parameter im Bereich der Nullhypothese oder der Alternativhypothese liegen kann und man gleichzeitig basierend auf dem Wert des Tests die Nullhypothese entweder ablehnen oder nicht ablehnen kann, impliziert, dass eine Testentscheidung richtig oder falsch sein kann. Untenstehende Definition soll dahingehend zunächst begriffliche Klarheit schaffen.
Definition 33.9 (Richtige Testentscheidungen und Testfehler) Gegeben seien ein Testszenario und ein Test. Dann gibt es mit dem Nichtablehnen der Nullhypothese \(\phi(y) = 0\), wenn die Nullhypothese \(\theta \in \Theta_0\) zutrifft, und dem Ablehnen der Nullhypothese \(\phi(y) = 1\), wenn die Alternativhypothese \(\theta \in \Theta_1\) zutrifft, zwei Formen der richtigen Testentscheidung. Ebenso gibt es zwei Arten von Testfehlern. Das Ablehnen der Nullhypothese \(\phi(y) = 1\), wenn die Nullhypothese \(\theta \in \Theta_0\) zutrifft, heißt Typ I Fehler. Das Nichtablehen der Nullhypothese \(\phi(y) = 0\), wenn die Alternativhypothese \(\theta \in \Theta_1\) zutrifft, heißt Typ II Fehler.
Abbildung 33.1 gibt eine Übersicht zu den möglichen richtigen Testentscheidungen und Testfehlern bei Durchführung eines Tests. Natürlich möchte man präferentiell eine richtige Testentscheidung treffen. Das entscheidende Werkzeug, um vor dem frequentistischen Hintergrund des Testszenarios möglichst gute Tests zu konstruieren, ist dann die sogenannte Testgütefunktion.
Definition 33.10 (Testgütefunktion) Gegeben sei ein Testszenario und ein Test \(\phi\). Dann ist die Testgütefunktion von \(\phi\) definiert als \[\begin{equation} q_{\phi} : \Theta \to [0,1], \theta \mapsto q_{\phi}(\theta) := \mathbb{P}_\theta(\phi(y) = 1). \end{equation}\] Für \(\theta \in \Theta_1\) heißt \(q_\phi\) auch Trennschärfefunktion oder Powerfunktion.
Man beachte, dass \(\mathbb{P}_\theta\) in Definition 33.10 die Verteilung der Zufallsvariable \(\phi(y)\) unter der Annahme, dass die Verteilung von \(y\) durch \(\theta\) festgelegt ist, bezeichnen soll. Für jedes \(\theta \in \Theta\) liefert \(q_\phi\) also die Wahrscheinlichkeit dafür, dass die Nullhypothese durch den Test \(\phi\) abgelehnt wird. Für diese Wahrscheinlichkeiten gelten mit den Begriffen des kritischen Bereichs (vgl. Definition 33.6) und des Ablehnungsbereichs (vgl. Definition 33.7) \[\begin{equation} \mathbb{P}_\theta(\phi(y) = 1) = \mathbb{P}_\theta(\gamma(y) \in A) = \mathbb{P}_\theta (y \in K). \end{equation}\] Die Testgütefunktion ist spezifisch für einen gegebenen Test. Ändert sich der Test, zum Beispiel, weil bei einem kritischen Wert-basierten Test ein anderer kritischer Wert gewählt wird, ändern sich obige Wahrscheinlichkeiten und damit die Testgütefunktion.
Mithilfe der Testgütefunktion geschieht die Testkonstruktion dann gemäß folgender Überlegungen. Im Idealfall hätte man einen Test \(\phi\) mit \[\begin{equation} q_\phi(\theta) = \mathbb{P}_\theta(\phi(y) = 1) = 0 \mbox{ für } \theta \in \Theta_0 \mbox{ und } q_\phi(\theta) = \mathbb{P}_\theta(\phi(y) = 1) = 1 \mbox{ für } \theta \in \Theta_1. \end{equation}\] Die Testentscheidung eines solchen Tests wäre mit Wahrscheinlichkeit 1 richtig, da ein solcher Test die Nullhypothese mit Wahrscheinlichkeit 0 ablehnt, wenn sie zutrifft, und die Nullhypothese mit Wahrscheinlichkeit 1 ablehnt, wenn sie nicht zutrifft. Allgemeiner sind natürlich kleine Werte von \(q_\phi\) für \(\theta \in \Theta_0\), also kleine Wahrscheinlichkeiten dafür, die Nullhypothese abzulehnen, wenn sie zutrifft, und große Werte von \(q_\phi\) für \(\theta \in \Theta_1\), also große Wahrscheinlichkeiten dafür, die Nullhypothese abzulehnen, wenn sie nicht zutrifft, zur Testfehlerminimierung günstig. Allerdings bestehen im Allgemeinen Abhängigkeiten zwischen den Werten der Testgütefunktion für \(\theta \in \Theta_0\) und \(\theta \in \Theta_1\), wie folgende Beispiele illustrieren sollen.
Beispiel (A) Es sei \(\phi_a\) ein Test definiert durch \[\begin{equation} \phi_a: \mathcal{Y} \to \{0,1\}, y \mapsto \phi_a(y) := 0. \end{equation}\] \(\phi_a\) sei also ein Test, der die Nullhypothese unabhängig von den beobachteten Daten nie ablehnt. Für \(\phi_a\) gilt dann \[\begin{equation} q_{\phi_a}(\theta) = \mathbb{P}_\theta(\phi(y) = 1) = 0 \mbox{ für } \theta \in \Theta_0. \end{equation}\] Allerdings gilt für \(\phi_a\) dann auch automatisch \[\begin{equation} q_{\phi_a}(\theta) = \mathbb{P}_\theta(\phi(y) = 1) = 0 \mbox{ für } \theta \in \Theta_1. \end{equation}\] \(\phi_a\) hat also eine minimale Sensitivität dafür, die Tatsache, dass die Alternativhypothese zutrifft, zu detektieren.
Beispiel (B) Umgekehrt sei \(\phi_b\) ein Test definiert durch \[\begin{equation} \phi_b : \mathcal{Y} \to \{0,1\}, y \mapsto \phi_b(y) := 1. \end{equation}\] \(\phi_b\) sei also ein Test, der die Nullhypothese, unabhängig von den beobachteten Daten immer ablehnt. Für \(\phi_b\) gilt dann \[\begin{equation} q_{\phi_b}(\theta) = \mathbb{P}_\theta(\phi(y) = 1) = 1 \mbox{ für } \theta \in \Theta_1. \end{equation}\] \(\phi_b\) ist also maximal sensitiv für das Zutreffen der Alternativhypothese. Allerdings gilt für \(\phi_b\) dann auch automatisch \[\begin{equation} q_{\phi_b}(\theta) = \mathbb{P}_\theta(\phi(y) = 1) = 0 \mbox{ für } \theta \in \Theta_0, \end{equation}\] und \(\phi_b\) resultiert auch immer in der Ablehnung der Nullhypothese, wenn diese zutrifft und generiert in diesem Sinne viele falsch positive Resultate.
Vor dem Hintergrund dieser Beispiele muss es also das Ziel der Testkonstruktion sein, eine angemessene Balance zwischen kleinen Werten der Testgütefunktion bei Zutreffen der Nullhypothese und großen Werten der Testgütefunktion bei Zutreffen der Alternativhypothese zu finden. Die populärste Methode, dies zu erreichen ist es, in einem ersten Schritt einen kleinen Wert \(\alpha_0 \in [0,1]\) zu wählen und sicherzustellen, dass \[\begin{equation}\label{eq:signifikanz} q_\phi(\theta) \le \alpha_0 \mbox{ für alle } \theta \in \Theta_0, \end{equation}\] dass also die Wahrscheinlichkeit für das Ablehnen der Nullhypothese, wenn diese zutrifft, also die Wahrscheinlichkeit für einen Typ I Fehler, höchstens \(\alpha_0\) beträgt. Konventionelle Werte für ein solches \(\alpha_0\) sind \(\alpha_0 := 0.001\) und \(\alpha_0 := 0.05\). Unter allen Tests (und, bei Optimierung von Stichprobengrößen, Frequentistischen Inferenzmodellen), die die Ungleichung \(\eqref{eq:signifikanz}\) erfüllen, sucht man dann in einem zweiten Schritt einen Test, für den \(q_\phi(\theta)\) für \(\theta \in \Theta_1\) so groß wie möglich ist. Dieses zweischrittige Vorgehen ist nicht alternativlos, man könnte ja beispielsweise auch eine lineare Kombinationen von Typ I und Typ II Fehlern gleichzeitig minimieren. Allerdings ist das skizzierte zweischrittige Vorgehen das in der Anwendung populärste, sodass wir uns in der Folge darauf beschränken. Ungleichung \(\eqref{eq:signifikanz}\) motiviert dann zunächst die Definition der Begriffe des Level-\(\alpha_0\)-Tests, des Signifikanzlevel \(\alpha_0\) und des Testumfangs \(\alpha\).
Definition 33.11 (Level-\(\alpha_0\)-Test, Signifikanzlevel \(\alpha_0\) und Testumfang \(\alpha\)) Gegeben seien ein Testszenario, ein Test \(\phi\), seine Testgütefunktion \(q_\phi\) und ein \(\alpha_0 \in [0,1]\). \(\phi\) heißt ein Level-\(\alpha_0\)-Test, wenn gilt, dass \[\begin{equation} q_\phi(\theta) \le \alpha_0 \mbox{ für alle } \theta \in \Theta_0. \end{equation}\] Wenn \(\phi\) ein Level-\(\alpha_0\)-Test ist, nennt man den Wert \(\alpha_0\) auch das Signifikanzlevel des Tests. Weiterhin heißt die Zahl \[\begin{equation} \alpha := \max_{\theta \in \Theta_0} q_\phi(\theta) \end{equation}\] der Testumfang von \(\phi\).
Nach Definition 33.11 ist der Testumfang \(\alpha\) die maximale Wahrscheinlichkeit für einen Typ I Fehler und ein Test ist dann, und nur dann, ein Level-\(\alpha_0\)-Test, wenn diese maximale Wahrscheinlichkeit kleiner oder gleich dem Signifikanzlevel \(\alpha_0\) ist. Es ist dabei für die Anwendung wichtig, sich die feinen Unterschiede zwischen der Wahrscheinlichkeit eines Typ I Fehlers, dem Testumfang und dem Signifikanzlevel eines Tests zu verdeutlichen. Vor dem Hintergrund des Unterschiedes von einfachen und zusammengesetzten Nullhypothesen (vgl. Definition 33.2) muss man zunächst die Begriffe der Typ I Fehler Wahrscheinlichkeit und des Testumfangs differenzieren. Bei einer einfachen Nullhypothese \(\Theta_0\) ist der Testumfang immer gleich der Wahrscheinlichkeit eines Typ I Fehlers, da gilt dass \[\begin{equation} \alpha := \max_{\theta \in \Theta_0} q_\phi(\theta) = \max_{\theta \in \{\theta_0\}} q_\phi(\theta) = q_\phi(\theta_0) = \mathbb{P}_{\theta_0}(\phi(y) = 1). \end{equation}\] Bei einer zusammengesetzten Nullhypothese \(\Theta_0\) gibt es je nach Wert von \(\theta \in \Theta_0\) verschiedene Wahrscheinlichkeiten für einen Typ I Fehler. Die größte dieser Wahrscheinlichkeiten ist der Testumfang \[\begin{equation} \alpha := \max_{\theta \in \Theta_0} q_\phi(\theta) = \max_{\theta \in \Theta_0} \mathbb{P}_{\theta}(\phi(y) = 1). \end{equation}\] Ebenso klar sollte man die Begriffe des Signifikanzlevel \(\alpha_0\) und des Testumfangs \(\alpha\) voneinander abgrenzen. Ein Signifikanzlevel ist eine frei gewählte obere Grenze für die maximale Wahrscheinlichkeit eines Typ I Fehlers. Die tatsächliche maximale Wahrscheinlichkeit für einen Typ I Fehler, kann mit dieser identisch sein, wie in den meisten Fällen der Kapitel 33.3 diskutierten Beispiele, muss es aber nicht, wie zum Beispiel in multiplen Testszenarien mit nicht unabhängigen Stichprobenvariablen. Man nennt dementsprechend einen Test exakt, wenn sein Testumfang mit seinem Signifikanzlevel identisch ist, wenn also gilt \[\begin{equation} \alpha = \alpha_0. \end{equation}\] Ein Test, für den der Testumfang kleiner als sein Signifikanzlevel ist, für den also gilt \[\begin{equation} \alpha < \alpha_0, \end{equation}\] wird konservativ genannt. Ein Test schließlich, dessen Testumfang größer als sein Signifikanzlevel ist, \[\begin{equation} \alpha > \alpha_0 \end{equation}\] und der damit natürlich kein Level-\(\alpha_0\)-Test sein kann, wird liberal genannt.
p-Wert
Ein definierendes Charakterstikum eines Tests ist seine binäre Wertemenge. Resultat eines Tests ist entweder \(\phi(y) = 0\), die Nullhypothese wird nicht abgelehnt, oder \(\phi(y) = 1\), die Nullhypothese wird abgelehnt. Als finales Resultat einer Datenanalyse wird dabei die einem Datensatz innewohnende Information maximal komprimiert. Insbesondere supprimiert das alleinige Berichten des Testergbnisses interessante Information über das Signal-zu-Rauschen-Verhältnis des betrachteten Datensatzes. So ist es ja beispielsweise möglich, dass die Nullhypothese im Kontext eines kritischen Wert-basierten Tests deshalb abgelehnt wird, weil die Teststatistik den kritischen Wert nur um wenige Nachkommastellen übertroffen. Andererseits ist es genauso möglich, dass die Nullhypothese abgelehnt wird, weil die Testsstatistik ein Vielfaches des kritischen Werts angenommen hat. In beiden Fällen wäre das Testergebnis mit \(\phi(y) = 1\) identisch. Neben der reinen Testumfangkontrolle eines Tests und des Berichtens des binären Testergebnisses hat es sich deshalb für kritische Wert-basierte Tests eingebürgert, basierend auf dem beobachteten Wert der Teststatistik auch alle Werte des Signifikanzlevel \(\alpha_0\), für die ein Level-\(\alpha_0\)-Test das Ergebnis \(\phi(y) = 1\) hätte, für die die Nullhypothese also abgelehnt würde, zu betrachten. Diese Überlegung führt auf folgende allgemeine Definition des sogenannten p-Werts, wobei p für probability steht.
Definition 33.12 (p-Wert) \(\phi\) sei ein Test. Dann ist der das kleinste Signifikanzlevel \(\alpha_0\), bei dem die Nullhypothese basierend auf einem vorliegenden Wert der Teststatistik abgelehnt wird.
Insbesondere in einfachen Anwendungsbeispielen, wie dem in Kapitel 33.3.1 betrachteten Einstichproben-T-Test-Szenario spiegeln p-Werte dann die Antwort auf die intuitive Frage, wie wahrscheinlich es im Frequentistischen Sinne wäre, den beobachteten oder einen extremeren Wert der Teststatistik unter der Annahme eines Nullmodells zu observieren. Dabei ist in vielen Bereichen der Grundlagenwissenschaft das Berichten von p-Werten sehr populär, aber auch umstritten (vgl. Wasserstein et al. (2019)). Dabei gilt es, p-Werte nicht überzuinterpretieren. Basierend auf dem Gesagten gibt es keine Gründe, zu folgenden Fehlschlüssen zu gelangen, trotzdem weisen wir vorsorglich daraufhin: p-Werte quantifizieren nicht die Wahrscheinlichkeit dafür, dass die Nullhypothese wahr ist, man kann aufgrund von \(\mbox{p} < 0.05\) nicht darauf schließen, dass die Alternativhypothese zutrifft, und man kann aufgrund von \(\mbox{p} \ge 0.05\) nicht darauf schließen, dass die Nullhypothese zutrifft.
Ebenso wie der Wert einer Teststatistik und eines Tests quantifizieren p-Werte das in einem vorliegenden Datensatz beobachtete Signal-zu-Rauschen-Verhältnis. Nicht weniger, aber auch nicht mehr.
Anmerkungen zur Wahl von Null- und Alternativhypothese
Wir wollen diesen Abschnitt mit einigen Anmerkungen zur Durchführung von Hypothesentests abschließen. Vor dem Hintergrund der skizzierten Theorie der Hypothesentests stellt sich zunächst die Frage, wie in einem konkreten Anwendungskontext die Zuordnung von Null- und Alternativhypothese zu den Gegenständen des wissenschaftlichen Interesses, also zu den wissenschaftlichen Hypothesen, vorgenommen wird.
Möchte man beispielsweise einen Test durchführen, um im Sinne der frequentistischen Inferenz zu entscheiden, ob ein bestimmtes Psychotherapieverfahren in einer klinischen Studie wirksam war oder nicht, stellt sich die Frage, ob die Abwesenheit eines Therapieeffekts als Null- oder als Alternativhypothese zu formulieren ist.
Hierzu ist anzumerken, dass das oben beschriebene zweischrittige Vorgehen zur Testkonstruktion – bei dem zunächst durch die Wahl eines Signifikanzniveaus der Testumfang festgelegt wird und erst in einem zweiten Schritt dafür gesorgt wird, dass die Wahrscheinlichkeit, die Nullhypothese abzulehnen, sofern die Alternativhypothese zutrifft, möglichst groß ist – eine deutliche Asymmetrie in der Behandlung von Null- und Alternativhypothese impliziert. Mit diesem Vorgehen werden Typ-I-Fehler als schwerwiegender eingestuft als Typ-II-Fehler.
Dies legt eine mögliche Strategie zur Festlegung von Null- und Alternativhypothese nahe: Die Nullhypothese ist jene wissenschaftliche Hypothese, bei deren zugehöriger Testentscheidung man einen Fehler besonders vermeiden möchte bzw. deren Fehlerwahrscheinlichkeit man primär kontrollieren will. In der Wissenschaft gilt es als gängiger Standard, die falsche Bestätigung der eigenen, favorisierten Theorie (etwa die fälschliche Bestätigung, dass ein selbst entwickeltes Psychotherapieverfahren wirksamer ist als ein anderes) als schwerwiegenderen Fehler zu bewerten als deren falsche Zurückweisung.
Entsprechend sollte die falsche Konfirmation der eigenen Theorie einen Typ-I-Fehler darstellen, während ihre falsche Ablehnung als Typ-II-Fehler zu klassifizieren ist. Damit die falsche Konfirmation der eigenen Theorie tatsächlich einem Typ-I-Fehler entspricht – also dem Ablehnen der Nullhypothese, obwohl diese zutrifft –, muss die eigene Theorie als Alternativhypothese formuliert werden. Die fälschliche Ablehnung der Alternativhypothese stellt dann einen Typ-II-Fehler dar.
Intuitiv ergibt sich somit folgende Zuordnung: \[\begin{align*} \begin{split} \mbox{Nicht-favorisierte wissenschaftliche Hypothese} & \to \mbox{Nullhypothese} \\ \mbox{Favorisierte wissenschaftliche Hypothese} & \to \mbox{Alternativhypothese} \end{split} \end{align*}\]
Hypothesentests in Entscheidungskontexten und Grundlagenwissenschaft
Weiterhin stellt sich die Frage, ob man zur Evaluation wissenschaftlicher Hypothesen überhaupt einen Hypothesentest durchführen sollte. Oberflächlich betrachtet liefern Hypothesentests zunächst einfache binäre Aussagen der Form “Die Hypothese ist gegeben die Evidenz abzulehnen oder zu akzeptieren”. Solche Aussagen können in konkreten Entscheidungskontexten hilfreich sein, wenn tatsächlich eine Entscheidung getroffen werden muss. Allerdings ist hierzu anzumerken, dass frequentistische Hypothesentests – wie gesehen – ohne explizite Entscheidungsnutzenfunktion formuliert sind und potenzielle Entscheidungskosten somit nicht explizit in die Entscheidungsfindung einbezogen werden. Für diesen Zweck existiert eine Reihe sehr zugänglicher Theorien, die es erlauben, im langfristigen Mittel gute Entscheidungen unter Unsicherheit zu treffen, vgl. zum Beispiel Pratt et al. (1995), Puterman (1994) oder Kochenderfer et al. (2022).
Wendet man sich von praktisch relevanten Entscheidungskontexten dem Bereich der Grundlagenwissenschaften zu, deren Wesen es ja gerade ist, keine finalen Wahrheiten zu etablieren, sondern vielmehr das Ausmaß der Unsicherheit über den jeweils aktuellen Theoriestand zu quantifizieren und zu kommunizieren, erscheint die Binarität der Hypothesentestentscheidung im besten Fall überflüssig, im schlimmsten Fall grob irreführend. Fragestellungen der Grundlagenwissenschaften sollten daher prinzipiell nicht als Entscheidungsprobleme formuliert werden.
Trotz der weit verbreiteten Auffassung, dass bayesianische Herangehensweisen wie Positive Predictive Values oder Bayes Factors hier Vorteile böten, ist dies nicht der Fall, solange die mit einer bestimmten Modellpräferenz verbundene Unsicherheit nicht klar mitkommuniziert wird. Nichtsdestotrotz bleibt das frequentistische Hypothesentesten auch in der grundlagenorientierten Wissenschaftsgemeinschaft weiterhin sehr populär, mitunter allerdings nur unter dem Deckmantel von Forderungen nach Grundlagenstudien mit “höherer Power”. Um einen Zugang zur psychologisch-naturwissenschaftlichen Literatur zu behalten, ist es daher bislang unumgänglich, sich auch mit dem aus grundlagenwissenschaftlicher Perspektive eigentlich wenig sinnvollen Hypothesentesten auseinanderzusetzen.
33.3 Testbeispiele
33.3.1 Einstichproben-T-Test
Das Anwendungsszenario eines Einstichproben-T-Test ist dadurch gekennzeichnet, dass \(n\) univariate Datenpunkte einer Stichprobe (Gruppe) randomisierter experimenteller Einheiten betrachtet werden, von denen angenommen wird, dass sie Realisierungen von \(n\) unabhängigen und identisch normalverteilten Zufallsvariablen sind. Hinsichtlich der identischen univariaten Normalverteilungen \(N(\mu,\sigma^2)\) dieser Zufallsvariablen wird angenommen, dass sowohl der Erwartungswertparameter \(\mu\) als auch der Varianzparameter \(\sigma^2\) unbekannt sind. Schließlich wird vorausgesetzt, dass ein Interesse an einem inferentiellen Vergleich des unbekannten Erwartungswertparameters \(\mu\) mit einem vorgebenenen Wert \(\mu_0\) im Sinne eines Hypothesentests besteht.
Dabei gibt es allerdings mindestens vier Szenarien, die potenziell von Interesse sein können. Ein erster Fall ist das Szenario einer einfachen Nullhypothese und einer einfachen Alternativhypothese, \[\begin{equation} H_0:\mu = \mu_0 \mbox{ und } H_1: \mu = \mu_1. \end{equation}\] Dieser Fall ist in der Theorie sehr gut verstanden und Grundlage des sogenannten Neymann-Pearson-Lemmas (Neyman & Pearson (1933)). Seine praktische Relevanz ist aber eher gering, da die Alternativhypothese von einer genauen Spezifikation des Erwartungswertparameters ausgeht. Ein zweiter Fall ist das Szenario einer einfachen Nullhypothese und einer zusammengesetzten Alternativhypothese \[\begin{equation} H_0:\mu = \mu_0 \mbox{ und } H_1:\mu \neq \mu_0. \end{equation}\] In diesem Fall spricht man auch von einer ungerichteten Hypothese und nutzt in der Regel einen zweiseitigen Test. Intuitiv entspricht dies der ungerichteten Frage nach inferenzieller Evidenz für einen Unterschied. Es ist dieser Fall, den wir im Folgenden detailliert betrachten werden. Schließlich gibt es noch mindestens zwei Szenarien mit zusammengesetzten Null- und Alternativhypothesen, etwa der Form \[\begin{equation} H_0:\mu \le \mu_0 \mbox{ und } H_1:\mu > \mu_0 \mbox{ oder } H_0:\mu \ge \mu_0 \mbox{ und } H_1:\mu < \mu_0. \end{equation}\] Man spricht in diesem Fall auch von gerichteten Hypothesen und nutzt in der Regel einseitige Tests. Diese Fälle betrachten wir im Folgenden nicht.
Frequentistisches Inferenzmodell
Definition 33.13 (Frequentistisches Inferenzmodell des Einstichproben-T-Tests) Das Frequentistische Inferenzmodell des Einstichproben-T-Tests ist das Normalverteilungsmodell \[\begin{equation} y_1,...,y_n \sim N(\mu,\sigma^2) \mbox{ mit } (\mu,\sigma^2)\in \mathbb{R} \times \mathbb{R}_{>0}. \end{equation}\]
Wir erinnern daran, dass aus generativer Sicht das Normalverteilungsmodell dem Modell \[\begin{equation} y_i = \mu + \varepsilon_i \mbox{ mit } \varepsilon_i \sim N(0,\sigma^2) \mbox{ für } i = 1,...,n \end{equation}\] entspricht (vgl. Beispiel 30.5). Die Annahme unabhängig und identisch normalverteilter Zufallsvariablen als Grundlage der Modellierung der Beobachtung von \(n\) Datenpunkten ist wie in Beispiel 30.5 gesehen äquivalent zu der Annahme, dass sich jede einen Datenpunkt modellierende Zufallsvariable \(y_i\) als Summe aus einem festen, wahren, aber unbekannten, über Zufallsvariablen konstanten Wert \(\mu\) und aus einem Zufallsvariablen- bzw. Datenpunkt-spezifischen Abweichungsterm \(\varepsilon_i\) ergibt. Dabei modelliert, wie gesehen, \(\mu\) den tatsächlichen im wissenschaftlichen Anwendungskontext angenommenen Effekt von Interesse. \(\varepsilon_i\) dagegen modelliert den Aspekt der Datenvariabilität, der nicht durch \(\mu\) erklärt werden kann, sondern im Sinne des Zentralen Grenzwertsatzes aus der Summation unendlich vieler Störeinflüsse hervorgeht und damit als Unsicherheit über die Erklärung der Datenvariabilität durch \(\mu\) verbleibt.
Testhypothesen
Wir betrachten den Fall des Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese.
Definition 33.14 (Einfache Nullhypothese und zusammengesetzte Alternativhypothese des Einstichproben-T-Tests) Gegeben sei das Frequentistische Inferenzmodell des Einstichproben-T-Tests \[\begin{equation} y_1,...,y_n \sim N(\mu,\sigma^2) \mbox{ mit } (\mu,\sigma^2)\in \mathbb{R} \times \mathbb{R}_{>0} \end{equation}\] und es sei \(\Theta := \mathbb{R}\) der Parameterunterraum des Parameters von Interesse \(\mu\). Dann sind für den Nullhypothesenparameterwert \(\mu_0 \in \mathbb{R}\) die einfache Nullhypothese und die zusammengesetzte Alternativhypothese des Einstichproben-T-Tests gegeben durch \[\begin{equation} \Theta_0 := \{\mu_0\} \Leftrightarrow H_0 : \mu = \mu_0 \mbox{ und } \Theta_1 := \mathbb{R} \setminus \{\mu_0\} \Leftrightarrow H_1 : \mu \neq \mu_0. \end{equation}\]
Man beachte, dass die einfache Nullhypothese und die zusammengesetzte Alternativhypothese durch den Wert \(\mu_0 \in \mathbb{R}\) parameterisiert sind. Je nach Wahl von \(\mu_0\) ergeben sich also verschiedene Hypothesenszenarien. Wird beispielsweise \(\mu_0 := 0\) gewählt, so entspricht die Nullhypothese \(\Theta_0 := \{0\}\) der Aussage, dass der wahre, aber unbekannte, Parameter \(\mu\) gleich \(0\) ist und die Alternativhypothese \(\Theta_1 := \mathbb{R} \setminus \{0\}\) der Aussage, dass der wahre, aber unbekannte, Parameter \(\mu\) ungleich \(0\) ist. Wird dagegen beispielsweise \(\mu_0 := 2\) gewählt, so entspricht die Nullhypothese \(\Theta_0 := \{2\}\) der Aussage, dass der wahre, aber unbekannte, Parameter \(\mu\) gleich \(2\) ist und die Alternativhypothese \(\Theta_1 := \mathbb{R} \setminus \{2\}\) der Aussage, dass der wahre, aber unbekannte, Parameter \(\mu\) ungleich \(2\) ist. Im Anwendungskontext ist \(\mu_0\) dementsprechend ein frei gewählter (und damit natürlich bekannter) Parameter des Einstichproben-T-Tests, wohingegen \(\mu\) wahr, aber unbekannt, ist und bleibt.
Definition der Teststatistik
Mit der Einstichproben-T-Test-Statistik definieren wir nun eine Teststatistik, die als Grundlage eines kritischen Wert-basierten Tests dienen kann und deren Betrag eine Abweichung von der Nullhypothese anzeigen kann.
Definition 33.15 (Einstichproben-T-Test-Statistik) Gegeben sei das Testszenario eines Einstichproben-T-Tests mit Stichprobe \(y_1,...,y_n\), Stichprobenmittel \(\bar{y}\), Stichprobenstandardabweichung \(S\) und Nullhypothesenparameter \(\mu_0\). Dann ist die Einstichproben-T-Test-Statistik definiert als \[\begin{equation} T := \sqrt{n}\frac{\bar{y} - \mu_0}{S}. \end{equation}\]
Offenbar hat die Einstichproben-T-Test-Statistik eine hohe Ähnlichkeit mit der T-Konfidenzintervallstatistik (vgl. Definition 32.2). Man beachte allerdings, dass im Fall der Einstichproben-T-Test-Statistik der Nullhypothesenparameter \(\mu_0\) nicht identisch mit dem in der T-Konfidenzintervallstatistik auftauchendem wahren, aber unbekannten, Parameterwert \(\mu\) sein muss.
Da die Einstichproben-T-Test-Statistik im Kontext des Einstichproben-T-Tests zentral ist, ist es sinnvoll, sich ihrer intuitiven Mechanik bewusst zu sein. Im Zähler des Bruchs der Einstichproben-T-Test-Statistik erscheint zunächst die Differenz zwischen dem Stichprobenmittel \(\bar{y}\) und dem unter der Nullhypothese angenommenen Parameter \(\mu_0\). Wie bereits gesehen, ist das Stichprobenmittel ein unverzerrter Schätzer des Erwartungswertparameters \(\mu\) der Stichprobenvariablen. Die Differenz \(\bar{y} - \mu_0\) stellt somit eine Schätzung der Abweichung des wahren, aber unbekannten Erwartungswertparameters vom Nullhypothesenparameter dar und liefert dem Betrag nach Evidenz für eine Abweichung von der Nullhypothese. Grob betrachtet stellt der Zähler \(\bar{y} - \mu_0\) damit ein Maß für das der Stichprobe innewohnende “Signal” dar, verstanden als Abweichung von der Nullhypothese bzw. als “systematische Variabilität”.
Der Nenner der Einstichproben-T-Test-Statistik erlaubt es, dieses Signal in Einheiten der Stichprobenstandardabweichung \(S\) auszudrücken. Gilt beispielsweise \(\bar{y} - \mu_0 = 2\) und ist \(S = 1\), so beträgt die Abweichung des Stichprobenmittels vom Nullhypothesenparameter zwei Standardabweichungen. Ist dagegen \(S = 2\), so entspricht die Abweichung hier einer Standardabweichung. Darüber hinaus ist der Nenner \(S\) ein Maß für die beobachtete Datenvariabilität und ein Schätzer der Standardabweichung \(\sigma\) der Fehlerterme in der generativen Form des Einstichproben-T-Test-Modells. Grob betrachtet repräsentiert der Nenner der Einstichproben-T-Test-Statistik somit das den Daten innewohnende “Rauschen” bzw. ihre “unsystematische Variabilität”. Insgesamt kann der Bruch \(\frac{\bar{y} - \mu_0}{S}\) daher als Schätzung des “Signal-zu-Rauschen-Verhältnisses” der Daten interpretiert werden.
Schließlich wird dieses Verhältnis in der Einstichproben-T-Test-Statistik mit der Wurzel der Stichprobengröße \(\sqrt{n}\) gewichtet. Intuitiv reflektiert diese Gewichtung die Tatsache, dass einem gegebenen Signal-zu-Rauschen-Verhältnis mehr Validität beigemessen werden kann, wenn es auf einer größeren Anzahl von Beobachtungen basiert, als wenn es auf wenigen Datenpunkten beruht.
Insgesamt liefert die Einstichproben-T-Test-Statistik somit eine skalare Zusammenfassung der den Daten innewohnenden Evidenz gegen die Nullhypothese, bei der sowohl die Datenvariabilität als auch der Stichprobenumfang berücksichtigt werden.
Verteilung der Teststatistik
Für die Verteilung der Einstichproben-T-Test-Statistik gilt nun folgendes Theorem.
Theorem 33.1 (Verteilung der Einstichproben-T-Test-Statistik) Gegeben sei das Testszenario eines Einstichproben-T-Tests mit Stichprobe \(y_1,...,y_n\), Stichprobenmittel \(\bar{y}\), Stichprobenstandardabweichung \(S\), Nullhypothesenparameter \(\mu_0\) und Einstichproben-T-Test-Statistik definiert als \[\begin{equation} T := \sqrt{n}\frac{\bar{y} - \mu_0}{S}. \end{equation}\] Dann ist \(T\) eine nichtzentrale \(t\)-Zufallsvariable mit Nichtzentralitätsparameter \[\begin{equation} d = \sqrt{n}\frac{\mu - \mu_0}{\sigma} \end{equation}\] und Freiheitsgradparameter \(n-1\), es gilt also \(T \sim t(d,n-1)\)
Man beachte, dass im Falle des Zutreffens der Nullhypothese der Nullhypothesenparameter \(\mu_0\) mit dem wahren, aber unbekannten, Erwartungswertparameter \(\mu\) identisch ist und der Nichtzentralitätsparameter der Verteilung der Einstichproben-T-Test-Statistik den Wert \(d = 0\) annimmt. Im Falle des Zutreffens der Nullhypothese des Einstichproben-T-Test-Szenarios ist die Einstichproben-T-Test-Statistik also eine \(t\)-verteilte Zufallsvariable mit Freiheitsgradparameter \(n-1\). Wir visualisieren die Verteilung der Einstichproben-T-Test-Statistik exemplarisch für ein Einstichproben-T-Test-Szenario mit \(n = 12\), wahren, aber unbekannten, Parametern \(\mu = 3\) und \(\sigma^2 = 2\) und Nullhypothesenparameter \(\mu_0 = 0\) in Abbildung 33.2 (B). Die Parameter dieser Verteilung ergeben sich dabei zu \[\begin{equation} d = \sqrt{n}\frac{\mu - \mu_0}{\sigma} = \sqrt{12}\frac{3 - 0}{\sqrt{2}} \approx 7.34 \end{equation}\] und \[\begin{equation} n - 1 = 11. \end{equation}\]
Testdefinition
Wir können nun den zweiseitigen Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese definieren und seine Testgütefunktion analysieren.
Definition 33.16 (Zweiseitiger Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese) Gegeben seien das Frequentistische Inferenzmodell des Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese und \(T\) bezeichne die Einstichproben-T-Test-Statistik. Dann ist der zweiseitige Einstichproben-T-Test mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese definiert als der zweiseitige kritische Wert-basierte Test \[\begin{equation} \phi : \mathcal{Y} \to \{0,1\}, y \mapsto \phi(y) := 1_{\{|T| \ge k\}} = \begin{cases} 1 & |T| > k \\ 0 & |T| \le k \end{cases}. \end{equation}\]
Der zweiseitige Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese nimmt also den Wert \(0\) an, wenn der Betrag der Einstichproben-T-Test-Statistik kleiner als der kritische Wert ist und er nimmt den Wert \(1\) an, wenn der Betrag der Einstichproben-T-Test-Statistik gleich oder größer als der kritische Wert ist.
Testgütefunktion
Für die Kontrolle des Testumfangs durch Wahl eines kritischen Werts und zur Bestimmung der Powerfunktion dieses Tests ist nun folgendes Theorem maßgeblich.
Theorem 33.2 (Testgütefunktion des zweiseitigen Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese) \(\phi\) sei der zweiseitige Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese. Dann ist die Testgütefunktion von \(\phi\) gegeben durch \[\begin{equation} q_{\phi} : \mathbb{R} \to [0,1], \mu \mapsto q_{\phi}(\mu) := 1 - \Psi(k;d_\mu,n-1) + \Psi(-k;d_\mu,n-1), \end{equation}\] wobei \(\Psi(\cdot; d_\mu, n-1)\) die KVF der nichtzentralen \(t\)-Verteilung mit Nichtzentralitätsparameter \[\begin{equation} d_\mu := \sqrt{n}\frac{\mu - \mu_0}{\sigma} \end{equation}\] und Freiheitsgradparameter \(n-1\) bezeichnet.
Beweis. Die Testgütefunktion des betrachteten Test im vorliegenden Testszenario ist definiert als \[\begin{equation} q_{\phi} : \mathbb{R} \to [0,1], \mu \mapsto q_{\phi}(\mu) := \mathbb{P}_{\mu}(\phi(y) = 1). \end{equation}\] Da die Wahrscheinlichkeiten für \(\phi(y) = 1\) und dafür, dass die zugehörige Teststatistik im Ablehnungsbereich des Tests liegt, gleich sind, benötigen wir also zunächst die Verteilung der Teststatistik. Wir haben oben bereits gesehen, dass die Einstichproben-T-Test-Statistik \(T\) anhand einer nichtzentralen \(t\)-Verteilung \(t(d_\mu,n-1)\) mit Nichtzentralitätsparameter \(d_\mu\) verteilt ist. Der Ablehnungsbereich des zweiseitigen Einstichproben-T-Tests ist \[\begin{equation} A = \,]-\infty, -k]\, \cup \,]k,\infty[. \end{equation}\] Mit diesem Ablehungsbereich ergibt sich dann \[\begin{align} \begin{split} q_\phi(\mu) & = \mathbb{P}_{\mu}(\phi(y) = 1) \\ & = \mathbb{P}_{\mu}\left(T \in ]-\infty, -k]\, \cup \,]k,\infty[ \right) \\ & = \mathbb{P}_{\mu}\left(T \in ]-\infty, -k]\right) + \mathbb{P}_{\mu}\left(T \in ]k,\infty[ \right) \\ & = \mathbb{P}_{\mu}(T \le - k) + \mathbb{P}_{\mu}(T > k) \\ & = \mathbb{P}_{\mu}(T \le - k) + (1-\mathbb{P}_{\mu}(T \le k)) \\ & = 1 - \mathbb{P}_{\mu}(T \le k) + \mathbb{P}_{\mu}(T \le - k) \\ & = 1 - \Psi(k; d_\mu, n-1) + \Psi(-k;d_\mu,n-1), \end{split} \end{align}\] wobei \(\Psi(\cdot; d_\mu,n-1)\) die KVF der nichtzentralen T-Verteilung mit Nichtzentralitätsparameter \(d_\mu\) und Freiheitsgradparameter \(n-1\) bezeichnet.
In Abbildung 33.3 visualisieren wir die Testgütefunktion des zweiseitigen Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese aus Theorem 33.2 für \(\sigma^2 = 9\) und \(\mu_0 = 4\) in Abhängigkeit vom kritischen Wert \(k\). Man beachte dabei zunächst, dass die Testgütefunktion als Funktion von \(\mu\) sowohl das Szenario des Zutreffens der Nullhypothese \(\mu = \mu_0\) als auch das Szenario des Zutreffens der Alternativhypothese \(\mu \neq \mu_0\) abdeckt. Man beachte weiterhin, dass der Wert der Testgütefunktion, also die Wahrscheinlichkeit dafür, dass der Test den Wert 1 annimmt, sowohl bei positiven als auch bei negativen Abweichungen des wahren, aber unbekannten, Erwartungswertparameters \(\mu\) vom Nullhypothesenparameter \(\mu_0\) ansteigt. Dies ist natürlich der Tatsache geschuldet ist, dass die Testentscheidung auf dem Betrag der Teststatistik beruht. Schließlich ist die genaue Form und Lage der Testgütefunktion von der Wahl des kritischen Werts \(k\) abhängig. Wird dieser größer gewählt, ist also ein größerer absoluter Wert der Teststatistik für dafür notwendig, dass der Test den Wert 1 annimmt, so ist die Wahrscheinlichkeit dafür, bei ansonsten konstanten Parametern, kleiner als bei kleineren Werten des kritischen Werts.
Testumfangkontrolle
Die Werte der Testgütefunktion bei \(\mu = \mu_0\) in Abbildung 33.3 geben einen visuellen Eindruck davon, wie der kritische Wert den Testumfang kontrolliert. Die exakte Bestimmung des kritischen Werts bei einem gewünschten Testumfang ist Inhalt folgenden Theorems.
Theorem 33.3 (Testumfangkontrolle für den zweiseitigen Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese) \(\phi\) sei der zweiseitige Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese. Dann ist \(\phi\) ein Level-\(\alpha_0\)-Test mit Testumfang \(\alpha_0\), wenn der kritische Wert definiert ist durch \[\begin{equation} k_{\alpha_0} := \Psi^{-1}\left(1 - \frac{\alpha_0}{2}; n-1 \right), \end{equation}\] wobei \(\Psi^{-1}(\cdot; n-1)\) die inverse KVF der \(t\)-Verteilung mit Freiheitsgradparameter \(n-1\) bezeichnet.
Beweis. Damit der betrachtete Test ein Level-\(\alpha_0\)-Test ist, muss bekanntlich \(q_\phi(\mu) \le \alpha_0\) für alle \(\mu \in \{\mu_0\}\), also hier \(q_\phi(\mu_0) \le \alpha_0\), gelten. Weiterhin ist der Testumfang des betrachteten Tests durch \(\alpha = \max_{\mu \in \{\mu_0\}} q_\phi(\mu)\), also hier durch \(\alpha = q_\phi(\mu_0)\) gegeben. Wir müssen also zeigen, dass die Wahl von \(k_{\alpha_0}\) garantiert, dass \(\phi\) ein Level-\(\alpha_0\)-Test mit Testumfang \(\alpha_0\) ist. Dazu merken wir zunächst an, dass für \(\mu = \mu_0\) gilt, dass \[\begin{align} \begin{split} q_\phi(\mu_0) & = 1 - \Psi(k;d_{\mu_0},n-1) + \Psi(-k;d_{\mu_0},n-1) \\ & = 1 - \Psi(k;0,n-1) + \Psi(-k;0,n-1) \\ & = 1 - \Psi(k;n-1) + \Psi(-k;n-1), \\ \end{split} \end{align}\] wobei \(\Psi(\cdot;d,n-1)\) und \(\Psi(\cdot;n-1)\) die KVF der nichtzentralen \(t\)-Verteilung mit Nichtzentralitätsparameter \(d\) und Freiheitsgradparameter \(n-1\) sowie der \(t\)-Verteilung mit Freiheitsgradparameter \(n-1\), respektive, bezeichnen. Sei nun also \(k := k_{\alpha_0}\). Dann gilt \[\begin{align} \begin{split} q_\phi(\mu_0) & = 1 - \Psi(k_{\alpha_0};n-1) + \Psi(-k_{\alpha_0};n-1) \\ & = 1 - \Psi(k_{\alpha_0};n-1) + (1 - \Psi(k_{\alpha_0};n-1) \\ & = 2(1-\Psi(k_{\alpha_0};n-1)) \\ & = 2\left(1-\Psi\left(\Psi^{-1}\left(1- \frac{\alpha_0}{2} , n-1\right), n-1\right)\right) \\ & = 2\left(1 - 1 + \frac{\alpha_0}{2}\right) \\ & = \alpha_0, \end{split} \end{align}\] wobei die zweite Gleichung mit der Symmetrie der \(t\)-Verteilung folgt. Es folgt also direkt, dass bei der Wahl von \(k = k_{\alpha_0}\), \(q_\phi(\mu_0)\le \alpha_0\) ist und der betrachtete Test somit ein Level-\(\alpha_0\)-Test ist. Weiterhin folgt direkt, dass der Testumfang des betrachteten Tests bei der Wahl von \(k = k_{\alpha_0}\) gleich \(\alpha_0\) ist.
Man beachte, dass nach Theorem 33.3 der hier betrachtete Test insbesondere exakt ist, der Testumfang also mit dem Signifikanzlevel identisch ist. In Abbildung 33.4 visualisieren wir die Wahl des kritischen Werts \(k_{\alpha_0}\) in einem zweiseitigen Einstichproben-T-Test-Szenario mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese für \(\alpha_0 := 0.05\) und \(n =12\).
Folgender R Code demonstriert die Bestimmung des kritischen Werts des zweiseitigen Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese mithilfe der inversen KVF der \(t\)-Verteilung, die in R als die Funktion qt() implementiert ist. Darüber hinaus simuliert der Code \(10^6\) Stichprobenrealisationen für das hier betrachtete Testszenario bei Zutreffen der Nullhypothese und wertet den betrachteten Test aus. Es zeigt sich, dass die geschätzte Wahrscheinlichkeit dafür, dass der Test bei Zutreffen der Nullhypothese den Wert 1 annimmt, mit dem gewünschten Wert von \(\alpha_0 = 0.05\) sehr gut übereinstimmt.
Kritischer Wert = 2.2
Geschätzter Testumfang alpha = 0.05p-Wert
Der mit einem vorliegenden Wert der Teststatistik des zweiseitigen Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese assoziierte p-Wert ergibt sich aus folgendem Theorem wie folgt.
Theorem 33.4 (p-Wert des zweiseitigen Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese) Gegeben sei der zweiseitige Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese und \(t\) sei ein Wert der Einstichproben-T-Test-Statistik. Dann gilt \[\begin{equation} \mbox{p-Wert} = 2(1 - \Psi(\vert t \vert;n-1)), \end{equation}\] wobei \(\Psi(\cdot; n-1)\) die KVF der \(t\)-Verteilung mit Freiheitsgradparameter \(n-1\) bezeichnet.
Beweis. Nach Definition 33.12 ist der p-Wert das kleinste Signifikanzlevel \(\alpha_0\), bei dem für den betrachteten Test die Nullhypothese basierend auf dem Wert von \(t\) abgelehnt wird. Im vorliegenden Fall wird die Nullhypothese für jedes \(\alpha_0\) mit \[\begin{equation} \vert t \vert \ge \Psi^{-1}\left(1- \frac{\alpha_0}{2};n-1\right) \end{equation}\] abgelehnt, vgl. Theorem 33.3. Für diese \(\alpha_0\) gilt, dass \[\begin{equation} \alpha_0 \ge 2(1 - \Psi(\vert t \vert;n-1)), \end{equation}\] denn \[\begin{align} \begin{split} \vert t \vert & \ge \Psi^{-1}\left(1 - \frac{\alpha_0}{2}; n-1\right) \\ \Leftrightarrow \Psi(\vert t \vert; n-1) & \ge \Psi\left(\Psi^{-1}\left(1 - \frac{\alpha_0}{2}; n-1\right); n-1\right) \\ \Leftrightarrow \Psi(\vert t \vert; n-1) & \ge 1 - \frac{\alpha_0}{2} \\ \Leftrightarrow \mathbb{P}(T \le \vert t \vert) & \ge 1 - \frac{\alpha_0}{2} \\ \Leftrightarrow \frac{\alpha_0}{2} & \ge 1 - \mathbb{P}(T \le \vert t \vert) \\ \Leftrightarrow \alpha_0 & \ge 2(1 - \Psi(\vert t \vert;n-1)). \end{split} \end{align}\] Das kleinste \(\alpha_0 \in [0,1]\) mit \[\begin{equation} \alpha_0 \ge 2 \mathbb{P}(T \ge \vert t \vert) \end{equation}\] ist dann entsprechend \[\begin{equation} \alpha_0 = 2(1 - \Psi(\vert t \vert;n-1)). \end{equation}\]
In Abbildung 33.5 visualisieren wir die Bestimmung von p-Werten für \(t = 2.26\) und für \(t = 3.81\), welche sich zu \(\mbox{p} = 0.045\) und \(\mbox{p} = 0.003\), respektive, ergeben. Man beachte, dass zum Beispiel der p-Wert zu \(t = -2.26\) auch \(\mbox{p} = 0.045\) beträgt.
Powerfunktion
Die Powerfunktion eines Tests ist die Testgütefunktion eines Tests für den Bereich des Parameterraums, der der Alternativhypothese entspricht. Änderungen im Wert der Powerfunktion eines Tests, oft einfach als Power des Tests bezeichnet, ergeben sich also zunächst einmal durch Änderungen des Wertes des wahren, aber unbekannten, Parameters im Bereich der Alternativhypothese. Allerdings hat es sich eingebürgert, die Wahrscheinlichkeit dafür, dass ein Test den Wert 1 annimmt, also die Nullhypothese abgelehnt wird, nicht ausschließlich als Funktion des wahren, aber unbekannten, Parameters, sondern auch weiterer und in der praktischen Anwendung relevanter, Parameter eines Testszenarios zu betrachten. An erster Stelle ist hier der Stichprobenumfangs \(n\) von Interesse. Im Kontext der praktischen Durchführung von Poweranalysen fragt man dann meist danach, welcher Stichprobenumfang bei Annahme eines Wertes für den wahren, aber unbekannten, Parameter im Bereich der Alternativhypothese mit einer bestimmten Wahrscheinlichkeit dafür, die Nullhypothese abzulehnen, assoziiert ist. Basierend auf der asymmetrischen Behandlung von Typ I und Typ II Fehlerwahrscheinlichkeiten (vgl. Kapitel 33.2) setzt man dahingehend zunächst ein Signifikanzlevel \(\alpha_0\) zur Kontrolle des Testumfangs fest. Für den hier diskutierten zweiseitigen Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese betrachten wir also die Testgütefunktion \[\begin{equation} q_\phi : \mathbb{R} \to [0,1], \mu \mapsto q_\phi(\mu) := 1 - \Psi(k_{\alpha_0}; d_\mu, n-1) + \Psi(-k_{\alpha_0}; d_\mu, n-1) \end{equation}\] bei kontrolliertem Testumfang, also für \[\begin{equation} k_{\alpha_0} := \Psi^{-1}\left(1-\frac{\alpha_0}{2};n-1\right) \end{equation}\] mit festem \(\alpha_0\) als Funktion des Nichtzentralitätsparameters \(d\) und des Stichprobenumfangs \(n\). Insbesondere hängt dabei der Nichtzentralitätsparameter \(d\) vom Verhältnis der wahren, aber unbekannten, Parameter \(\mu\) und \(\sigma^2\), also dem wahren, aber unbekannten, Signal-zu-Rauschen-Verhältnis des Testszenarios und \(k_{\alpha_0}\) von \(n\) ab. Diese Überlegungen führen auf folgende Definition.
Definition 33.17 (Powerfunktion des zweiseitigen Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese) Gegeben sei der zweiseitige Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese. Dann ist die Powerfunktion des Tests gegeben durch \[\begin{equation} \pi : \mathbb{R} \times \mathbb{N} \to [0,1], (d,n) \mapsto \pi(d,n) := 1 - \Psi(k_{\alpha_0}; d, n-1) + \Psi(-k_{\alpha_0}; d, n-1). \end{equation}\]
Folgender R Code demonstriert die Auswertung der Powerfunktion des zweiseitigen Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese in einem Szenario mit \(\alpha_0 := 0.05\) mithilfe der R Implementationen der KVF und der inversen KVF der nichtzentralen \(t\)-Verteilung, pt() bzw. qt().
alpha_0 = 0.05 # Signifikanzlevel
d_min = -5 # minimaler Nichtzentralitätsparameter
d_max = 5 # maximaler Nichtzentralitätsparameter
d_res = 50 # Auflösung Nichtzentralitätsparameter
d = seq(d_min, d_max, len = d_res) # Nichtzentralitätsparameterraum
n_min = 1 # minimaler Stichprobenumfang
n_max = 30 # maximaler Stichprobenumfang
n_res = 50 # Auflösung Stichprobenumfang
n = seq(n_min,n_max, len = n_res) # maximaler Stichprobenumfang
pi = matrix(rep(NaN, d_res*n_res), nrow = d_res) # Powerfunktionsarray
for(i in 1:d_res){ # Nichtzentralitätsparameteriterationen
for(j in 1:n_res){ # Stichprobenumfangiterationen
k_alpha_0 = qt(1 - alpha_0/2, n[j]-1) # kritischer Wert
pi[i,j] = 1-pt(k_alpha_0, n[j]-1, d[i])+pt(-k_alpha_0, n[j]-1, d[i]) # Auswertung der Powerfunktion
}
}Wir visualisieren die Abhängigkeit der Powerfunktion des zweiseitigen Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese vom Nichtzentralitätsparameter und Stichprobenumfang in Abbildung 33.6 und Abbildung 33.7. Generell steigt die Powerfunktion des betrachteten Tests mit positiver oder negativer Abweichung des Nichtzentralitätsparameters vom Nullhypothesenszenario \(d = 0\) und steigendem Stichprobenumfang \(n\) monoton. Je nach Wahl des Signifikanzlevel erfolgt dieser Anstieg steiler bzw. weniger steil.
Praktische Durchführung
Vor dem Hintergrund der in den bisherigen Abschnitten diskutierten Theorie des zweiseitigen Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese ergibt folgendes routiniertes Durchführen des Tests: Man nimmt an, dass ein vorliegender univariater Datensatz eine Realisierung des Frequentistischen Inferenzmodells \(y_1,...,y_n \sim N(\mu,\sigma^2)\) des Einstichproben-T-Tests mit wahren, aber unbekannten, Parametern \(\mu\) und \(\sigma^2 > 0\) ist. Man nimmt ferner an, dass man entscheiden muss, ob für einen gewählten Nullhypothesenparameter \(\mu_0\) eher die Nullhypothese \(H_0 : \mu = \mu_0\) oder die Alternativhypothese \(H_1: \mu \neq \mu_0\) zutrifft. Um den Testumfang über viele Wiederholungen dieser Testprozedur zu kontrollieren, wählt ein Signifikanzlevel \(\alpha_0\) und bestimmt den zugehörigen kritischen Wert \(k_{\alpha_0}\), sodass zum Beispiel bei einem Stichprobenumfang von \(n=12\) und der Wahl von \(\alpha_0 := 0.05\) ein kritischer Wert von \(k_{0.05} = 2.20\) gewählt wird. Anhand des Stichprobenumfangs \(n\), des Nullhypothesenparameters \(\mu_0\), des Stichprobenmittels \(\bar{y}\) und der Stichprobenstandardabweichung \(s\) berechnet man sodann den Wert der Einstichproben-T-Test-Statistik \[\begin{equation}
t := \sqrt{n}\left(\frac{\bar{y} - \mu_0}{s}\right).
\end{equation}\] Wenn dieses für den vorliegenden Datensatz so bestimmte \(t\) größer als \(k_{\alpha_0}\) ist oder wenn \(t\) kleiner als \(-k_{\alpha_0}\) ist, lehnt man die Nullhypothese ab. Andernfalls lehnt man die Nullhypothese nicht ab. Die hier entwickelte Theorie garantiert dann, dass man im langfristigen Mittel in höchstens \(\alpha_0 \cdot 100\) von \(100\) Fällen die Nullhypothese fälschlicherweise ablehnt. Weiterhin bestimmt man basierend auf dem vorliegenden Wert der Einstichproben-T-Test-Statistik den zugehörigen p-Wert durch \[\begin{equation}
\mbox{p-Wert} = 2(1 - \Psi(\vert t \vert;n-1))
\end{equation}\] Folgender R Code demonstriert dieses Vorgehen bei Annahme eines vorliegenden Datenvektors y der Länge n.
n = length(y) # Stichprobenumfang
mu_0 = 0 # Nullhypothesenparameter
alpha_0 = 0.05 # Signifikanzlevel
k_alpha_0 = qt(1-alpha_0/2,n-1) # kritischer Wert
Tee = sqrt(n)*((mean(y) - mu_0)/sd(y)) # Einstichproben-T-Test-Statistik
if(abs(Tee) > k_alpha_0){phi = 1} else {phi = 0} # Testauswertung
p = 2*(1 - pt(abs(Tee),n-1)) # p-Wert EvaluationWill man eine Poweranalyse zur Optimierung des Stichprobenumfangs durchführen, so gilt natürlich zunächst grundsätzlich, dass mit steigendem Stichprobenumfang die Powerfunktion des Tests ansteigt. Vor dem Gesichtspunkt der Power des Tests ist ein größerer Stichprobenumfang also immer besser als ein kleinerer Stichprobenumfang. Allerdings bleiben dabei mögliche Kosten für die Erhöhung des Stichprobenumfangs, wie zum Beispiel mögliche Risiken für die Studienteilnehmer:innen, unberücksichtigt. Weiterhin ist der Wert, den die Powerfunktion bei einem gewählten Stichprobenumfang annimmt, immer von den wahren, aber unbekannten, Parameterwerten \(\mu\) und \(\sigma\), die in den Wert des Nichtzentralitätsparameters \(d\) einfließen, abhängig. Würde man diese Werte in einem gegebenen Anwendungskontext schon sehr genau kennen, so würde man vermutlich keine Studie durchführen. Generell wird im Rahmen der Studienplanung deshalb folgendes Vorgehen favorisiert. Zunächst entscheidet man sich für ein Signifikanzlevel \(\alpha_0\) zur Kontrolle des Testumfangs und evaluiert die Powerfunktion. Man überlegt sich dann einen Nichtzentralitätswert \(d^*\), den man mit einer Power von mindestens \(\beta\) detektieren möchte, wobei ein konventioneller Wert \(\beta = 0.8\) ist. Man wertet dann die für einen Powerfunktionswert \[\begin{equation} \pi(d = d^*,n) = \beta \end{equation}\] nötige Stichprobengröße aus. Aufgrund der Monotonie der Powerfunktion des zweiseitigen Einstichproben-T-Tests mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese im Bereich nicht-negativer Nichtzentralitätsparameter ist dann gewährleistet, dass die Power des Tests für Nichtzentralitätsparameter, die größer als \(d^*\) sind, größer oder gleich \(\beta\) sind. Folgender R Code implementiert dieses Vorgehen zur Optimierung des Stichprobenumfangs und Abbildung 33.8 visualisiert es.
# Powerfunktionsbasierte Stichprobenumfangsoptimierung
alpha_0 = 0.05 # Signifikanzlevel
beta = 0.8 # gewünschter Powerfunktionswert
d_stern = 3 # fester Nichtzentralitätsparameter
n_min = 2 # minimal betrachteter Stichprobenumfang
n_max = 20 # maximal betrachteter Stichprobenumfang
n_res = 1e2 # Auflösung des Stichprobenumfangraums
n = seq(n_min,n_max, len = n_res) # Stichprobenumfangraum
k_alpha_0 = qt(1-alpha_0/2, n-1) # kritische Werte in Abhängigkeit vom Stichprobenumfang
pi_n = 1-pt(k_alpha_0, n-1, d_stern)+pt(-k_alpha_0, n-1, d_stern) # Powerfunktion bei festem Nichtzentralitätsparameter
i = 1 # Indexinitialisierung
n_min = NaN # minimales n Initialisierung
while(pi_n[i] < beta){ # Solange \pi(d*,n) < \beta
n_min = n[i] # Aufnahme des minimal nötigen ns
i = i + 1} # und Erhöhung des Indexes
cat("Minimal nötiges n =", ceiling(n_min)) # AusgabeMinimal nötiges n = 16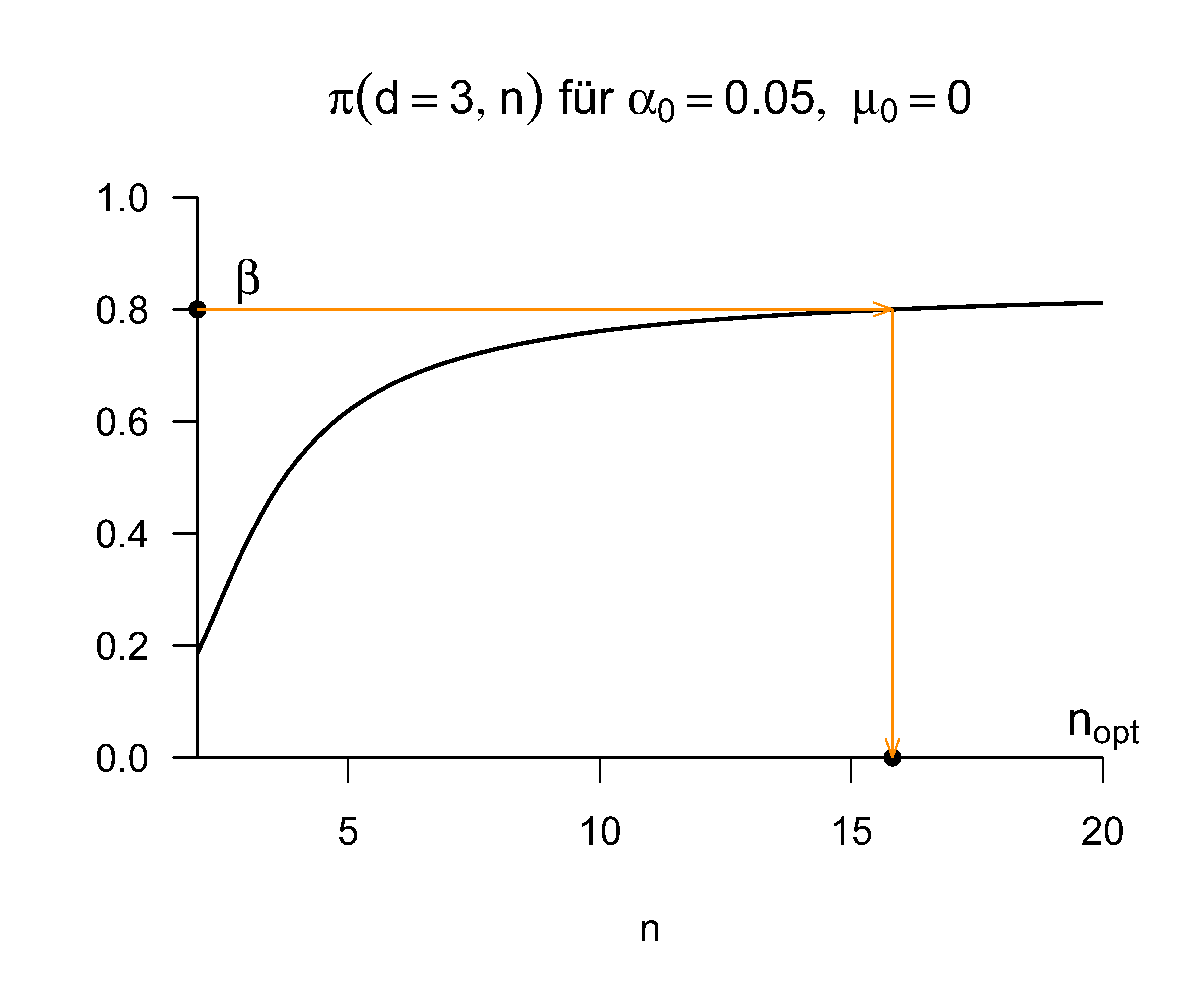
Anwendungsbeispiel
Abschließend wollen wir oben skizziertes Vorgehen noch an Beispiel 30.5 demonstrieren. Inhaltlich entspricht in diesem Fall die einfache Nullhypothese \(H_0 : \mu = 0\) der Hypothese, dass die Therapie keinen Effekt auf BDI-II Reduktionsscores hat. Die zusammengesetzte Alternativhypothese \(H_1 : \mu \neq 0\) entspricht der Hypothese, dass die Therapie einen systematischen von null verschiedenen Effekt auf BDI-II Reduktionsscores hat. Untenstehender R Code wendet das oben demonstrierte Verfahren zur Evaluation der Hypothesen auf den Prä-Post-Therapie BDI-II Reduktionsscore Datensatz von \(n = 12\) Patient:innen an und evaluiert darüber hinaus zusätzlich das 95%-Konfidenzintervall für den Erwartungswertparameter.
D = read.csv("./_data/bdi-ii-datensatz.csv") # Datensatzeinlesen
y = D$dBDI # Datenauswahl
n = length(y) # Stichprobenumfang
mu_hat = mean(y) # Erwartungswertparameterschätzer
delta = 0.95 # Konfidenzlevel
t_delta = qt((1+delta)/2,n-1) # \Psi^-1((\delta + 1)/2, n-1)
G_u = mean(y) - (sd(y)/sqrt(n))*t_delta # untere Konfidenzintervallgrenze
G_o = mean(y) + (sd(y)/sqrt(n))*t_delta # obere Konfidenzintervallgrenze
mu_0 = 0 # Nullhypothesenparameter, hier \mu = \mu_0
alpha_0 = 0.05 # Signifikanzlevel
k_alpha_0 = qt(1-alpha_0/2,n-1) # kritischer Wert
Tee = sqrt(n)*((mean(y) - mu_0)/sd(y)) # T-Teststatistik
if(abs(Tee) > k_alpha_0){phi = 1} else {phi = 0} # Test 1_{\vert t \vert >= k_alpha_0}
p = 2*(1 - pt(abs(Tee),n-1)) # p-WertParameterschätzwert = 3.17
95%-Konfidenzintervall = 0.81 5.53
Signifikanzlevel = 0.05
Kritischer Wert = 2.2
Teststatistik = 2.95
Testwert = 1
p-Wert = 0.01Die gleiche Analyse kann auch mit der in R implementierten Funktion t.test() durchgeführt werden, die Syntax zu ihrer Benutzung und die Formatierung der durch sie bestimmten Ergebnisse finden sich untensstehend.
One Sample t-test
data: y
t = 2.9542, df = 11, p-value = 0.01311
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.8074098 5.5259235
sample estimates:
mean of x
3.166667 Im vorliegenden Fall würde man die Nullhypothese also bei einem Signifikanzlevel von \(\alpha_0 = 0.05\) ablehnen. Ob die Nullhypothese allerdings im vorliegenden Fall zutrifft oder nicht bleibt, wie der wahre, aber unbekannte, Erwartungswertparameter unbekannt. Im langfristigen Mittel jedoch lehnt man basierend auf den oben beschriebenen Annahmen die Nullhypothese in nur 5 von 100 Fällen fälschlicherweise ab.
33.4 Konfidenzintervalle und Hypothesentests
In diesem Abschnitt untersuchen wir, inwieweit Konfidenzintervalle und Hypothesentests als äquivalent angesehen werden können. Wir wollen dabei von dem Szenario eines Konfidenzintervalls ausgehen.
Theorem 33.5 (Dualität von Konfidenzintervallen und Hypothesentests) Es sei \(y\) die Stichprobe eines Frequentistischen Inferenzmodells mit Ergebnisraum \(\mathcal{Y}\) und Parameterraum \(\Theta\). Weiterhin sei für ein \(\delta \in \,]0,1[\) mit \([G_u(y), G_o(y)]\) ein \(\delta\)-Konfidenzintervall für den wahren, aber unbekannten, Parameter \(\theta \in \Theta\) definiert. Dann gilt, dass der Hypothesentest definiert durch \[\begin{equation} \phi_\theta : \mathcal{Y} \to \{0,1\}, y \mapsto \phi(y) := \begin{cases} 0, & [G_u(y), G_o(y)] \ni \theta_0 \\ 1, & [G_u(y), G_o(y)] \,\not\ni\, \theta_0 \\ \end{cases} \end{equation}\] ein Hypothesentest vom Signifikanzlevel \(\alpha_0 = 1 - \delta\) für die Hypothesen \[\begin{equation} \Theta_0 := \{\theta_0\} \mbox{ und } \Theta_1 := \Theta \setminus \{\theta_0\}. \end{equation}\]
Beweis. Aufgrund der einfachen Nullhypothese und somit \(\alpha_0 = \alpha\) folgt \[\begin{equation} \alpha_0 = \alpha = \mathbb{P}_{\theta_0}(\phi(y) = 1) = \mathbb{P}_{\theta_0}([G_u(y), G_o(y)] \,\not\ni\, \theta_0) = 1 - \mathbb{P}_{\theta_0}([G_u(y), G_o(y)] \ni \theta_0) = 1 - \delta. \end{equation}\]
Theorem 33.5 besagt also, dass man mithilfe eines \(\delta\)-Konfidenzintervalls einen Hypothesentest mit Signifikanzlevel \(\alpha_0 = 1 -\delta\) mit einfacher Nullhypothese und zusammengesetzter Alternativhypothese konstruieren kann. Dazu ist bei diesem Test die Nullhypothese \(\theta = \theta_0\) jeweils abzulehnen, wenn das Konfidenzintervall den Nullhypothesenparameter \(\theta_0\) nicht überdeckt. Anhand folgenden Theorems wollen wir Theorem 33.5 für das in Kapitel 32.2 betrachtete Konfidenzintervall für den Erwartungswertparameter des Normalverteilungsmodells und den in Kapitel 33.3.1 betrachteten Einstichproben-T-Test konkretisieren.
Theorem 33.6 (Dualität von Erwartungswertkonfidenzintervall und Einstichproben-T-Test) Gegeben sei das Normalverteilungsmodell und es sei \[\begin{equation} \kappa := \left[\bar{y} - \frac{S}{\sqrt{n}}t_\delta,\bar{y} + \frac{S}{\sqrt{n}}t_\delta\right]. \end{equation}\] das mithilfe von \[\begin{equation} t_\delta := \Psi^{-1}\left(\frac{1 + \delta}{2}; n-1 \right) \end{equation}\] in Theorem 32.2 definierte \(\delta\)-Konfidenzintervall für den Erwartungswertparameter. Dann ist mit Theorem 33.5 der Test \[\begin{equation} \phi : \mathcal{Y} \to \{0,1\}, y \mapsto \phi(y) := \begin{cases} 0, & \left[\bar{y} - \frac{S}{\sqrt{n}}t_\delta,\bar{y} + \frac{S}{\sqrt{n}}t_\delta\right] \ni \mu_0 \\ 1, &\left[\bar{y} - \frac{S}{\sqrt{n}}t_\delta,\bar{y} + \frac{S}{\sqrt{n}}t_\delta\right] \,\not\ni\, \mu_0 \\ \end{cases} \end{equation}\] ein Test der einfachen Nullhypothese \(H_0: \mu = \mu_0\) und der zusammengesetzten Alternativhypothese \(H_1: \mu \neq \mu_0\) mit Signifikanzlevel \(\alpha_0 = 1 - \delta\).
Beweis. Es gilt \[\begin{align} \begin{split} \mathbb{P}_{\mu_0}\left(\phi(y) = 1 \right) = 1 - \mathbb{P}_{\mu_0}\left(\phi(y) = 0 \right) = 1 - \mathbb{P}_{\mu_0}\left( \left[\bar{y} - \frac{S}{\sqrt{n}}t_\delta, \bar{y} + \frac{S}{\sqrt{n}}t_\delta\right] \ni \mu_0\right) = 1 - \delta. \end{split} \end{align}\]
Folgender R Code simuliert diesen Konfidenzintervall-basierten Hypothesentest bei Zutreffen der Nullhypothese und gibt Schätzungen für das Konfidenzlevel und das Signifikanzlevel über 100 Realisierungen einer Stichproben mit Stichprobenumfang \(n = 12\) mit wahren, aber unbekannten, Parametern \(\mu = 2\) und \(\sigma^2 = 1\) an.
n = 12 # Stichprobenumfang
mu = 2 # wahrer, aber unbekannter, Erwartungswertparameter
sigsqr = 1 # wahrer, aber unbekannter, Varianzparameter
delta = 0.95 # Konfidenzlevel
t_delta = qt((1+delta)/2, n-1) # \Psi^{-1}((\delta + 1)/2, n-1)
mu_0 = mu # Nullhypothesenparameter bei Zutreffen von H_0
set.seed(1) # random number generator seed
ns = 1e2 # Anzahl Simulationen
y_bar = rep(NaN,ns) # Stichprobenmittelarray
s = rep(NaN,ns) # Stichprobenstandardabweichungarray
kappa = matrix(rep(NaN,2*ns), ncol = 2) # Konfidenzintervallarray
kfn = rep(NaN,ns) # Überdeckungsindikatorarray
phi = rep(NaN,ns) # Testarray
for(i in 1:ns){ # Simulationsiterationen
y = rnorm(n,mu_0,sqrt(sigsqr)) # Stichprobenrealisierung
y_bar[i] = mean(y) # Stichprobenmittel
s[i] = sd(y) # Stichprobenstandardabweichung
kappa[i,1] = y_bar[i] - (s[i]/sqrt(n))*t_delta # untere Konfidenzintervallgrenze
kappa[i,2] = y_bar[i] + (s[i]/sqrt(n))*t_delta # obere Konfidenzintervallgrenze
if(kappa[i,1] <= mu_0 & mu_0 <= kappa[i,2]){
kfn[i] = 1} else{kfn[i] = 0} # Überdeckungsindikatorevaluation
if(kappa[i,1] <= mu_0 & mu_0 <= kappa[i,2]){
phi[i] = 0} else{phi[i] = 1}} # TestevaluationGeschätztes Konfidenzniveau = 0.96
Geschätzter Testumfang = 0.04Wir visualisieren die Ergebnisse dieser Simulation in Abbildung 33.9.
33.5 Literaturhinweise
Die hier präsentierte Theorie der Hypothesentests geht im Wesentlichen auf Neyman & Pearson (1928) und Neyman & Pearson (1933) zurück. Gigerenzer (2004) und Lehmann (2011) geben historische Einordnungen der Genese des Hypothesentestbegriffs.
Selbstkontrollfragen
- Erläutern Sie die grundlegende Logik frequentistischer Hypothesentests.
- Geben Sie die Definition der Begriffe der Testhypothesen und des Testszenario wieder.
- Geben Sie die Definition der Begriffe der einfachen und zusammengesetzten Testhypothesen wieder.
- Geben Sie die Definition der Begriffe einseitigen und zweiseitigen Testhypothesen wieder.
- Geben Sie die Definition des Begriff des Tests wieder.
- Geben Sie die Definition des Begriffs des Standardtests wieder.
- Geben Sie die Definition des Begriffs des kritischen Bereichs wieder.
- Geben Sie die Definition des Begriffs des Ablehungsbereichs wieder
- Geben Sie die Definition des Begriffs des kritischen Wert-basierten Tests wieder.
- Geben Sie die Definition der Begriffe der richtigen Testentscheidungen und der Testfehler wieder.
- Geben Sie die Definition des Begriffs der Testgütefunktion wieder.
- Erläutern Sie die Bedeutung der Testgütefunktion für die Konstruktion von Hypothesentests.
- Geben Sie die Definition des Begriffs des Level-\(\alpha_0\)-Tests wieder.
- Geben Sie die Definition des Begriffs des Signifikanzlevel \(\alpha_0\) wieder
- Geben Sie die Definition des Begriffs des Testumfangs \(\alpha\) wieder.
- Geben Sie die Definition des Begriffs des p-Werts wieder.
Lösungen
- Siehe einführende Bemerkungen dieses Kapitels.
- Siehe Definition 33.1.
- Siehe Definition 33.2.
- Siehe Definition 33.3.
- Siehe Definition 33.4.
- Siehe Definition 33.5.
- Siehe Definition 33.6.
- Siehe Definition 33.7.
- Siehe Definition 33.8.
- Siehe Definition 33.9.
- Siehe Definition 33.10.
- Siehe Erläuterungen zu Definition 33.10.
- Siehe Definition 33.11.
- Siehe Definition 33.11.
- Siehe Definition 33.11.
- Siehe Definition 33.12.
Amrhein, V., & Greenland, S. (2018). Remove, Rather than Redefine, Statistical Significance. Nature Human Behaviour, 2(1), 4–4. https://doi.org/10.1038/s41562-017-0224-0
Gigerenzer, G. (2004). Mindless Statistics. The Journal of Socio-Economics, 33(5), 587–606. https://doi.org/10.1016/j.socec.2004.09.033
Kochenderfer, M. J., Wheeler, T. A., & Wray, K. H. (2022). Algorithms for Decision Making. The MIT Press.
Lehmann, E. L. (2011). Fisher, Neyman, and the Creation of Classical Statistics. Springer New York. https://doi.org/10.1007/978-1-4419-9500-1
McShane, B. B., Gal, D., Gelman, A., Robert, C., & Tackett, J. L. (2019). Abandon Statistical Significance. The American Statistician, 73(sup1), 235–245. https://doi.org/10.1080/00031305.2018.1527253
Neyman, J., & Pearson, E. S. (1928). On the Use and Interpretation of Certain Test Criteria for Purposes of Statistical Inference: Part I. Biometrika, 20A(1/2), 175. https://doi.org/10.2307/2331945
Neyman, J., & Pearson, E. S. (1933). On the Problem of the Most Efficient Tests of Statistical Hypotheses. Phil. Trans. R. Soc. Lond. A, 231(694-706), 289–337.
Pratt, J., Raiffa, H., & Schlaifer, R. (1995). Statistical Decision Theory. MIT Press.
Puterman, M. (1994). Markov Decision Processes: Discrete Stochastic Dynamic Programming. John Wiley & Sons.
Wasserstein, R. L., Schirm, A. L., & Lazar, N. A. (2019). Moving to a World Beyond „ p \(<\) 0.05“. The American Statistician, 73(sup1), 1–19. https://doi.org/10.1080/00031305.2019.1583913